
 Technology peripherals
AI
Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH
Technology peripherals
AI
Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH
Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH

The power of large models makes LLaMA3 reach new heights:
It has achieved impressive performance improvements on the 15T Token data that has undergone ultra-large-scale pre-training. It once again ignited discussions in the open source community because it far exceeded the recommendation of Chinchilla.
At the same time, at the practical application level, another hot topic has also surfaced:
In scenarios with limited resources, the quantitative performance of LLaMA3 has improved What will happen?
The University of Hong Kong, Beihang University, and Federal Institute of Technology Zurich jointly launched an empirical study that comprehensively revealed the low-bit quantization capabilities of LLaMA3.

The researchers evaluated the results of LLaMA3 with 1-8 bits and various evaluation datasets using 10 existing post-training quantized LoRA fine-tuning methods. They found:
Despite impressive performance, LLaMA3 still suffers from non-negligible degradation at low bit quantization, especially at ultra-low bit widths.

The project has been open sourced on GitHub, and the quantitative model has also been launched on HuggingFace.
Let’s look specifically at the empirical results.
Track 1: Post-training quantization
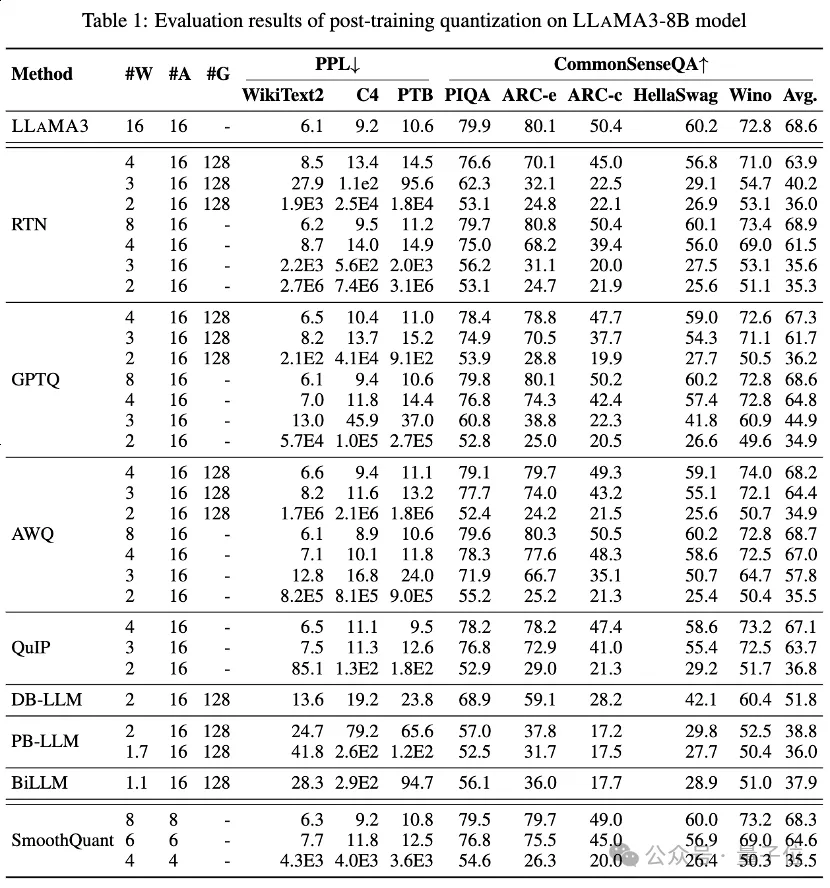
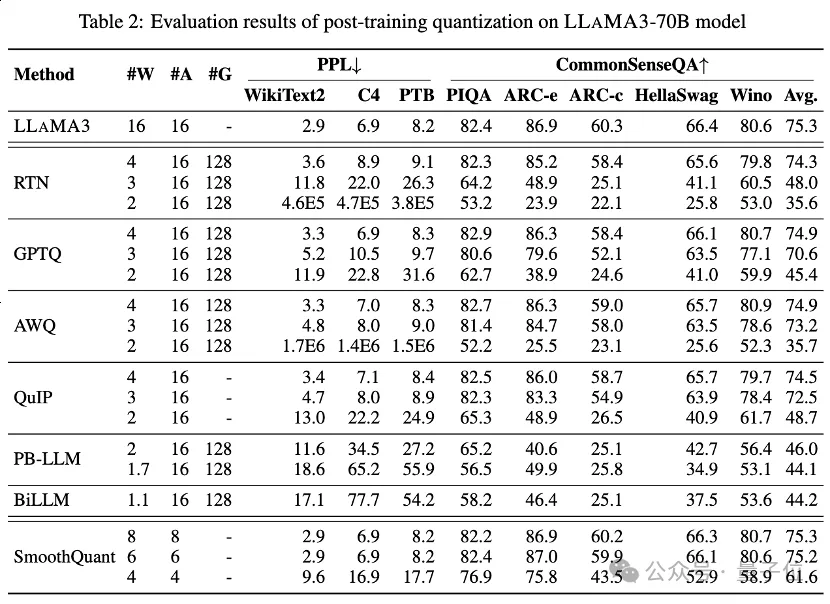
Table 1 and Table 2 provide the low-bit performance of LLaMA3-8B and LLaMA3-70B under 8 different PTQ methods, covering Wide bit width from 1 bit to 8 bits.
