
 Backend Development
Python Tutorial
Basic operation methods of Python data analysis library pandas_python
Backend Development
Python Tutorial
Basic operation methods of Python data analysis library pandas_python
Basic operation methods of Python data analysis library pandas_python

Below I will share with you a basic operation method of the Python data analysis library pandas. It has a good reference value and I hope it will be helpful to everyone. Come and take a look together
#What is pandas?

Is that it?
. . . . Obviously pandas is not as cute as this guy. . . .
Let’s take a look at how pandas’ official website defines itself:
pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language.
Obviously, pandas is a very powerful data analysis library for Python!
Let’s learn it!
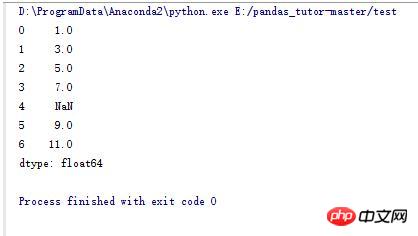
1.pandas sequence
import numpy as np import pandas as pd s_data = pd.Series([1,3,5,7,np.NaN,9,11])#pandas中生产序列的函数,类似于我们平时说的数组 print s_data
2.pandas data structure DataFrame
import numpy as np import pandas as pd #以20170220为基点向后生产时间点 dates = pd.date_range('20170220',periods=6) #DataFrame生成函数,行索引为时间点,列索引为ABCD data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data print print data.shape print print data.values

3. Some operations of DataFrame (1)
import numpy as np
import pandas as pd
#设计一个字典
d_data = {'A':1,'B':pd.Timestamp('20170220'),'C':range(4),'D':np.arange(4)}
print d_data
#使用字典生成一个DataFrame
df_data = pd.DataFrame(d_data)
print df_data
#DataFrame中每一列的类型
print df_data.dtypes
#打印A列
print df_data.A
#打印B列
print df_data.B
#B列的类型
print type(df_data.B)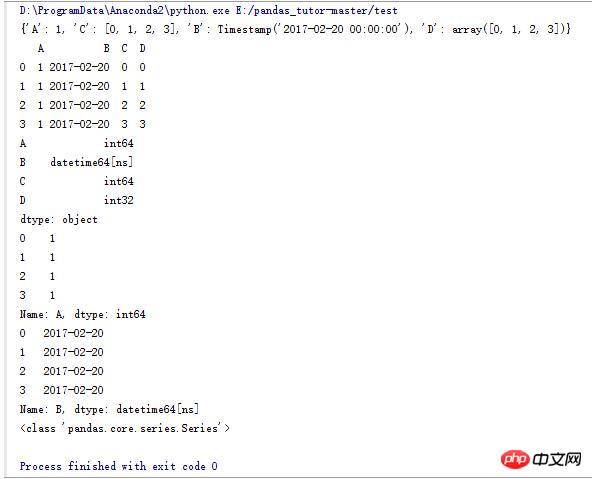
4. Some operations of DataFrame (2)
import numpy as np import pandas as pd dates = pd.date_range('20170220',periods=6) data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data print #输出DataFrame头部数据,默认为前5行 print data.head() #输出输出DataFrame第一行数据 print data.head(1) #输出DataFrame尾部数据,默认为后5行 print data.tail() #输出输出DataFrame最后一行数据 print data.tail(1) #输出行索引 print data.index #输出列索引 print data.columns #输出DataFrame数据值 print data.values #输出DataFrame详细信息 print data.describe()

5. Some operations of DataFrame (3)
import numpy as np import pandas as pd dates = pd.date_range('20170220',periods=6) data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data print #转置 print data.T #输出维度信息 print data.shape #转置后的维度信息 print data.T.shape #将列索引排序 print data.sort_index(axis = 1) #将列索引排序,降序排列 print data.sort_index(axis = 1,ascending=False) #将行索引排序,降序排列 print data.sort_index(axis = 0,ascending=False) #按照A列的值进行升序排列 print data.sort_values(by='A')

