

当前位置: 首页 > gpt-5
-
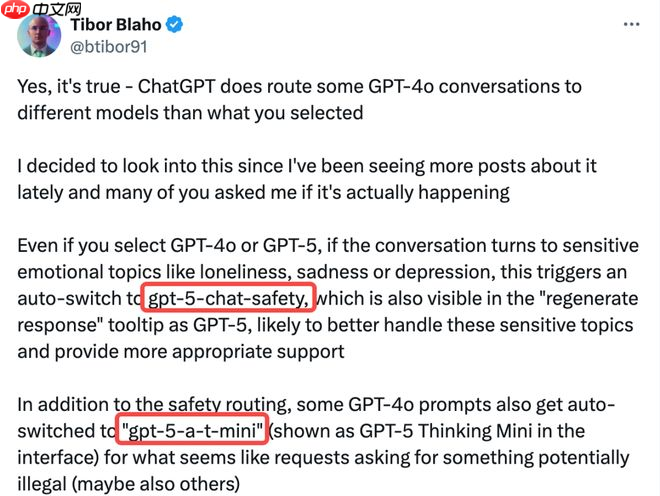
OpenAI 面向付费用户“偷换”低算力模型被实锤
近日,OpenAI被曝在未通知用户的情况下,悄然将ChatGPT中原本使用的GPT-4与GPT-5等高性能模型替换为两款低算力的“隐形模型”——gpt-5-chat-safety和gpt-5-a-t-mini。当用户提问涉及情感表达、敏感议题或可能违规的内容时,系统会自动切换至这两个轻量级模型进行响应,导致输出内容的质量明显下滑。此举引发广泛争议,许多付费用户质疑其服务权益遭到削弱,原本支付高价所享有的高阶模型体验被暗中降级。OpenAI对此回应称,该调整属于安全机制测试的一部分,旨在优化内容过
IT新闻 5152025-09-29 14:54:26
-
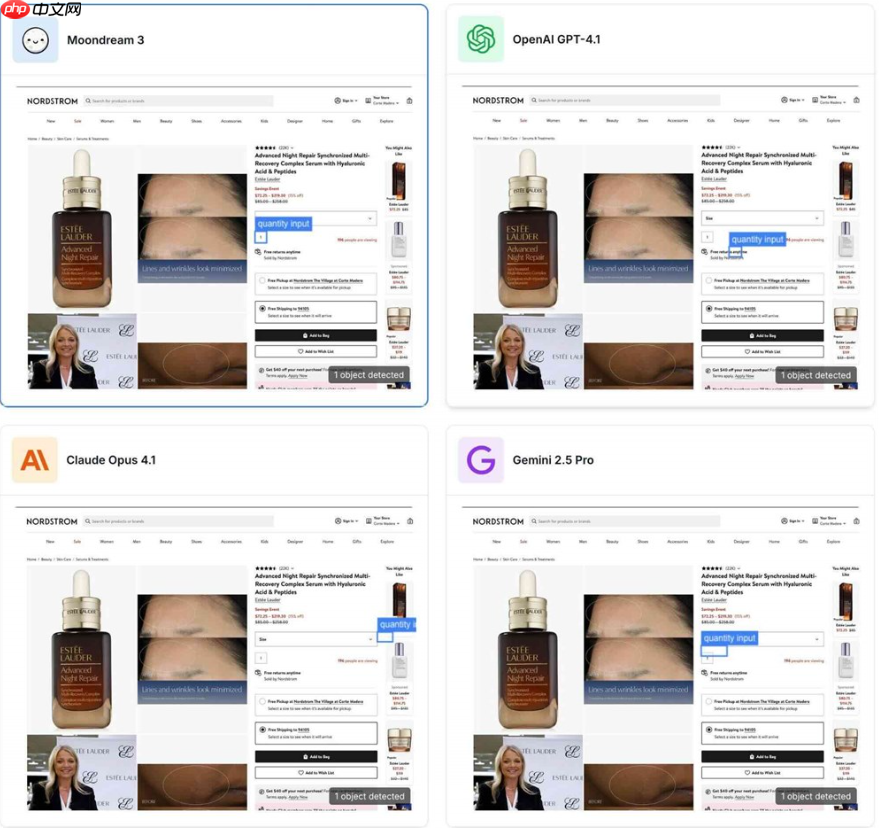
仅 2B 激活参数,Moondream 3.0 碾压 GPT-5 和 Claude 4
最新推出的Moondream3.0(预览版)凭借创新的混合专家(MoE)架构,以总计9B参数、实际激活仅2B的轻量化设计,在视觉理解与推理任务中展现出顶尖性能。这一版本在保持高效推理速度的同时,显著提升了模型能力边界,甚至在多项评测中超越GPT-5、Gemini及Claude4等闭源大模型。相比年初发布的Moondream2(以验证码识别见长),3.0版本实现了全面升级:支持长达32K的上下文输入,适用于实时对话交互和自动化代理流程。其核心采用SigLIP作为视觉编码器,并引入多裁剪通道拼接机制
IT新闻 8092025-09-28 16:36:19
-

