
 Technology peripherals
AI
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Technology peripherals
AI
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Improved detection algorithm: for target detection in high-resolution optical remote sensing images

01 Outlook Summary
Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed.
02 Background & Motivation
With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe the earth Many objects on the surface, including airplanes, cars, buildings, etc. Object detection plays a vital role in the interpretation of remote sensing images and can be used for segmentation, description and target tracking of remote sensing images. However, due to their relatively large field of view and high altitude necessities, aerial optical remote sensing images exhibit diversity in scale, viewpoint specificity, random orientation, and high background complexity, whereas most traditional datasets contain terrestrial views . As a result, the techniques used to construct artificial feature detection have traditionally had a record of large differences in accuracy and speed. Due to the needs of society and the support of the development of deep learning, the use of neural networks for target detection in optical remote sensing images is necessary.
Currently, target detection algorithms that combine deep learning to analyze optical remote sensing photos can be divided into three types: supervised, unsupervised and weakly supervised. However, due to the complexity and uncertainty of unsupervised and weakly supervised algorithms, supervised algorithms are the most commonly used algorithms. Furthermore, supervised object detection algorithms can be divided into single-stage or two-stage. Based on the assumption that aircraft are usually located at airports and ships are usually located at ports and oceans, detecting airports and ports in downsampled star images, and then mapping the discovered objects back to the original ultra-high-resolution satellite images, can detect objects of different sizes simultaneously. Some researchers have proposed a rotating target detection method based on RCNN, which improves the accuracy of target detection in remote sensing images by solving the randomization problem of target directions.
03 New Algorithm Research
Most of the current YOLO series detection heads are based on the output characteristics of FPN and PAFPN, among which the ones based on FPN Networks, such as YOLOv3, and its variants are shown in Figure a below. They directly utilize the one-way fusion feature for output. YOLOv4 and YOLOv5 based on the PAFPN algorithm add a low-level to high-level channel on this basis, which directly transmits low-level signals upward (b below).
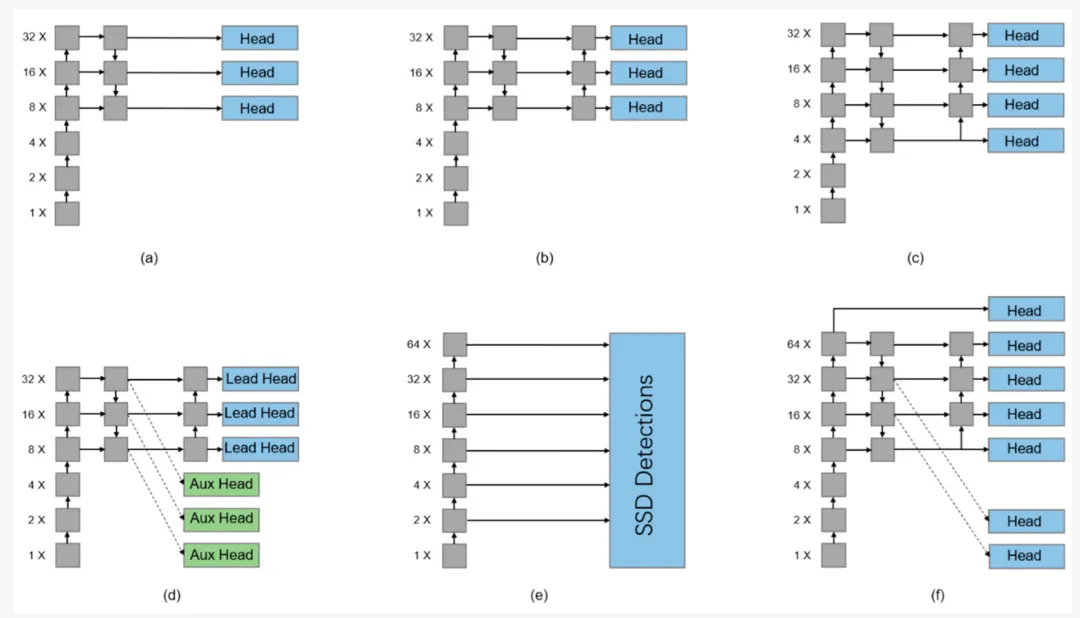
As shown in the figure above, in some studies, a detection head was added to the specific detection task in the TPH-YOLOv5 model. In Figures b and c above, only the PAFPN function can be used for output, while the FPN function is not fully utilized. Therefore, YOLOv7 connects three auxiliary heads to the FPN output, as shown in Figure d above, although the auxiliary heads are only used for "coarse selection" and have a lower weight assessment. The SSD detection head is proposed to improve the YOLO network's too rough design of the anchor set, and proposes a dense anchor design based on multi-scale. As shown in Figure f, this strategy can simultaneously utilize the feature information of PANet and FPN. In addition, there is a 64x downsampling process that directly adds the output, which makes the network contain previous global information.
The multi-detection head method can effectively utilize the output features of the network. Improved YOLO is an object detection network for high-resolution remote sensing photos. As shown in the figure below:

