
 Technology peripherals
AI
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Technology peripherals
AI
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!

0.この記事は何をするのですか?
提案された DepthFM: 多用途かつ高速な最先端の生成単眼深度推定モデル 。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。
この作品を一緒に読みましょう~
1. 論文情報
タイトル: DepthFM: フローマッチングによる高速単眼深度推定
著者: Ming Gui、Johannes S. Fischer、Ulrich Prestel、Pingchuan Ma、Dmytrokotovenko、Olga Grebenkova、Stefan Andreas Baumann、Vincent Tao Hu、Björn Ommer
機関: MCML
元のリンク: https://arxiv.org/abs/2403.13788
コードリンク: https://github.com/CompVis/ Depth-fm
公式ホームページ: https:// Depthfm.github .io/
2. 要約
は、下流の観光タスクやアプリケーションの多くにとって重要です。この問題に対する現在の識別方法は不鮮明なアーティファクトによって制限されていますが、最先端の生成方法は SDE の性質によりトレーニング サンプル速度が遅いという問題があります。ノイズから始めるのではなく、入力画像から深度画像への直接マッピングを求めます。解空間内の直線軌道が効率と高品質を提供するため、これはフロー マッチングによって効率的に構築できることがわかりました。私たちの研究は、事前トレーニングされた画像拡散モデルがフローマッチングの深いモデルのための十分な事前知識として使用できることを示しています。複雑な自然シーンのベンチマークでは、私たちの軽量アプローチは、少量の合成データのみでトレーニングされているにもかかわらず、有利な低計算コストで最先端のパフォーマンスを実証します。
3. 効果のデモ
DepthFM は、強力なゼロサンプル汎化機能を備えた高速推論フロー マッチング モデルで、強力な事前知識を利用でき、非常に使いやすいです。 . 未知の実像に簡単に一般化できます。合成データでトレーニングした後、モデルは未知の実際の画像に対して適切に一般化され、深度画像と正確に一致します。

他の最先端のモデルと比較して、DepthFM は 1 回の関数評価のみで非常に鮮明な画像を取得します。 Marigold の深度推定には DethFM の 2 倍の時間がかかりますが、同じ粒度で深度マップを生成することはできません。