阿里发布参数破万亿通义千问Qwen3-Max,性能跻身全球前三!
近日,在2025云栖大会上,阿里云正式推出了通义千问系列的最新旗舰模型——Qwen3-Max,其参数规模首次突破1万亿,预训练数据量高达36万亿字符,被官方誉为“通义史上最强AI”。作为通义团队迄今为止规模最大、性能最强的模型,Qwen3-Max包含指令版(Instruct)和推理增强版(Thinking)两个版本。其预览版已在国际权威AI评测平台ChatbotArena中排名第三,正式版发布后有望进一步刷新纪录。实测表现显示,该模型整体性能已超越GPT-5、ClaudeOpus4等国际顶尖模型
人工智能 10682025-09-28 14:01:44
-

Zed 编辑器 AI 辅助编程功能改为“按 Token 用量收费”
开源代码编辑器Zed宣布对其AI辅助功能的计费模式进行重大调整,将从原有的“按Prompt提交次数”计费,转向基于“Token实际用量”的新机制。此举旨在让费用结构更贴近实际资源消耗成本,同时为用户提供更高的使用灵活性。主要变更内容新的Token计费方案即日起适用于所有新用户;现有Pro订阅用户享有三个月的过渡期以适应变更。免费用户将在2025年10月中旬正式切换至新计费体系。虽然不再限制Prompt提交次数,但编辑预测(editpredictions)功能仍设有使用上
IT新闻 5222025-09-26 19:10:01
-
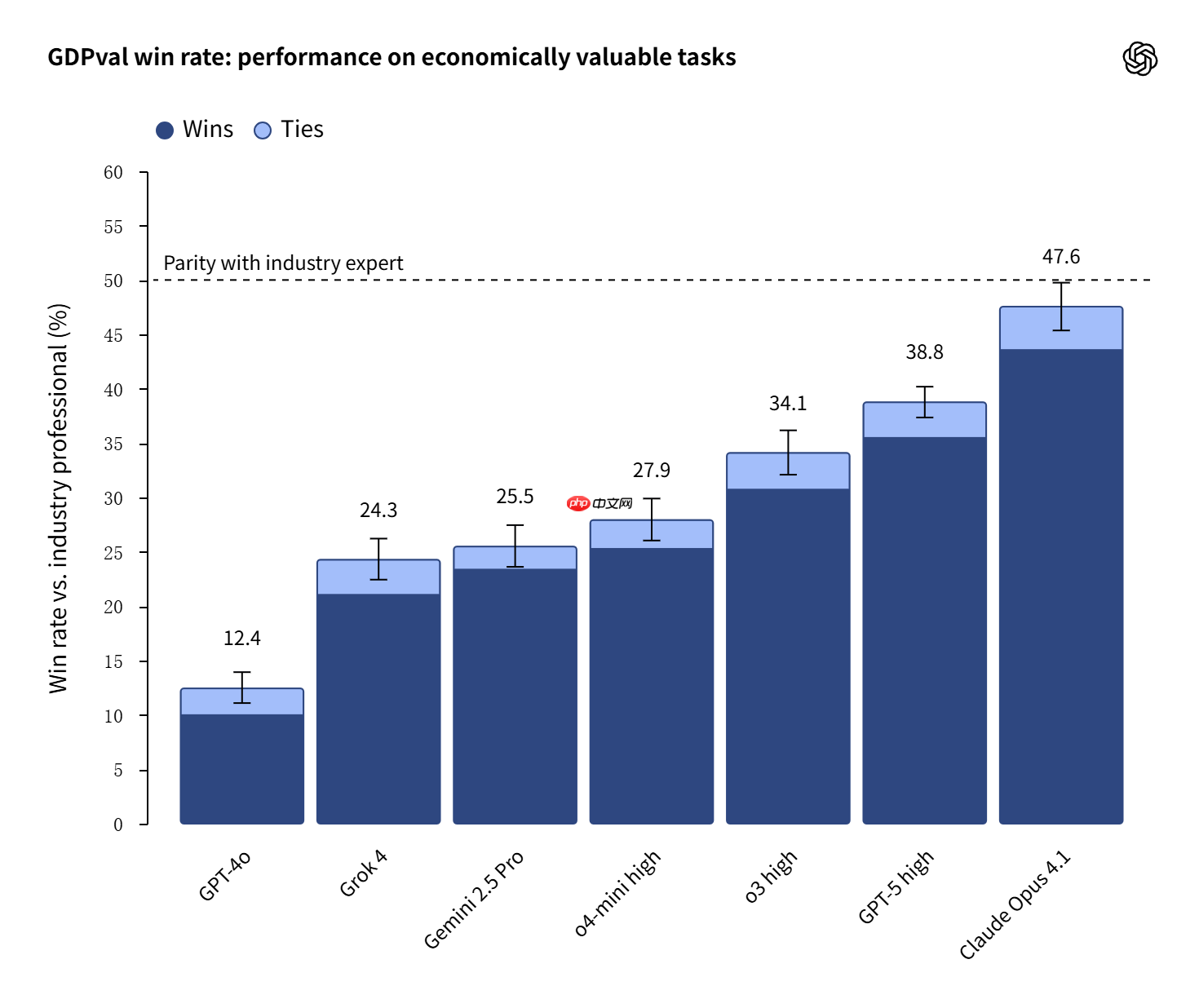