The basic structure of the backbone network is a CSP dense network with C3 and convolution modules as the core. After data augmentation, images are fed into the network and after channel mixing by Conv module with kernel size 6, many convolutional modules perform feature retrieval. After a feature enhancement module called SPPF, they are connected to Neck’s PANet. In order to improve the detection ability of the network, two-way feature fusion is performed. Conv2d is used to independently expand the fused feature layers to generate multi-layer outputs. As shown in the figure below, the NMS algorithm combines the outputs of all single-layer detectors to generate the final detection frame.

Figure b below describes the structural composition of each module of the improved YOLO network.

Conv includes a 2D convolution layer, BN layer batch normalization and Silu activation function, C3 includes two 2D convolution layers and a bottleneck layer, and Upsample is an upsampling layer. The SPPF module is an accelerated version of the SPP module, the MAB module is as mentioned above, and the ECA is as shown in the lower left corner. After channel-level global average pooling without dimensionality reduction, fast 1D convolutions of size k are used to capture local cross-channel interaction information, taking into account the relationship of each channel with its k neighbors, thereby efficiently performing ECA. The above two transformations collect features along two spatial directions to produce a pair of direction-aware feature maps, which are then concatenated and modified using convolution and sigmoid functions to provide attention output.
04 Experiment and Visualization
The SIMD dataset is a multi-category, open source, high-resolution remote sensing object detection dataset, containing a total of 15 categories, as shown in Figure 4. In addition, the SIMD dataset is more distributed in small and medium-sized targets (w


The output of the SPPF module can be connected to the output header to identify large targets in the image. However, the output of the SPPF module has multiple connections and involves targets at multiple scales, so using it directly for the detection head to identify large objects will result in poor model representation, as shown in the figure above, showing before and after adding the MAB module Visual comparison of heatmaps of some detection results. After adding the MAB module, the detection head focuses on detecting large targets, and allocates the prediction of small targets to other prediction heads, which improves the expression effect of the model and is more in line with the requirements of dividing detection heads based on target size in the YOLO algorithm.

Some test results are shown in the picture above. Judging from each detection result, there is not much difference from other algorithms. However, compared with other algorithms, the algorithm we studied improves the detection effect of the model while ensuring that the time consumption does not increase significantly, and uses the attention mechanism to enhance The expression effect of the model.

The above is the detailed content of Improved detection algorithm: for target detection in high-resolution optical remote sensing images. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1672
1672
 14
1428
52
1332
25
1277
29
1256
24
14
1428
52
1332
25
1277
29
1256
24

 Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
The performance of i77700 is completely sufficient to run win11, but users find that their i77700 cannot be upgraded to win11. This is mainly due to restrictions imposed by Microsoft, so they can install it as long as they skip this restriction. i77700 cannot be upgraded to win11: 1. Because Microsoft limits the CPU version. 2. Only the eighth generation and above versions of Intel can directly upgrade to win11. 3. As the 7th generation, i77700 cannot meet the upgrade needs of win11. 4. However, i77700 is completely capable of using win11 smoothly in terms of performance. 5. So you can use the win11 direct installation system of this site. 6. After the download is complete, right-click the file and "load" it. 7. Double-click to run the "One-click
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
Today I would like to introduce to you an article published by MIT last week, using GPT-3.5-turbo to solve the problem of time series anomaly detection, and initially verifying the effectiveness of LLM in time series anomaly detection. There is no finetune in the whole process, and GPT-3.5-turbo is used directly for anomaly detection. The core of this article is how to convert time series into input that can be recognized by GPT-3.5-turbo, and how to design prompts or pipelines to let LLM solve the anomaly detection task. Let me introduce this work to you in detail. Image paper title: Largelanguagemodelscanbezero-shotanomalydete
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
