
 Web Front-end
JS Tutorial
Detailed explanation of commonly used classic algorithm examples in javascript_javascript skills
Web Front-end
JS Tutorial
Detailed explanation of commonly used classic algorithm examples in javascript_javascript skills
Detailed explanation of commonly used classic algorithm examples in javascript_javascript skills

The examples in this article describe common algorithms in JavaScript. Share it with everyone for your reference, the details are as follows:
Entry-level algorithm-Linear search-time complexity O(n)--equivalent to HelloWorld
in the algorithm world1 2 3 4 5 6 7 8 9 10 |
|
Binary search (also called half search) - suitable for sorted linear structures - time complexity O(logN)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
Bubble sort -- time complexity O(n^2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
Selection sort -- Time complexity O(n^2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
Insertion sort -- time complexity O(n^2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
String reversal -- time complexity O(logN)
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
A conclusion about stability ranking:
A simple sorting algorithm based on comparison, that is, a sorting algorithm with a time complexity of O(N^2), which can usually be considered to be a stable sorting
Other advanced sorting algorithms, such as merge sort, heap sort, bucket sort (usually the time complexity of such algorithms can be optimized to n*LogN), can usually be considered to be unstable sorting
Singly linked listimplementation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
|
About the selection of adjacency matrix and adjacency list :
Adjacency matrix and adjacency list are the basic storage methods of graphs,
In the case of sparse graph (that is, when the edges are far smaller than the vertices), it is more suitable to use adjacency list storage (relative to the matrix N*N, the adjacency list only stores edges and vertices with values, and does not store null values. More efficient storage)
In the case of dense graph (that is, in the case of remote vertices), it is more suitable to store it with an adjacency matrix (when there is a lot of data, you need to traverse it. If you use a linked list to store it, you have to jump around frequently. , lower efficiency)
Heap:
Almost complete binary tree: A binary tree except that one or several leaves at the rightmost position may be missing. In terms of physical storage, arrays can be used to store it. If the vertex of A[j] has left and right child nodes, then the left node is A[2j], the right node is A[2j 1], and the parent vertex of A[j] Stored in A[j/2]
Heap: itself is an almost complete binary tree, and the value of the parent node is not less than the value of the child node . Application scenarios: priority queue, finding the maximum or sub-maximum value; and inserting a new element into the priority queue.
Note: In all the heaps discussed below, it is agreed that the element at index 0 only takes place, and the valid elements start from subscript 1
According to the definition of heap, you can use the following code to test whether an array is a heap:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
Node adjustment siftUp
In some cases, if the value of an element in the heap changes (for example, after 10,8,9,7 becomes 10,8,9,20, 20 needs to be adjusted upward), it no longer meets the definition of the heap. , when you need to adjust upward, you can use the following code to achieve
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
The node is adjusted downward by siftDown (since there is an upward adjustment, there is naturally a downward adjustment)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
Add new element to the heap
1 2 3 4 5 6 7 8 |
|
Remove elements from the heap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
Heap sort :
This is a very clever sorting algorithm. The essence lies in making full use of the characteristics of the data structure "heap" (the first element must be the largest), and each element can be moved up or down with time retest. It is relatively low, only O(logN). In terms of space, there is no need to resort to additional storage space, just exchange elements within the array itself.
Things:
1. First swap the first element (i.e. the largest element) with the last element - the purpose is to sink the maximum value to the bottom and ignore it in the next round
2. After 1, the remaining elements are usually no longer a heap. At this time, just use siftDown to adjust the new first element downward. After the adjustment, the new maximum element will naturally rise to the position of the first element
3. Repeat 1 and 2, and the large elements will sink to the bottom one by one, and finally the entire array will be in order.
Time complexity analysis: Creating a heap requires O(n) cost, each siftDown cost is O(logN), and up to n-1 elements can be adjusted, so the total cost is O(N) (N-1)O(logN) , the final time complexity is O(NLogN)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
|
Regarding building a heap, if you understand the principle, you can also reverse the idea and do it in reverse
1 2 3 4 5 6 7 8 |
|
Search and merge disjoint sets
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
Induction method:
Let’s first look at the two recursive implementations of sorting
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
Recursive programs are usually easy to understand and the code is easy to implement. Let’s look at two small examples:
Find the maximum value from the array
1 2 3 4 5 6 7 8 9 10 11 12 |
|
There is an array that has been sorted in ascending order. Check whether there are two numbers in the array, and their sum is exactly x?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
递归程序虽然思路清晰,但通常效率不高,一般来讲,递归实现,都可以改写成非递归实现,上面的代码也可以写成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
递归并不总代表低效率,有些场景中,递归的效率反而更高,比如计算x的m次幂,常规算法,需要m次乘法运算,下面的算法,却将时间复杂度降到了O(logn)
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
当然,这其中并不光是递归的功劳,其效率的改进 主要依赖于一个数学常识: x^m = [x^(m/2)]^2,关于这个问题,还有一个思路很独特的非递归解法,巧妙的利用了二进制的特点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
再来看看经典的多项式求值问题:
给定一串实数An,An-1,...,A1,A0 和一个实数X,计算多项式Pn(x)的值
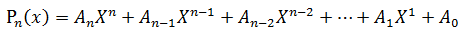
著名的Horner公式:
已经如何计算:
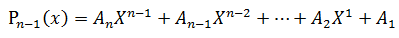
显然有:
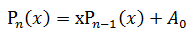
这样只需要 N次乘法+N次加法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
多数问题:
一个元素个数为n的数组,希望快速找出其中大于出现次数>n/2的元素(该元素也称为多数元素)。通常可用于选票系统,快速判定某个候选人的票数是否过半。最优算法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
以上算法基于这样一个结论:在原序列中去除两个不同的元素后,那么在原序列中的多数元素在新序列中还是多数元素
证明如下:
如果原序列的元素个数为n,多数元素出现的次数为x,则 x/n > 1/2
去掉二个不同的元素后,
a)如果去掉的元素中不包括多数元素,则新序列中 ,原先的多数元素个数/新序列元素总数 = x/(n-2) ,因为x/n > 1/2 ,所以 x/(n-2) 也必然>1/2
b)如果去掉的元素中包含多数元素,则新序列中 ,原先的多数元素个数/新序列元素总数 = (x-1)/(n-2) ,因为x/n > 1/2 =》 x>n/2 代入 (x-1)/(n-2) 中,
有 (x-1)/(n-2) > (n/2 -1)/(n-2) = 2(n-2)/(n-2) = 1/2
下一个问题:全排列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
分治法:
要点:将问题划分成二个子问题时,尽量让子问题的规模大致相等。这样才能最大程度的体现一分为二,将问题规模以对数折半缩小的优势。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
|
split算法的思想应用:
设A[1..n]是一个整数集,给出一算法重排数组A中元素,使得所有的负整数放到所有非负整数的左边,你的算法的运行时间应当为Θ(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
希望本文所述对大家JavaScript程序设计有所帮助。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
 Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
JavaScript tutorial: How to get HTTP status code, specific code examples are required. Preface: In web development, data interaction with the server is often involved. When communicating with the server, we often need to obtain the returned HTTP status code to determine whether the operation is successful, and perform corresponding processing based on different status codes. This article will teach you how to use JavaScript to obtain HTTP status codes and provide some practical code examples. Using XMLHttpRequest
 Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Written above & The author’s personal understanding is that in the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving. Head