1. Low-bit privilege weight
Among them, Round-To-Nearest (RTN) is a basic rounding quantization method.
GPTQ is one of the most efficient and effective weight-only quantization methods currently available, which exploits error compensation in quantization. But at 2-3 bits, GPTQ causes severe accuracy collapse when quantizing LLaMA3.
AWQ uses an abnormal channel suppression method to reduce the difficulty of weight quantification, while QuIP ensures inconsistency between weights and Hessian by optimizing matrix calculations. They all maintain LLaMA3's capabilities at 3 bits and even push 2-bit quantization to promising levels.
2. Ultra-low bit width LLM weight compression
The recently emerged binary LLM quantization method achieves ultra-low bit width LLM weight compression.
PB-LLM adopts a mixed-precision quantization strategy to retain the full precision of a small part of important weights while quantizing most of the weights into 1 bit.
DB-LLM achieves efficient LLM compression through dual binarization weight division, and proposes a bias-aware distillation strategy to further enhance 2-bit LLM performance.
BiLLM further pushes the LLM quantization boundary down to 1.1 bits through residual approximation of significant weights and group quantization of non-significant weights. These LLM quantization methods specifically designed for ultra-low bit width can achieve higher precision quantization LLaMA3-8B, at ⩽2 bits far exceeding methods such as GPTQ, AWQ and QuIP at 2 bits (and even in some cases 3 bits).
3. Low-bit quantized activation
also performed LLaMA3 evaluation on quantized activation via SmoothQuant, which transfers the quantization difficulty from activations to weights to smooth activation outliers . Evaluation shows that SmoothQuant can preserve the accuracy of LLaMA3 at 8-bit and 6-bit weights and activations, but faces collapse at 4-bit.
Track 2: LoRA fine-tuned quantization
On the MMLU dataset, for LLaMA3-8B under LoRA-FT quantization, The most striking observation is that low-rank fine-tuning on the Alpaca dataset not only fails to compensate for the error introduced by quantization, but even makes the performance degradation more serious.
Specifically, the quantized LLaMA3 performance obtained by various LoRA-FT quantization methods at 4 bits is worse than the 4-bit corresponding version without LoRA-FT. This is in sharp contrast to similar phenomena on LLaMA1 and LLaMA2, where the 4-bit low-rank fine-tuned quantization version even easily outperforms the original FP16 counterpart on MMLU.
According to intuitive analysis, the main reason for this phenomenon is that the powerful performance of LLaMA3 benefits from its large-scale pre-training, which means that the performance loss after quantization of the original model cannot be passed on a small part of low-rank Fine-tuning is performed on the parameter data to compensate (this can be considered a subset of the original model).
Although the significant degradation caused by quantization cannot be compensated by fine-tuning, the 4-bit LoRA-FT quantized LLaMA3-8B significantly outperforms LLaMA1-7B and LLaMA2-7B under various quantization methods. For example, using the QLoRA method, the average accuracy of 4-bit LLaMA3-8B is 57.0 (FP16: 64.8), which exceeds the 38.4 of 4-bit LLaMA1-7B (FP16: 34.6) by 18.6, and exceeds the 43.9 of 4-bit LLaMA2-7B (FP16: 45.5 ) 13.1. This demonstrates the need for a new LoRA-FT quantization paradigm in the LLaMA3 era.