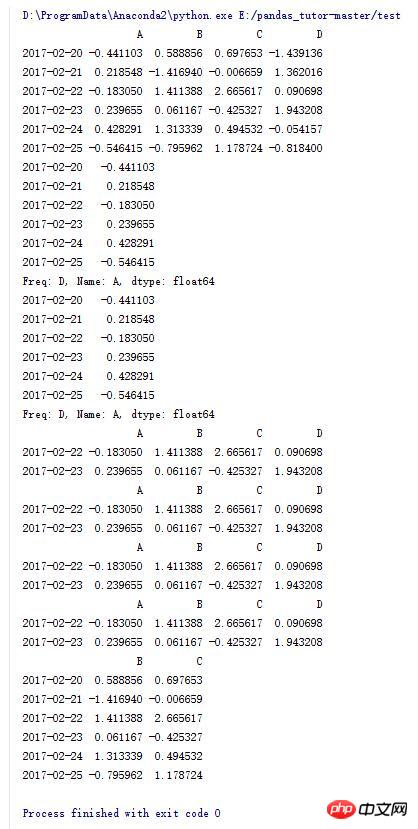
6 .Some operations on DataFrame (4)
##
import numpy as np import pandas as pd dates = pd.date_range('20170220',periods=6) data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data #输出A列 print data.A #输出A列 print data['A'] #输出3,4行 print data[2:4] #输出3,4行 print data['20170222':'20170223'] #输出3,4行 print data.loc['20170222':'20170223'] #输出3,4行 print data.iloc[2:4] 输出B,C两列 print data.loc[:,['B','C']]
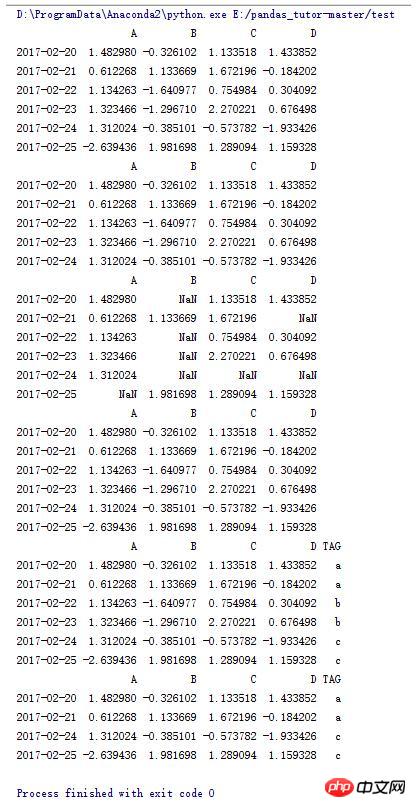
##7. Some operations of DataFrame (5)
import numpy as np import pandas as pd dates = pd.date_range('20170220',periods=6) data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data #输出A列中大于0的行 print data[data.A > 0] #输出大于0的数据,小于等于0的用NaN补位 print data[data > 0] #拷贝data data2 = data.copy() print data2 tag = ['a'] * 2 + ['b'] * 2 + ['c'] * 2 #在data2中增加TAG列用tag赋值 data2['TAG'] = tag print data2 #打印TAG列中为a,c的行 print data2[data2.TAG.isin(['a','c'])]
import numpy as np import pandas as pd dates = pd.date_range('20170220',periods=6) data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) print data #将第一行第一列元素赋值为100 data.iat[0,0] = 100 print data #将A列元素用range(6)赋值 data.A = range(6) print data #将B列元素赋值为200 data.B = 200 print data #将3,4列元素赋值为1000 data.iloc[:,2:5] = 1000 print data
 ##9.DataFrame Some operations (7)
##9.DataFrame Some operations (7)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#重定义索引,并添加E列
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#将E列中的2,3行赋值为2
dfl.loc[dates[1:3],'E'] = 2
