
 Technology peripherals
AI
2021 ML and NLP academic statistics: Google ranks first, and reinforcement learning expert Sergey Levine tops the list
Technology peripherals
AI
2021 ML and NLP academic statistics: Google ranks first, and reinforcement learning expert Sergey Levine tops the list
2021 ML and NLP academic statistics: Google ranks first, and reinforcement learning expert Sergey Levine tops the list

2021 is a very productive year for natural language processing (NLP) and machine learning (ML). Now it is time to count the papers in the field of NLP and ML last year.
MAREK REI, a researcher in machine learning and natural language processing from the University of Cambridge, summarized and analyzed classic papers in 2021 and summarized the statistics of ML and NLP publications in 2021. The major conferences and journals in the intelligence industry were analyzed, including ACL, EMNLP, NAACL, EACL, CoNLL, TACL, CL, NeurIPS, AAAI, ICLR, and ICML.
The analysis of the paper is completed using a series of automated tools, which may not be perfect and may contain some flaws and errors. For some reason, some authors started publishing their papers in obfuscated form to prevent any form of content duplication or automated content extraction, and these papers were excluded from the analysis process.
Now let’s take a look at the MAREK REI statistical results.
Based on academic conference statistics
The number of submissions to most conferences continues to rise and break records. ACL appears to be an exception, with AAAI almost leveling off and NeurIPS still growing steadily.
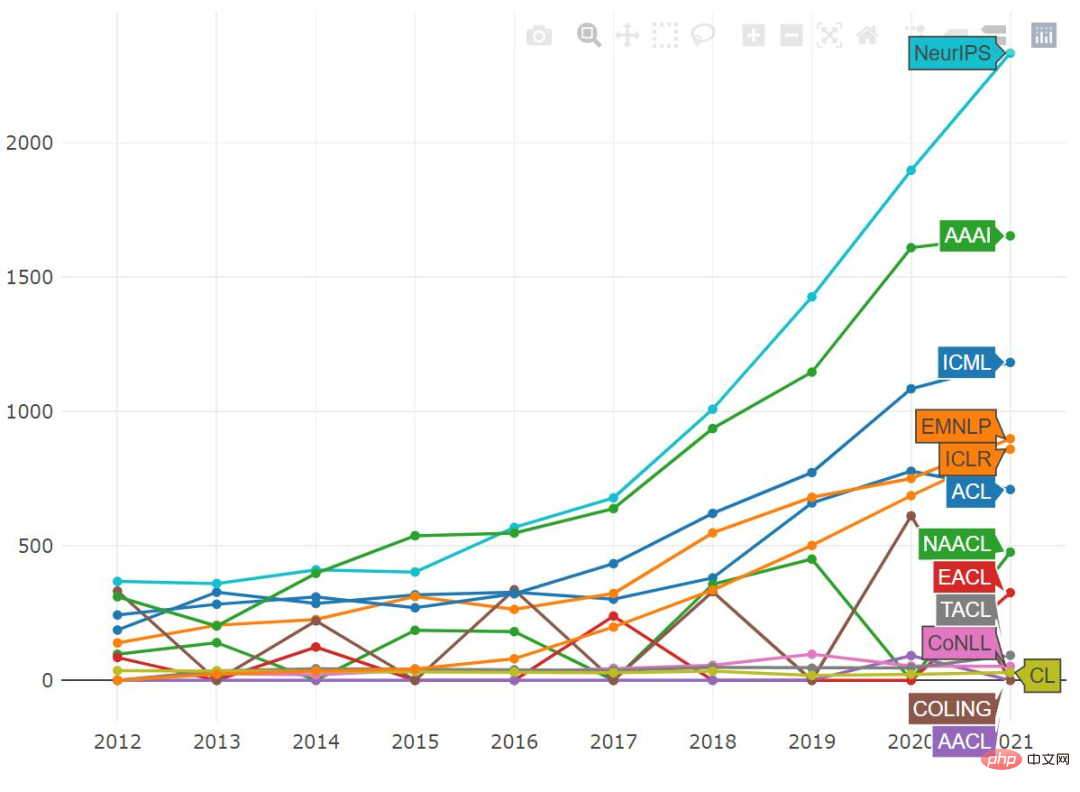
Based on institutional statistics
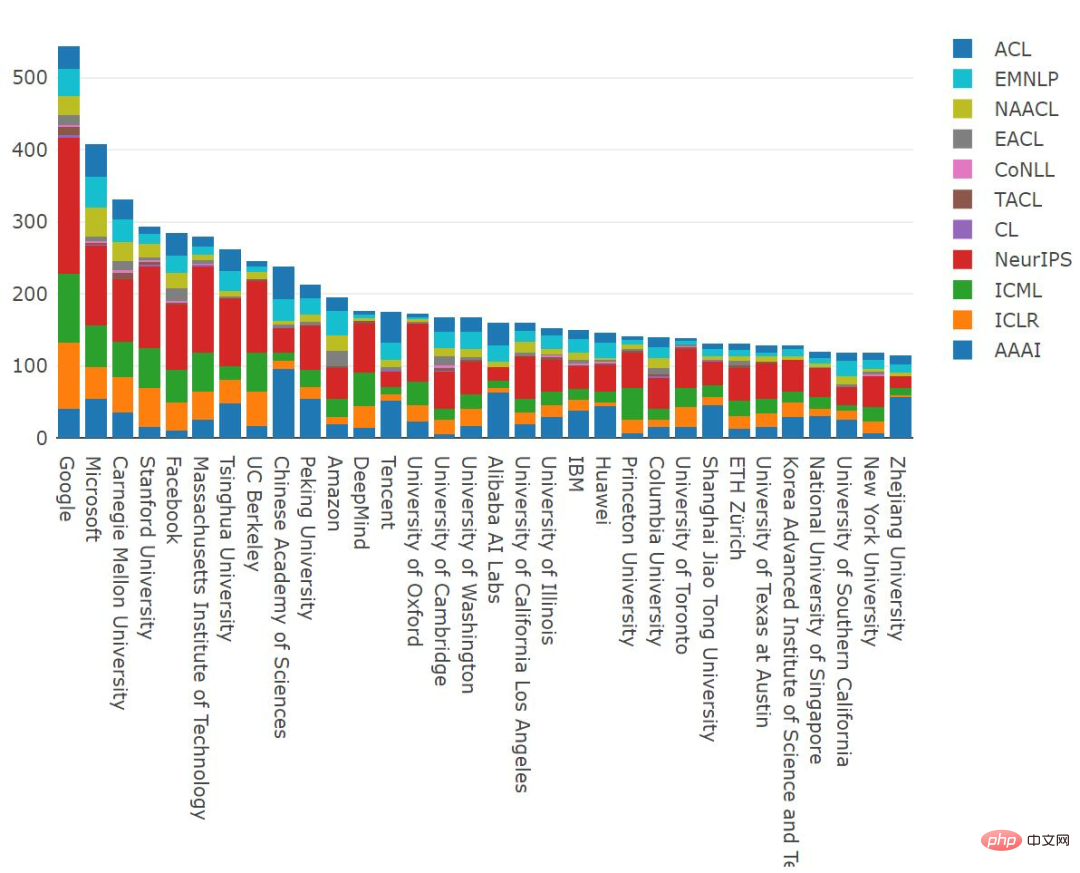
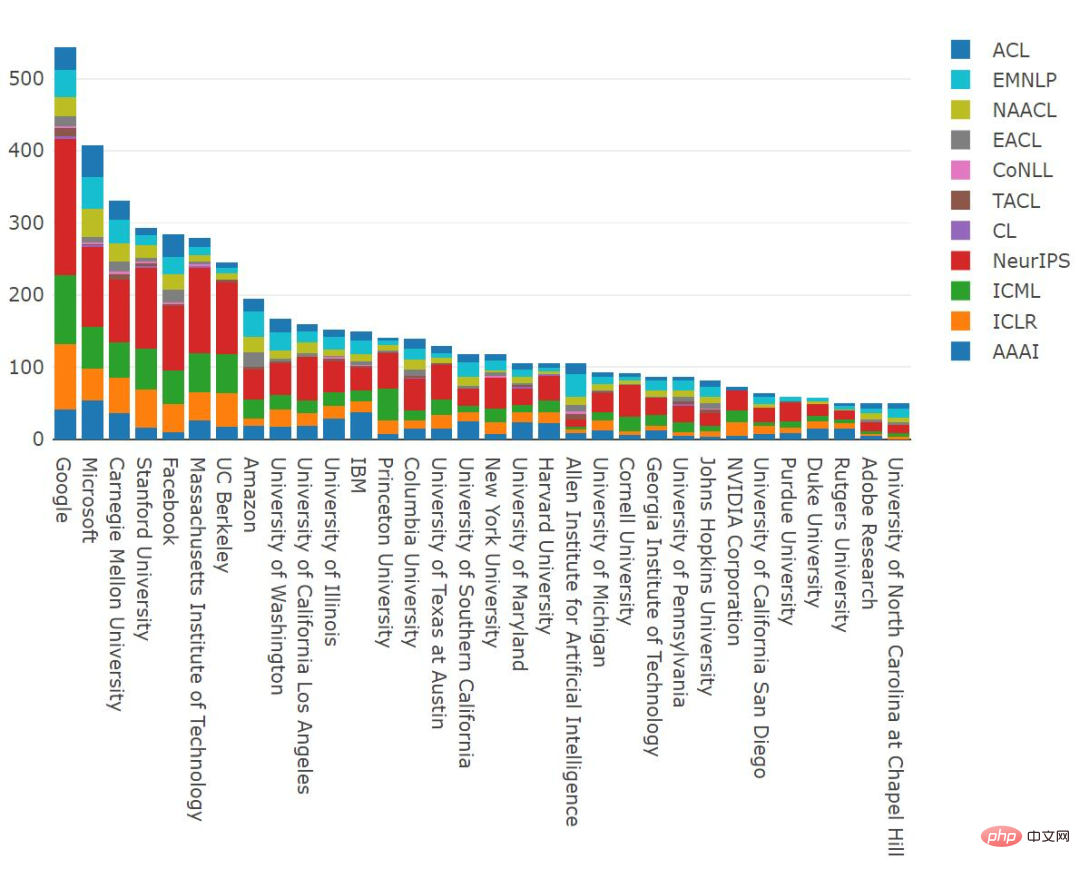
The leading research institution in the number of papers published in 2021 is undoubtedly Google ; Microsoft ranked second; CMU, Stanford University, Meta and MIT ranked closely behind, and Tsinghua University ranked seventh. Microsoft, CAS, Amazon, Tencent, Cambridge, Washington, and Alibaba stand out with a sizable proportion of papers at NLP conferences, while other top organizations seem to focus primarily on the ML field.