4. 主な貢献
(1) 最先端の多機能高速単眼鏡DepthFMの提案深度推定モデル。従来の深度推定タスクに加えて、DepthFM は、深度修復や深度条件付き画像合成などの下流タスクでも最先端の機能を実証します。
(2) は、トレーニング データにほとんど依存せず、実世界の画像を必要とせずに、拡散モデルからフロー マッチング モデルへの強力な画像事前分布の転送が成功したことを示しています。
(3) は、フロー マッチング モデルが効率的であり、単一の推論ステップ内で深度マップを合成できることを示しています。
(4) DepthFM は合成データのみでトレーニングされているにもかかわらず、ベンチマーク データセットと自然画像で良好なパフォーマンスを発揮します。
(5) 表面法線損失を補助ターゲットとして使用して、より正確な深度推定を取得します。
(6) 深さの推定に加えて、その予測の信頼性も確実に予測できます。
5. 具体的な原則は何ですか?
トレーニング パイプライン。 トレーニングは、フロー マッチングと表面法線損失によって制限されます。フロー マッチングの場合、データ依存のフロー マッチングを使用して、グラウンド トゥルースの深さと対応する画像の間のベクトル フィールドを回帰します。さらに、表面法線の損失によって幾何学的なリアリズムが実現されます。
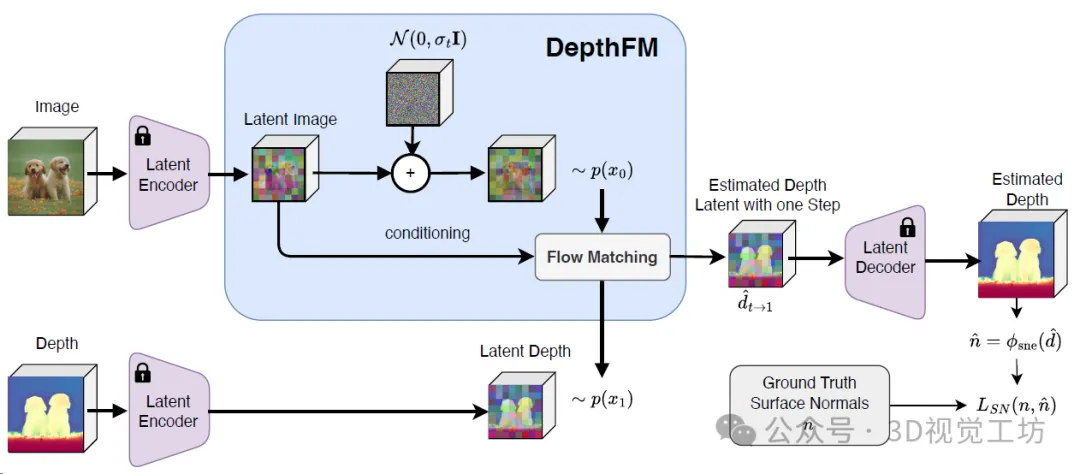
データ関連のフロー マッチング: DepthFM は、画像と深度のペアを利用して、画像分布と深度分布の間の直線ベクトル場を回帰します。このアプローチにより、パフォーマンスを犠牲にすることなく、効率的な複数ステップの推論が促進されます。
拡散事前分布からの微調整: 著者らは、強力な画像事前分布を基本画像合成拡散モデル (安定拡散 v2-1) からフロー マッチング モデルにほとんど変換せずに転送することに成功したことを実証します。依存関係トレーニング データを使用するため、現実世界の画像は必要ありません。
補助表面法線損失: DepthFM が合成データでのみトレーニングされていることを考慮すると、ほとんどの合成データ セットはグラウンド トゥルースの表面法線を提供し、表面法線損失は補助ターゲットとして使用されます。 DepthFM 深度推定の精度を向上させます。
6. Experimental results
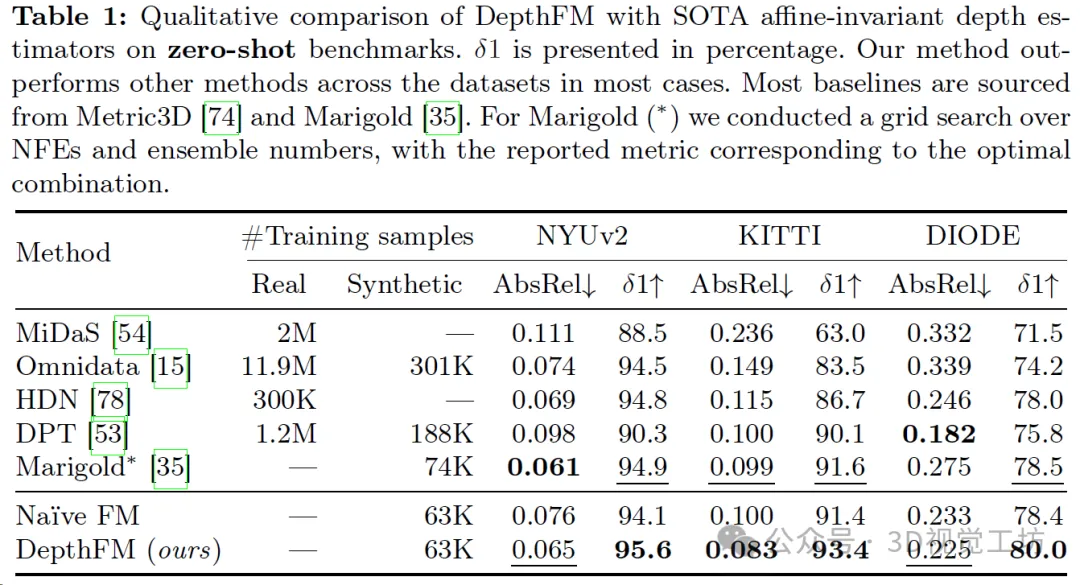
DepthFM demonstrates significant generalization ability by training only on 63k purely synthetic samples, and is able to perform zero-level training on indoor and outdoor data sets. - Shot depth estimation. Table 1 qualitatively shows the performance comparison of DepthFM with state-of-the-art corresponding models. While other models often rely on large datasets for training, DepthFM leverages the rich knowledge inherent in the underlying diffusion-based model. This method not only saves computing resources, but also emphasizes the adaptability and training efficiency of the model.