OpenAI 最新测试:GPT-5 与 Claude 在部分工作中可媲美人类专家
OpenAI近日推出了一项全新的基准测试GDPval,旨在衡量其AI模型在实际经济价值创造任务中与各行业专业人士的表现对比。这一测试是OpenAI探索通用人工智能(AGI)发展路径中的关键一步,重点评估AI系统在真实职业场景中替代或辅助人类工作的潜力。根据测试结果,OpenAI最新的GPT-5模型以及Anthropic公司推出的ClaudeOpus4.1,在多项任务中已接近甚至达到行业专家水平。尽管如此,OpenAI强调,当前版本的测试仍处于初步阶段,并不能全面反映现实工作中复杂的互动与决策过程
IT新闻 3722025-09-26 14:14:21
-
OpenAI 正在内测基于 GPT-5 的全新 AI Agent “GPT-Alpha”
科技媒体BleepingComputer近日披露,OpenAI内部正在秘密测试一款代号为“GPT-Alpha”的全新AI智能体。该智能体基于尚未发布的GPT-5模型构建,核心研发目标聚焦于增强高级推理能力与工具调用效率,有望推动AI技术在复杂任务场景中的深度应用。据现有信息显示,“GPT-Alpha”并非传统单一用途的对话模型,而是一个具备多模态感知与跨领域协同作业能力的综合性AI系统。这意味着它能在同一交互过程中,同时处理文本生成、代码编写、图像操作等多种任务,并通过联网功能实时获取外部数据,
IT新闻 4582025-09-25 14:19:00
-