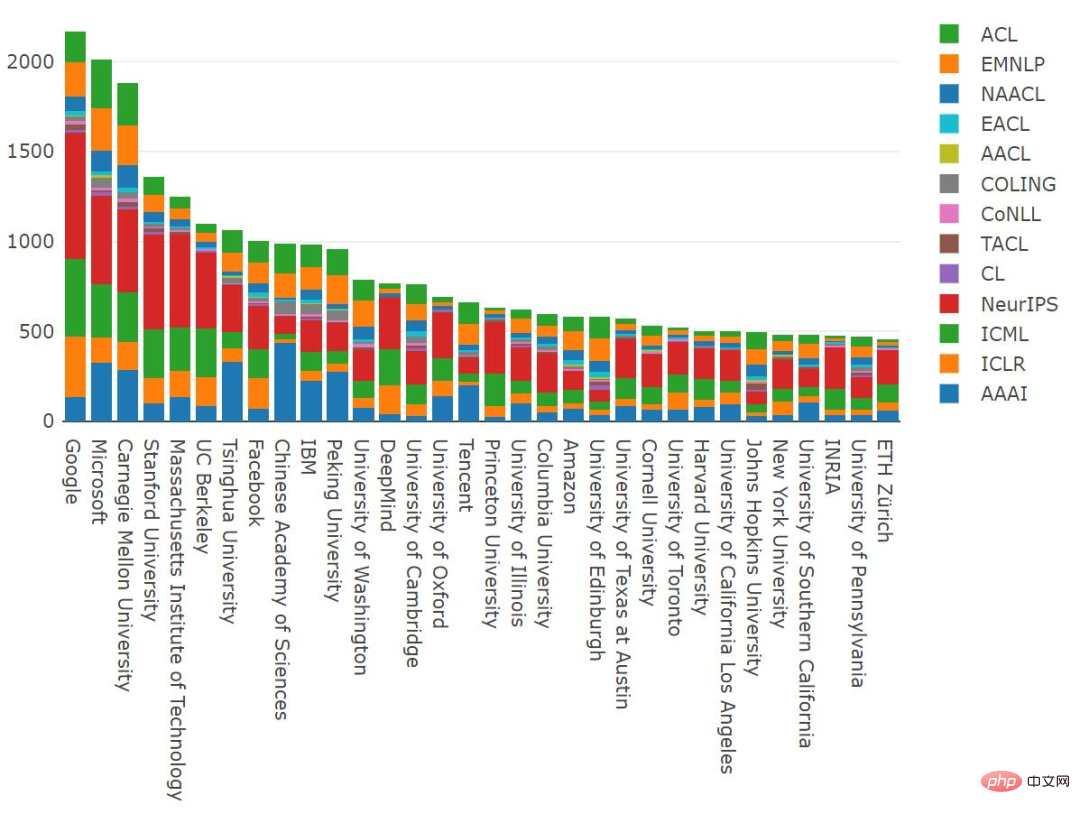
From the data of 2012-2021, Google published 2170 papers and ranked first, surpassing the 2013 papers published by Microsoft . CMU published 1,881 papers, ranking third.
Most institutions continue to increase their annual publication numbers. The number of papers published by Google used to grow linearly, and now this trend has eased, but it still publishes more papers than before; CMU had a plateau last year, but has made up for it this year; IBM seems to be the only company that publishes slightly more papers Declining institutions.
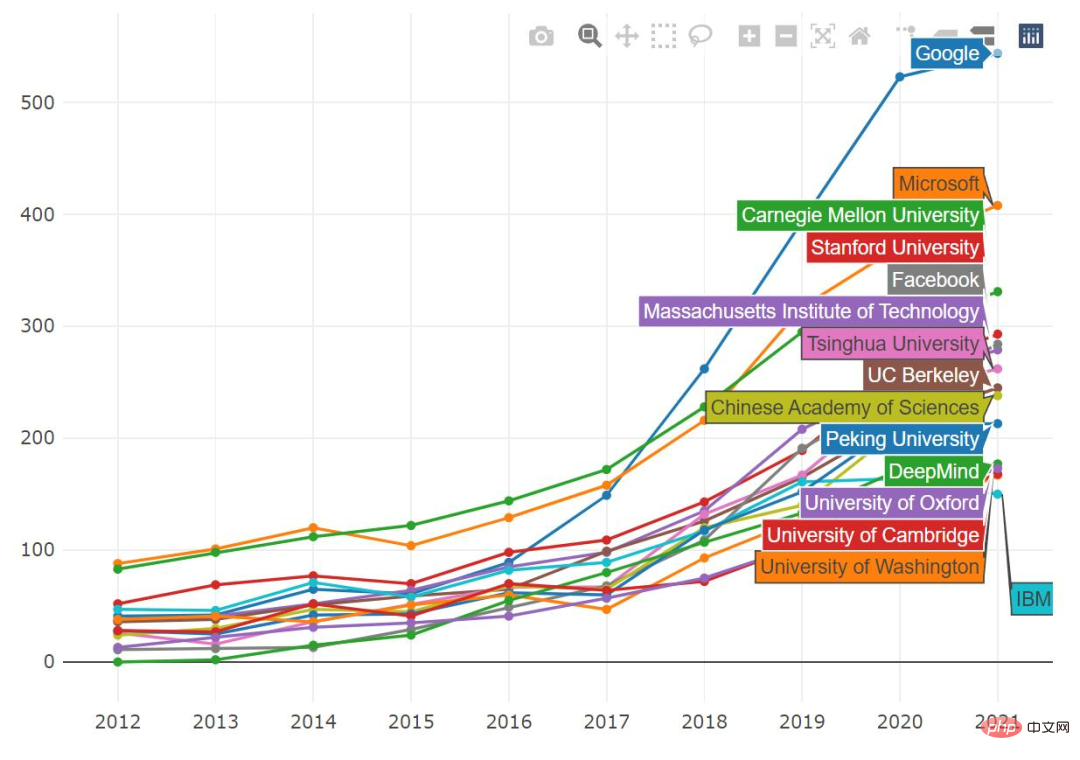
By author statistics
Next, let’s take a look at 2021 Researchers who publish the most papers per year. Sergey Levine (Assistant Professor of Electrical Engineering and Computer Science, University of California, Berkeley) published 42 papers, ranking first; Liu Tieyan (Microsoft), Zhou Jie (Tsinghua University), Mohit Bansal (University of North Carolina at Chapel Hill), Graham Neubig (CMU) also ranks relatively high in the number of papers published.