Comparison of diffusion-based Marigold depth estimation, Flow Matching (FM) benchmark and DepthFM model. Each method is evaluated using only one ensemble member and with varying numbers of function evaluations (NFE) on two common benchmark datasets. Compared with the FM baseline, DepthFM integrates normal loss and data-dependent coupling during training.
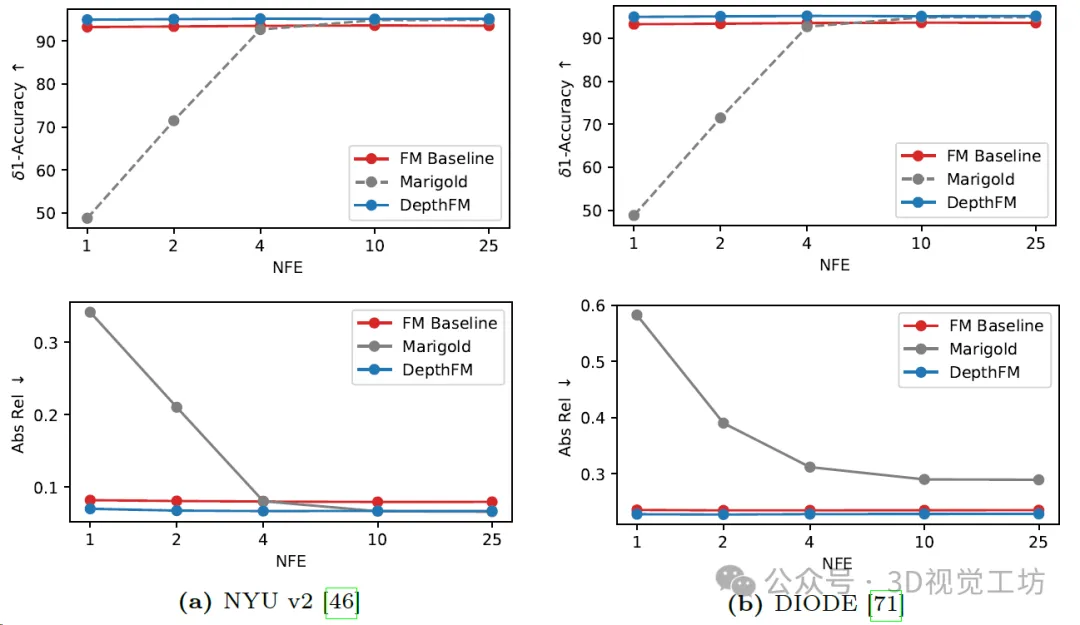
Qualitative results for Marigold and DepthFM models in different numbers of functional evaluations. It is worth noting that Marigold does not give any meaningful results through one-step inference, while the results of DepthFM already show the real depth map.

Perform deep completion on Hypersim. Left: Giving some depth. Medium: Depth estimated from the given partial depth. Right: True depth.

#7. Summary
DepthFM, a flow matching method for monocular depth estimation. By learning a direct mapping between the input image and depth, rather than denoising a normal distribution into a depth map, this approach is significantly more efficient than current diffusion-based solutions while still providing fine-grained depth maps without Common artifacts of the discriminative paradigm. DepthFM uses a pre-trained image diffusion model as a prior, effectively transferring it to a deep flow matching model. Therefore, DepthFM is only trained on synthetic data but still generalizes well to natural images during inference. Additionally, auxiliary surface normal loss has been shown to improve depth estimation. DepthFM's lightweight approach is competitive, fast, and provides reliable confidence estimates.
Readers who are interested in more experimental results and article details can read the original paper
The above is the detailed content of Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