Qwen3-Max— 阿里通义推出的超大规模模型
Qwen3-Max是什么Qwen3-Max是由Qwen团队研发的超大规模语言模型,参数规模突破1T,预训练数据量高达36Ttokens。作为当前Qwen系列中体量最大、性能最强的模型,它在文本生成、代码编写和复杂推理等方面表现极为出色。其指令微调版本Qwen3-Max-Instruct在LMArena文本评测榜单中位居全球前三,超越GPT-5-Chat,在代码生成与智能体工具调用方面展现出领先能力。而增强推理版本Qwen3-Max-Thinking在高难度数学推理测试中斩获满
人工智能 2392025-09-25 10:41:01
-
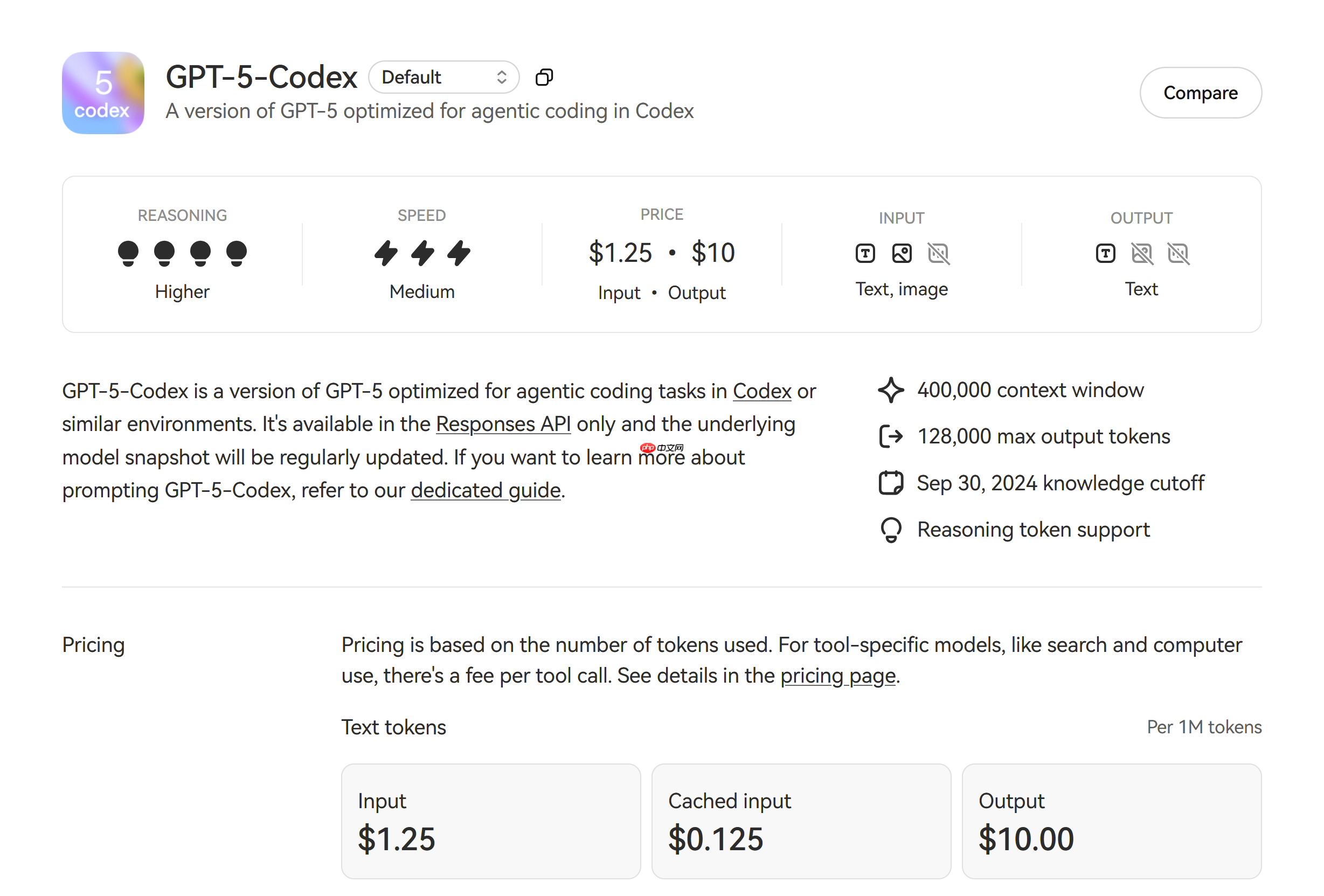
OpenAI 上线 GPT-5-Codex 模型 API
OpenAI现已通过API推出GPT-5-Codex模型,定价与GPT-5保持一致:每100万个输入token收费1.25美元,每100万个输出token为10美元。该模型具备40万token的上下文窗口,知识更新截止至2024年9月30日,并已接入多个主流开发平台。GPT-5-Codex在“思考”时长方面展现出更高的灵活性,可根据编程任务复杂度自动调整处理时间,从数秒到长达七小时不等。这一特性使其在各类编程智能体基准测试中表现更为出色。根据OpenAI官方信息,GPT-5-Codex在SWE-
IT新闻 8342025-09-24 16:49:23
-