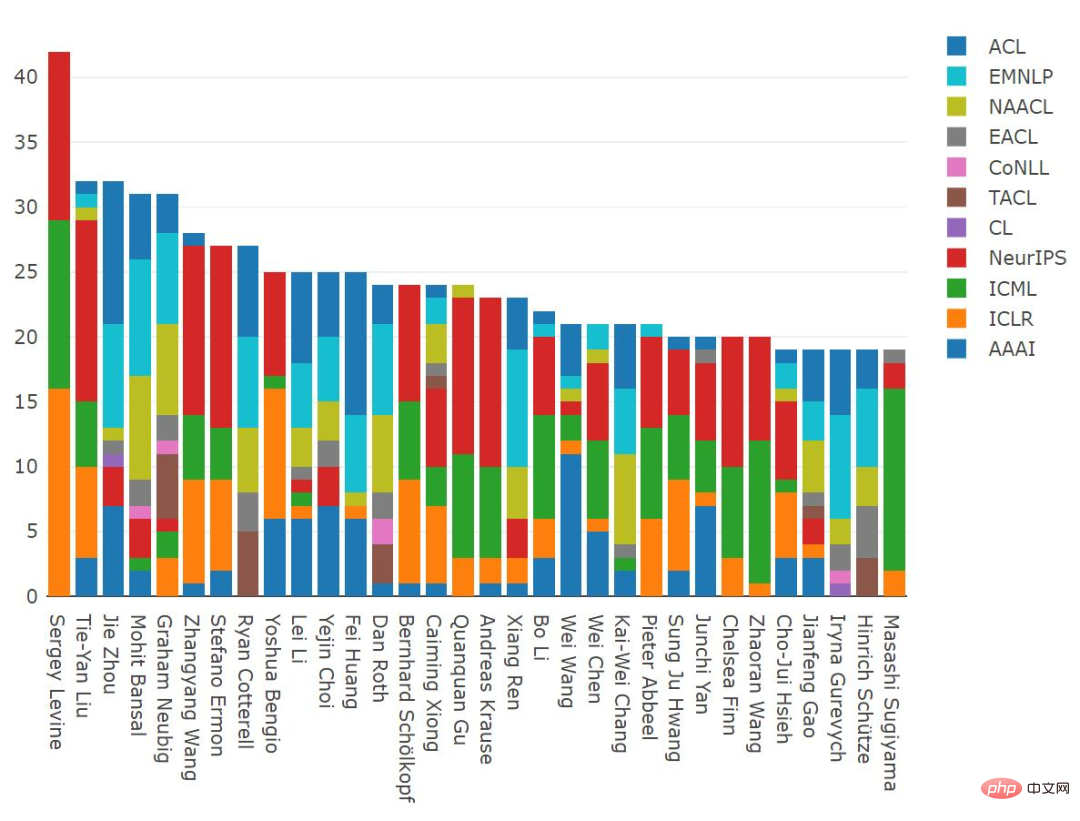
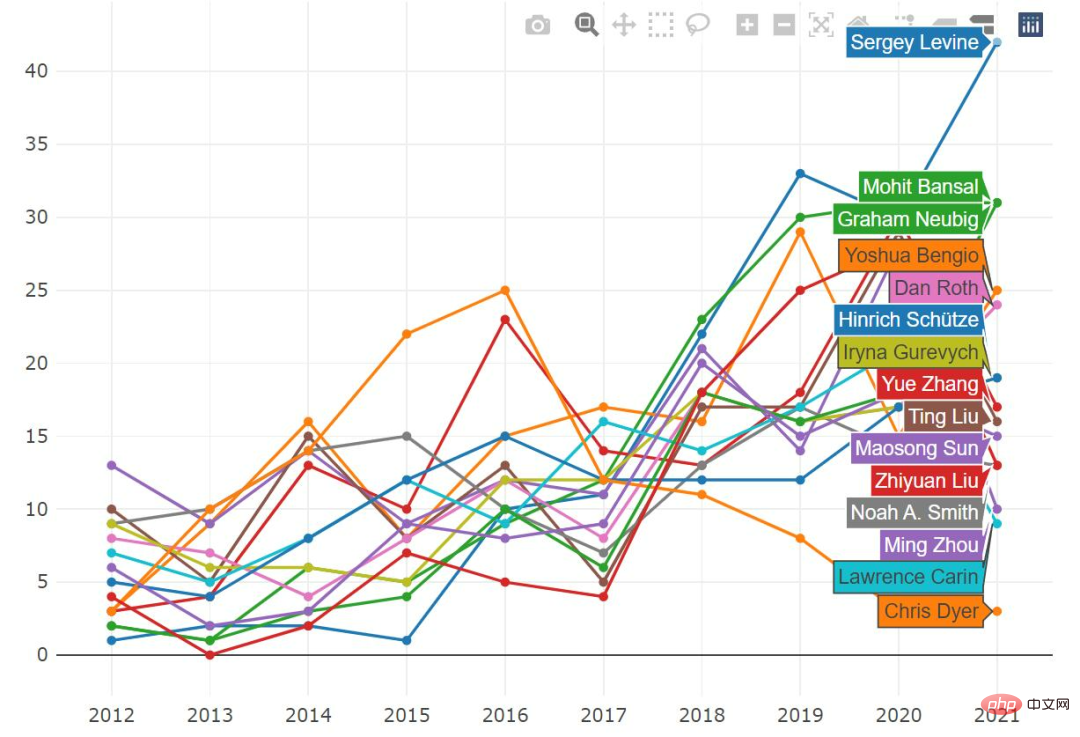
Throughout 2012-2021, the papers published by Sergey Levine ranked first. Last year he ranked sixth. This year It jumped to the first place; Yoshua Bengio (Montreal), Graham Neubig (CMU), Zhang Yue (Westlake University), Zhou Ming (Chief Scientist of Innovation Works), Ting Liu (Harbin Institute of Technology) and others also ranked relatively high in terms of the number of papers they published. .