A similar phenomenon occurred in the CommonSenseQA benchmark. Model performance fine-tuned with QLoRA and IR-QLoRA also decreased compared to the 4-bit counterpart without LoRA-FT (e.g., 2.8% average decrease for QLoRA vs 2.4% average decrease for IR-QLoRA). This further demonstrates the advantage of using high-quality datasets in LLaMA3, and that the generic dataset Alpaca does not contribute to the model's performance in other tasks.
Conclusion
This paper comprehensively evaluates the performance of LLaMA3 in various low-bit quantization techniques, including post-training quantization and LoRA fine-tuned quantization.
This research finding shows that although LLaMA3 still exhibits superior performance after quantization, the performance drop associated with quantization is significant and can even lead to a larger drop in many cases.
This finding highlights the potential challenges that may be faced when deploying LLaMA3 in resource-constrained environments and highlights ample room for growth and improvement in the context of low-bit quantization. By solving the performance degradation caused by low-bit quantization, it is expected that subsequent quantization paradigms will enable LLMs to achieve stronger capabilities at lower computational costs, ultimately driving representative generative artificial intelligence to new heights.
Paper link: https://arxiv.org/abs/2404.14047.
Project link: https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ.
The above is the detailed content of Llama 3 low-bit quantization performance drops significantly! Comprehensive assessment results are here | HKU & Beihang University & ETH. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to update code in git
Apr 17, 2025 pm 04:45 PM
How to update code in git
Apr 17, 2025 pm 04:45 PM
Steps to update git code: Check out code: git clone https://github.com/username/repo.git Get the latest changes: git fetch merge changes: git merge origin/master push changes (optional): git push origin master
 How to download git projects to local
Apr 17, 2025 pm 04:36 PM
How to download git projects to local
Apr 17, 2025 pm 04:36 PM
To download projects locally via Git, follow these steps: Install Git. Navigate to the project directory. cloning the remote repository using the following command: git clone https://github.com/username/repository-name.git
 How to use git commit
Apr 17, 2025 pm 03:57 PM
How to use git commit
Apr 17, 2025 pm 03:57 PM
Git Commit is a command that records file changes to a Git repository to save a snapshot of the current state of the project. How to use it is as follows: Add changes to the temporary storage area Write a concise and informative submission message to save and exit the submission message to complete the submission optionally: Add a signature for the submission Use git log to view the submission content
 What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
Resolve: When Git download speed is slow, you can take the following steps: Check the network connection and try to switch the connection method. Optimize Git configuration: Increase the POST buffer size (git config --global http.postBuffer 524288000), and reduce the low-speed limit (git config --global http.lowSpeedLimit 1000). Use a Git proxy (such as git-proxy or git-lfs-proxy). Try using a different Git client (such as Sourcetree or Github Desktop). Check for fire protection
 How to merge code in git
Apr 17, 2025 pm 04:39 PM
How to merge code in git
Apr 17, 2025 pm 04:39 PM
Git code merge process: Pull the latest changes to avoid conflicts. Switch to the branch you want to merge. Initiate a merge, specifying the branch to merge. Resolve merge conflicts (if any). Staging and commit merge, providing commit message.
 How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local Git code? Use git fetch to pull the latest changes from the remote repository. Merge remote changes to the local branch using git merge origin/<remote branch name>. Resolve conflicts arising from mergers. Use git commit -m "Merge branch <Remote branch name>" to submit merge changes and apply updates.
 How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
When developing an e-commerce website, I encountered a difficult problem: How to achieve efficient search functions in large amounts of product data? Traditional database searches are inefficient and have poor user experience. After some research, I discovered the search engine Typesense and solved this problem through its official PHP client typesense/typesense-php, which greatly improved the search performance.
 How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
To delete a Git repository, follow these steps: Confirm the repository you want to delete. Local deletion of repository: Use the rm -rf command to delete its folder. Remotely delete a warehouse: Navigate to the warehouse settings, find the "Delete Warehouse" option, and confirm the operation.