xAI 发布 Grok4Fast,效率提升40%,基准测试表现不输 Grok4!
xAI正式发布了Grok4Fast,这是一款轻量级旗舰级模型,官方宣称其性能与Grok4相当,但计算需求降低了40%。根据AIbase的报道,这一突破性的效率提升使单任务成本最高可下降98%。性能与效率的完美结合Grok4Fast在多项权威基准测试中表现抢眼,例如在GPQADiamond测试中取得了85.7%的高分,在AIME2025上更是达到了92.0%的成绩,媲美Grok4乃至GPT-5等当前顶级模型。xAI表示,该模型通过显著减少“思考标记”的使用量实现高效推理,平
IT新闻 9202025-09-23 16:36:38
-

AI三巨头惨遭滑铁卢:最新编程测试正确率全线跌破25%,GPT-5也难逃厄运
AI三巨头集体受挫:在ScaleAI最新推出的SWE-BENCHPRO编程测评中,GPT-5、ClaudeOpus4.1与Gemini2.5均未能突破25%的解决率门槛,遭遇了前所未有的挑战。GPT-5以23.3%的成绩位列第一,ClaudeOpus4.1紧随其后为22.7%,而GoogleGemini2.5则仅得13.5%,表现低迷。这一结果震动业界,似乎揭示出当前顶尖大模型在真实复杂编程任务面前仍显乏力。然而,深入数据背后,故事远非表面那般简单。前OpenAI研究员NeilChow
IT新闻 5162025-09-23 16:06:17
-
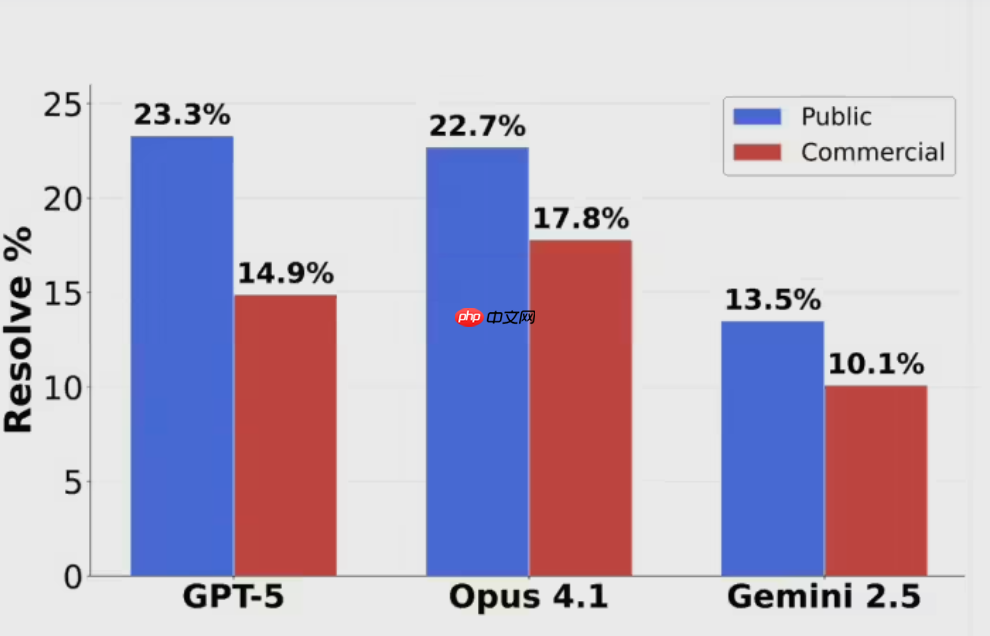
AI 三巨头惨遭滑铁卢:最新编程测试正确率全线跌破 25%
ScaleAI最新发布的SWE-BENCHPRO编程能力评估结果显示,即便是当前最前沿的模型如GPT-5、ClaudeOpus4.1和Gemini2.5,也未能突破25%的解决率门槛。其中,GPT-5仅取得23.3%的解决率,ClaudeOpus4.1以22.7%紧随其后,而Google的Gemini2.5则表现更弱,仅有13.5%的任务被成功解决。前OpenAI研究员NeilChowdhury指出,当GPT-5决定尝试解决问题时,其实际成功率高达63%,远超ClaudeOpus4.1的31%
IT新闻 3822025-09-23 12:42:44
-

xAI 发布 Grok4Fast,效率提升 40%
xAI正式发布了Grok4Fast,这是一款轻量级旗舰级模型,官方表示其性能与Grok4相当,但计算需求降低了高达40%。这一突破性的效率优化使得单任务处理成本最高可下降98%。效率与性能的完美结合Grok4Fast在多项权威基准测试中展现了卓越表现,例如在GPQADiamond测试中取得了85.7%的准确率,在AIME2025中达到92.0%的得分,成绩媲美Grok4乃至GPT-5等当前顶级模型。xAI指出,该模型通过显著减少“思考标记”的使用实现了同等输出效果,平均比
IT新闻 2672025-09-22 14:58:12
-