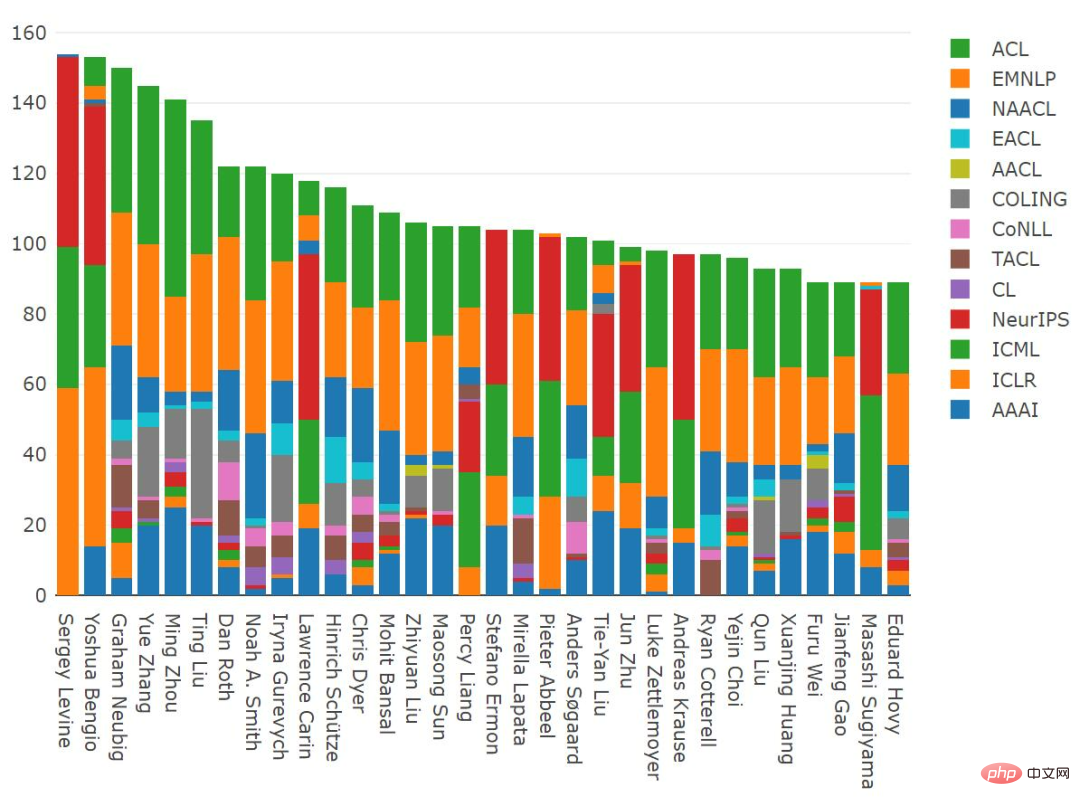
Sergey Levine sets a new record by a considerable margin; Mohit Bansal’s number of papers also increases significantly, 2021 Published 31 papers in 2020, the same as Graham Neubig; Yoshua Bengio's number of papers decreased in 2020, but is now rising again.
Statistics of papers published as the first author
Researchers who publish the most papers are usually postdocs and supervisors. In contrast, people who publish more papers as first authors are usually people who do actual research.
Ramit Sawhney (Technical Director of Tower Research Capital) published 9 influential papers in 2021, Jason Wei (Google) and Tiago Pimentel (PhD student at Cambridge University) published respectively 6 influential papers were published.
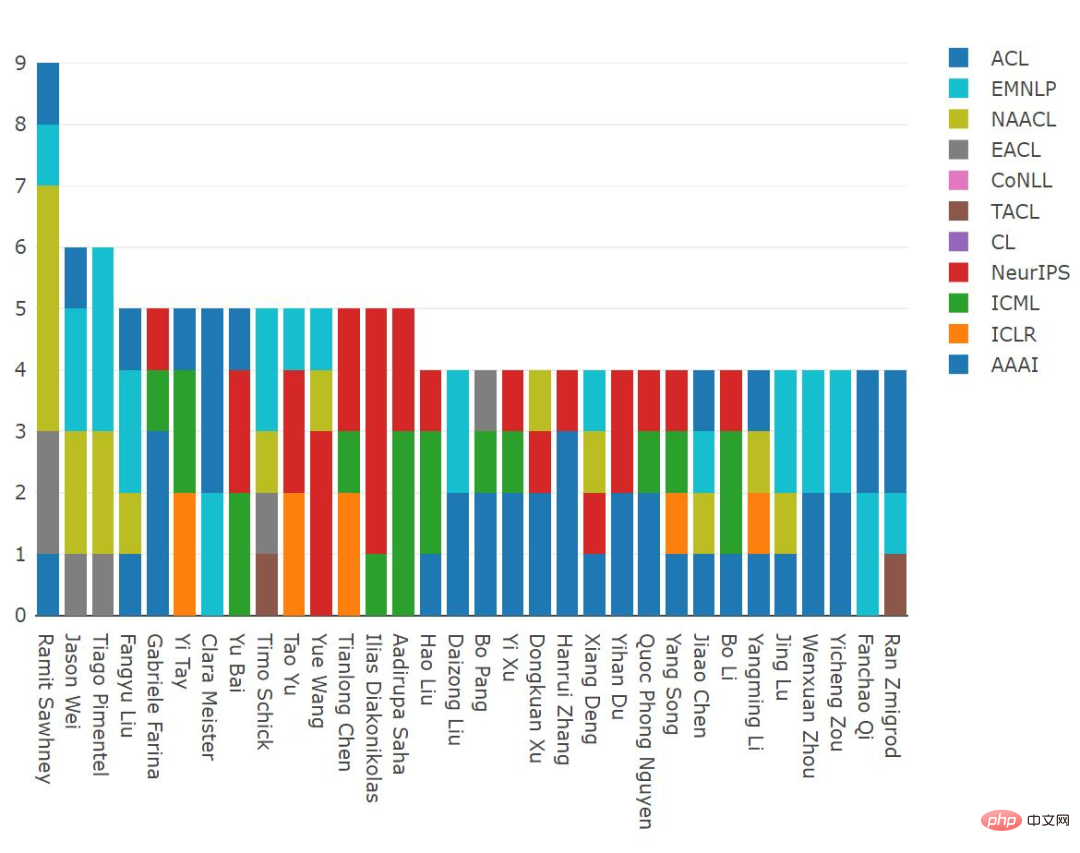
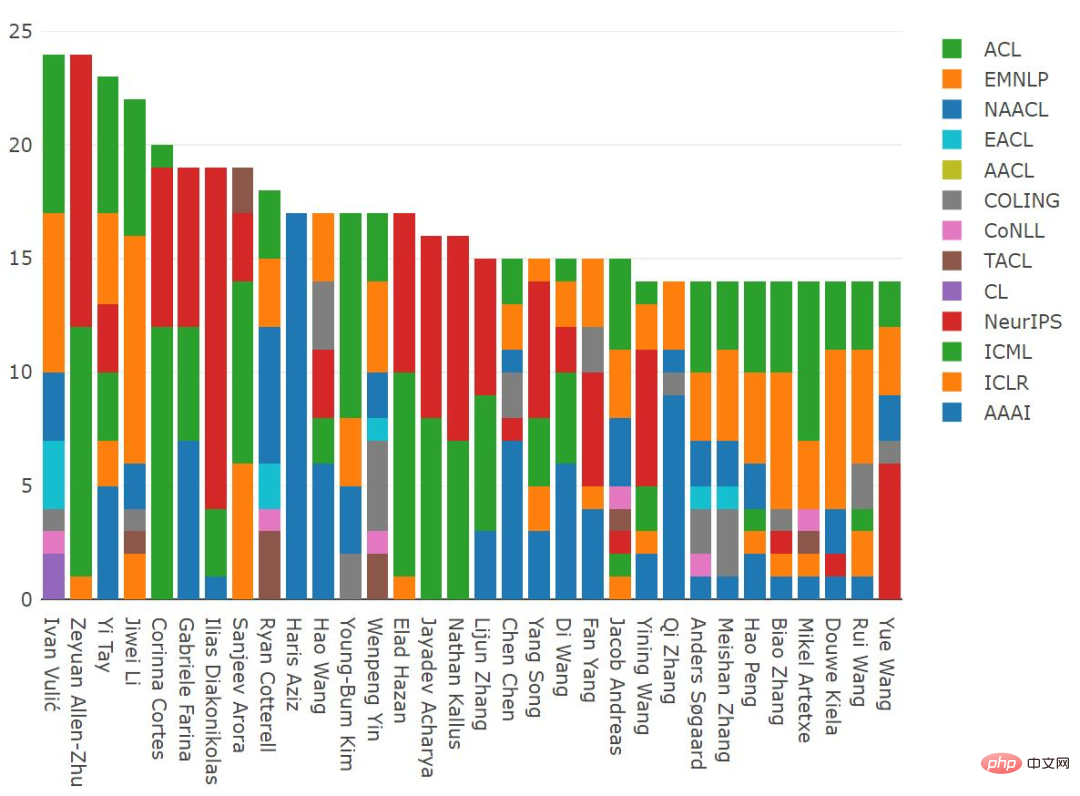