print dfl
#去掉存在NaN元素的行
print dfl.dropna()
#将NaN元素赋值为5
print dfl.fillna(5)
#判断每个元素是否为NaN
print pd.isnull(dfl)
#求列平均值
print dfl.mean()
#对每列进行累加
print dfl.cumsum()
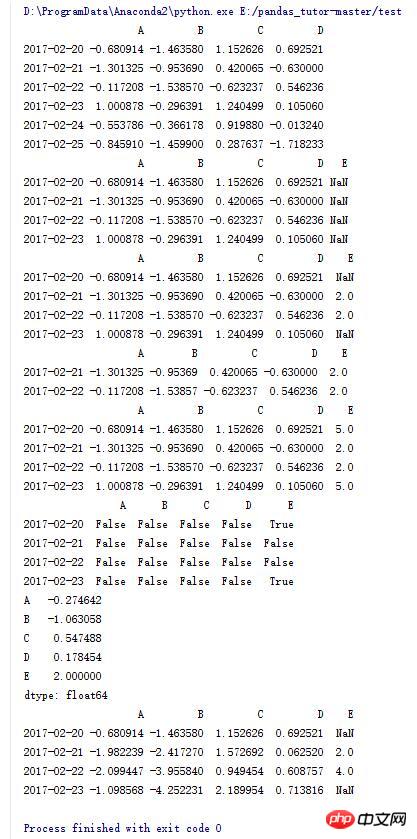 10.Some of the DataFrame Operation (8)
10.Some of the DataFrame Operation (8)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#针对行求平均值
print dfl.mean(axis=1)
#生成序列并向右平移两位
s = pd.Series([1,3,5,np.nan,6,8],index = dates).shift(2)
print s
#df与s做减法运算
print df.sub(s,axis = 'index')
#每列进行累加运算
print df.apply(np.cumsum)
#每列的最大值减去最小值
print df.apply(lambda x: x.max() - x.min())
##11. Some operations of DataFrame (9)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#定义一个函数
def _sum(x):
print(type(x))
return x.sum()
#apply函数可以接受一个函数作为参数
print df.apply(_sum)
s = pd.Series(np.random.randint(10,20,size = 15))
print s
#统计序列中每个元素出现的次数
print s.value_counts()
#返回出现次数最多的元素
print s.mode()
12. Some operations of DataFrame ( 10)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
#合并函数
dfl = pd.concat([df.iloc[:3],df.iloc[3:7],df.iloc[7:]])
print dfl
#判断两个DataFrame中元素是否相等
print df == dfl
13. Some operations of DataFrame (11 )
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
left = pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})
right = pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})
print left
print right
#通过key来合并数据
print pd.merge(left,right,on='key')
s = pd.Series(np.random.randint(1,5,size = 4),index = list('ABCD'))
print s
#通过序列添加一行
print df.append(s,ignore_index = True)