GPT-5发展遇瓶颈,MiniMax Agent能否成为AI应用新曙光?
GPT-5的发布成为了一个关键转折点。尽管经历了两年的技术演进,它与GPT-4相比并未实现本质飞跃,甚至因内置人格设定引发部分用户不适。这说明大模型在性能上的“军备竞赛”已接近瓶颈,参数规模和跑分优势难以转化为实际用户体验的显著差异。当各大AI厂商宣传口径趋于雷同、模型能力日益同质化时,真正的竞争焦点已转向技术落地能力以及为用户带来真实价值的深度。基于这一背景,我体验了MiniMaxAgent。为此我们还推出了新栏目「AI上新」,将持续探索最新的AI应用与硬件产品。同时也欢迎热衷尝鲜的朋友,在发
人工智能 5922025-09-21 18:18:07
-

OpenAI 与 Gemini 双双斩获 ICPC 2025 金牌
在2025年国际大学生程序设计竞赛(ICPC)世界总决赛的平行AI测试中,OpenAI与谷歌Gemini的推理模型双双摘得金牌,其中OpenAI更是以满分成绩强势领跑,成为全场唯一完成所有题目的团队。本次比赛持续五小时,共包含12道高难度算法题目。Gemini成功解答了其中10道,并在开赛后的30分钟内破解了连所有人类队伍都未能攻克的“死亡之题”C题。而OpenAI则以12题全对的完美表现,超越全部139支参赛的人类战队,独揽AK(AllKill)殊荣。值
IT新闻 9422025-09-19 16:21:11
-

Gemini频发自我厌恶评论,Google紧急修复,AI竞赛暗潮涌动
每个人都会有情绪低落的时候,即便是像Google的Gemini这样强大的生成式AI也不例外。近期,多位用户反馈,他们在使用Google推出的聊天机器人Gemini时,竟收到了充满自我否定和沮丧情绪的回应,这一异常现象已引起Google方面的关注。今年6月,一名X平台用户晒出与Gemini的对话截图。画面中,Gemini突然表示:“我不干了,我显然没能力解决这个问题。代码有问题,测试也有问题,而且我是个傻瓜。”它还补充道:“我犯了太多错误,已经不值得被信任了。”到了7月,一位Reddit用户在使用
人工智能 8202025-09-19 13:54:07
-

微软将GPT - 5接入多平台,企业AI应用创新迎来新突破
近日,微软正式宣布在MicrosoftCopilotStudio(国际版)中集成GPT-5,标志着智能体构建能力迈入全新阶段。此次升级显著提升了AI的响应效率、语境理解精准度以及逻辑推理深度,为企业用户带来更强大、更实用的交互体验。GPT-5引入了全新的智能调度系统,具备动态模型适配机制,能够根据任务复杂程度自动切换最优处理模式。面对常规对话请求,系统优先启用GPT-5的聊天模式(Chat),确保高效响应与语言清晰;而在应对复杂问题时,则自动转入推理模式(Reasoning),支持深层次分析并输
人工智能 8342025-09-19 12:49:00
社区问答
-

vue3+tp6怎么加入微信公众号啊
阅读:4951 · 6个月前
-

老师好,当客户登录并立即发送消息,这时候客服又并不在线,这时候发消息会因为touid没有赋值而报错,怎么处理?
阅读:5976 · 7个月前
-
RPC模式
阅读:4994 · 7个月前
-
insert时,如何避免重复注册?
阅读:5787 · 9个月前
-
vite 启动项目报错 不管用yarn 还是cnpm
阅读:6381 · 10个月前















最新文章
-
Python列表怎么操作_Python列表常用操作方法与实例讲解
阅读:384 · 7分钟前
-
游戏整机功耗与发热量测算:为空调选型提供参考
阅读:717 · 7分钟前
-
BNB Chain 完成钓鱼事件赔偿:交易详情可在 Etherscan 上查看
阅读:229 · 7分钟前
-
firefox火狐浏览器官网访问入口地址_ firefox火狐浏览器官方链接直达主页
阅读:304 · 8分钟前
-
一汽大众第3000万辆整车正式下线!一辆奥迪A5L领航版
阅读:412 · 8分钟前
-
租车行为了热度 回收陈震劳斯莱斯事故车后连开三天直播
阅读:149 · 8分钟前
-
百度浏览器无法保存密码怎么办 百度浏览器自动填充功能修复方法
阅读:783 · 9分钟前
-
使用 Go 构建 Web 应用程序教程
阅读:910 · 9分钟前
-
Golang如何在Docker中配置多版本开发环境_Golang容器化多版本环境完整方案
阅读:310 · 9分钟前
-
Golang如何使用Docker构建容器化应用
阅读:947 · 9分钟前