From the 2012-2021 distribution, Ivan Vulić (University of Cambridge) and Zeyuan Allen-Zhu (Microsoft) are both first authors Published 24 influential papers, tied for first place; Yi Tay (Google) and Li Jiwei (Shannon Technology) ranked second, having published 23 and 22 influential papers as first authors respectively. papers on NeurIPS; Ilias Diakonikolas (University of Wisconsin-Madison) has published 15 NeurIPS papers as the first author.
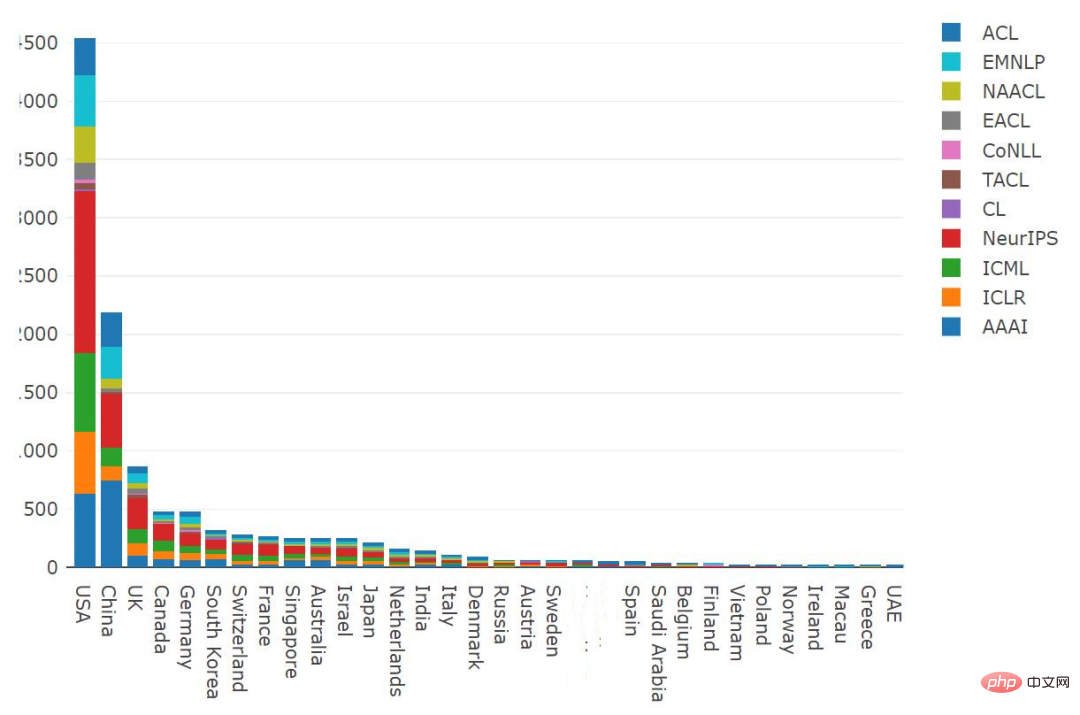
Based on national statistics
Number of publications by country in 2021, United States The number of publications is the largest, with China and the UK ranking second and third respectively. In the United States and the United Kingdom, NeurIPS accounts for the largest proportion, while AAAI accounts for the largest proportion in China.