import numpy as np
import pandas as pd
df = pd.DataFrame({'A': ['foo','bar','foo','bar',
'foo','bar','foo','bar'],
'B': ['one','one','two','three',
'two','two','one','three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
print df
print
#根据A列的索引求和
print df.groupby('A').sum()
print
#先根据A列的索引,在根据B列的索引求和
print df.groupby(['A','B']).sum()
print
#先根据B列的索引,在根据A列的索引求和
print df.groupby(['B','A']).sum()
##15. Some operations of DataFrame (13)

import pandas as pd
import numpy as np
#zip函数可以打包成一个个tuple
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
print tuples
#生成一个多层索引
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
print index
print
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
print
#将列索引变成行索引
print df.stack()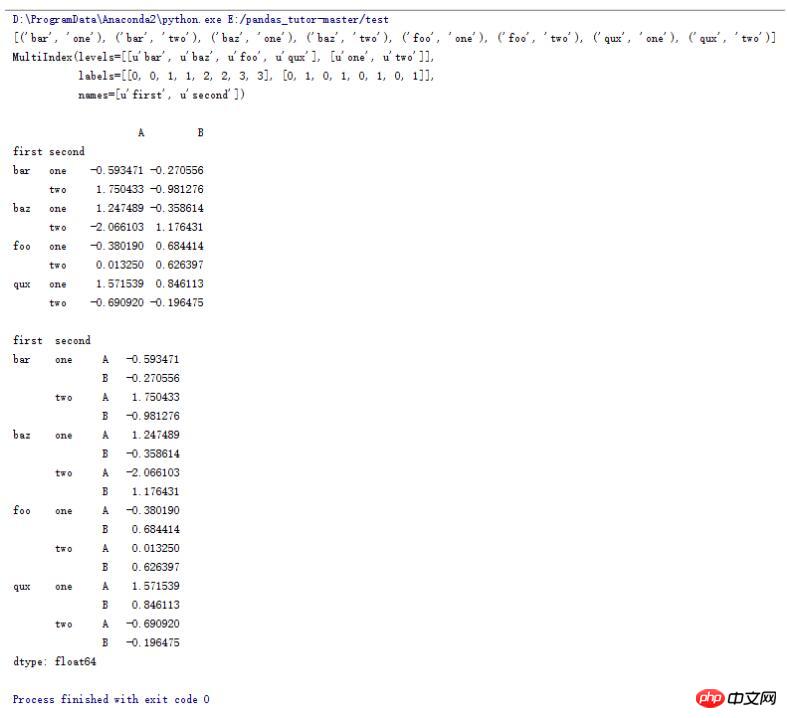
import pandas as pd
import numpy as np
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
print df
print
stacked = df.stack()
print stacked
#将行索引转换为列索引
print stacked.unstack()
#转换两次
print stacked.unstack().unstack()##17. Some operations of DataFrame (15)

import pandas as pd
import numpy as np
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
print df
#根据A,B索引为行,C的索引为列处理D的值
print pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
#感觉A列等于one为索引,根据C列组合的平均值
print df[df.A=='one'].groupby('C').mean()
18.时间序列(1)
import pandas as pd import numpy as np #创建一个以20170220为基准的以秒为单位的向前推进600个的时间序列 rng = pd.date_range('20170220', periods=600, freq='s') print rng #以时间序列为索引的序列 print pd.Series(np.random.randint(0, 500, len(rng)), index=rng)

19.时间序列(2)
import pandas as pd import numpy as np rng = pd.date_range('20170220', periods=600, freq='s') ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng) #重采样,以2分钟为单位进行加和采样 print ts.resample('2Min', how='sum') #列出2011年1季度到2017年1季度 rng1 = pd.period_range('2011Q1','2017Q1',freq='Q') print rng1 #转换成时间戳形式 print rng1.to_timestamp() #时间加减法 print pd.Timestamp('20170220') - pd.Timestamp('20170112') print pd.Timestamp('20170220') + pd.Timedelta(days=12)

20.数据类别
import pandas as pd
import numpy as np
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
print df
#添加类别数据,以raw_grade的值为类别基础
df["grade"] = df["raw_grade"].astype("category")
print df
#打印类别
print df["grade"].cat.categories
#更改类别
df["grade"].cat.categories = ["very good", "good", "very bad"]
print df
#根据grade的值排序
print df.sort_values(by='grade', ascending=True)
#根据grade排序显示数量
print df.groupby("grade").size()
21.数据可视化
import pandas as pd import numpy as np import matplotlib.pyplot as plt ts = pd.Series(np.random.randn(1000), index=pd.date_range('20170220', periods=1000)) ts = ts.cumsum() print ts ts.plot() plt.show()

22.数据读写
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD')) #数据保存,相对路径 df.to_csv('data.csv') #数据读取 print pd.read_csv('data.csv', index_col=0)

数据被保存到这个文件中:

打开看看:

相关推荐:
python解决pandas处理缺失值为空字符串的问题_python
The above is the detailed content of Basic operation methods of Python data analysis library pandas_python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