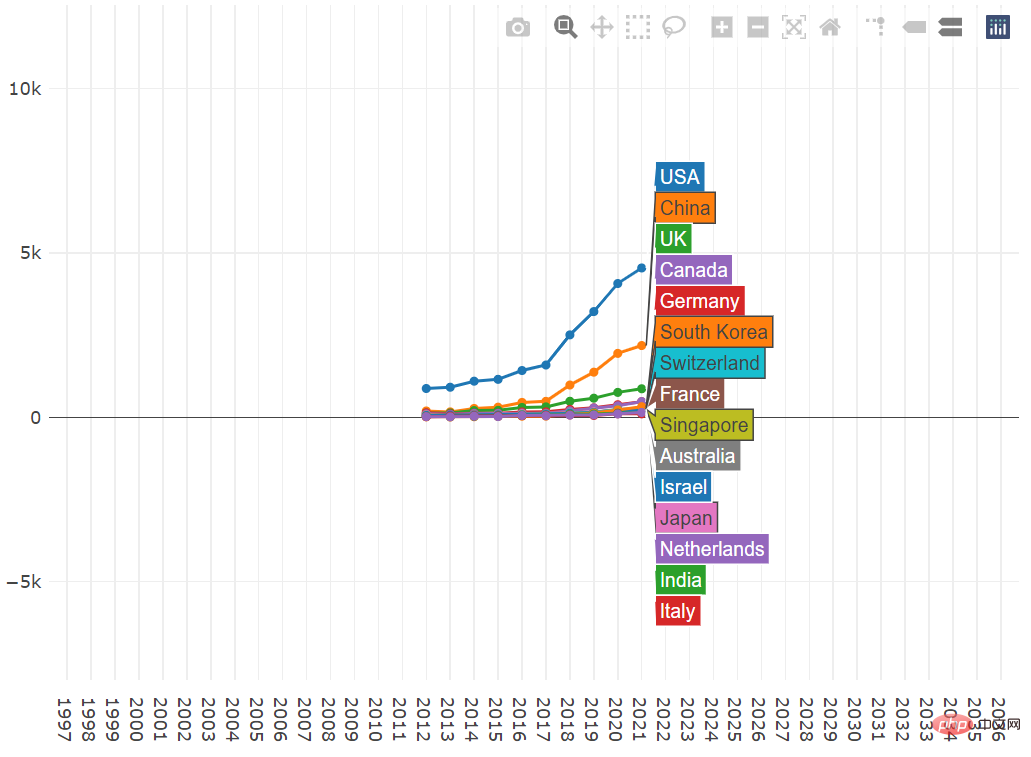
 The vertical coordinates from top to bottom are 500, 1000, 1500, 2000, 2500, and so on
The vertical coordinates from top to bottom are 500, 1000, 1500, 2000, 2500, and so on
Almost all top-ranked countries continue to increase their number of publications and set new records in 2021. The increase was the largest for the United States, further extending its lead.
In the United States, Google, Microsoft and CMU once again lead the list in terms of number of publications.
##In China, Tsinghua University, Chinese Academy of Sciences and Peking University published the most papers in 2021.
Through visualization, these Organizations are clustered together primarily based on geographic proximity, with companies in the middle.
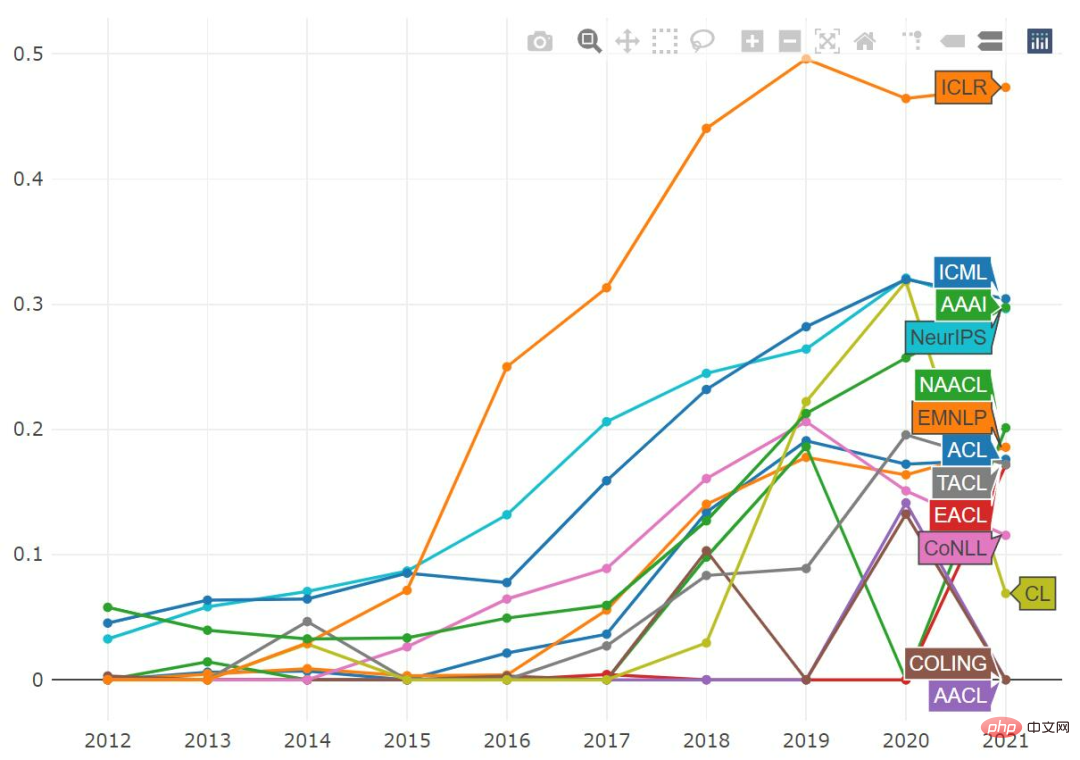
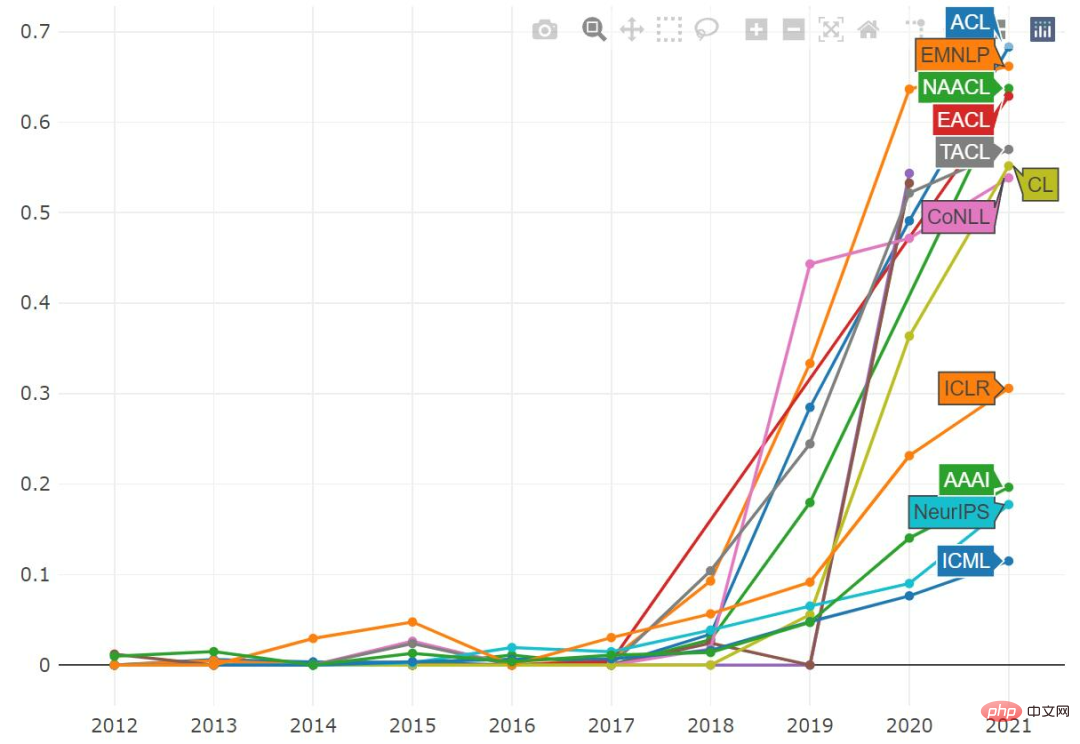
We can also draw drawings containing specific keys word proportion of papers and track changes in this proportion over time.
The word “neural” seems to be on a slight downward trend, although you can still find it in 80% of papers. At the same time, the proportions of "recurrent" and "convolutional" are also declining, and the word "transformer" appears in more than 30% of papers.
If you look at the word "adversarial" alone, we will find that it is very common in ICLR, and almost half of the papers mention it. The proportion of "adversarial" in ICML and NeurIPS seems to have peaked before, while AAAI has not. In the past few years, the term "transformer" has become very popular. It is particularly widely used in NLP papers, with over 50% of published papers containing it, and its popularity is steadily increasing across all ML conferences. 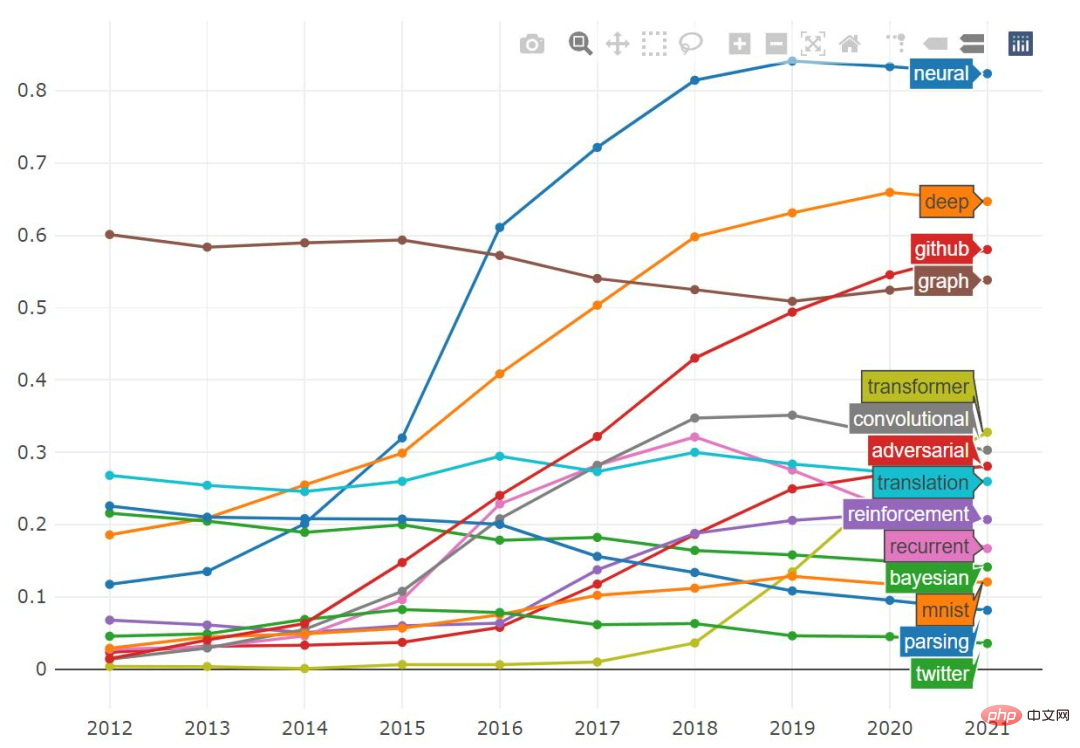
The above is the detailed content of 2021 ML and NLP academic statistics: Google ranks first, and reinforcement learning expert Sergey Levine tops the list. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
If you need to know how to use filtering with multiple criteria in Excel, the following tutorial will guide you through the steps to ensure you can filter and sort your data effectively. Excel's filtering function is very powerful and can help you extract the information you need from large amounts of data. This function can filter data according to the conditions you set and display only the parts that meet the conditions, making data management more efficient. By using the filter function, you can quickly find target data, saving time in finding and organizing data. This function can not only be applied to simple data lists, but can also be filtered based on multiple conditions to help you locate the information you need more accurately. Overall, Excel’s filtering function is a very practical
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
