

当前位置: 首页 > 爬虫
-

使用 Python 进行网页数据抓取:基础教程与最佳实践
本文档旨在提供一份关于如何使用Python进行网页数据抓取的简明教程。我们将介绍使用requests和BeautifulSoup4库来抓取和解析网页的基本步骤,并提供示例代码。同时,强调了在进行网页抓取时需要注意的法律、道德和技术方面的考量,以确保负责任和高效的数据获取。
Python教程 6612025-09-07 11:17:27
-
RSS验证工具哪个好用?
W3CFeedValidationService是RSS验证的行业标准,推荐作为首选工具,因其权威、免费且能精准定位错误;结合浏览器扩展用于快速检查,开发者可利用Python库或CI/CD集成实现自动化验证,确保feed兼容性、数据完整性并避免解析问题。
XML/RSS教程 3192025-09-07 08:23:02
-

Python中的协程(Coroutine)和异步编程是如何工作的?
答案:调试和优化Python异步代码需理解事件循环、使用asyncio内置工具、避免阻塞调用、合理管理任务与异常。具体包括:利用asyncio.run()和日志监控协程执行;用asyncio.create_task()并发运行任务并捕获异常;避免在协程中调用time.sleep()等阻塞函数,改用asyncio.sleep();使用异步数据库和HTTP客户端(如asyncpg、httpx);通过asyncio.gather()并发等待多个协程;分析性能瓶颈时结合cProfile和aiomonit
Python教程 8472025-09-06 14:32:01
-

大规模数据抓取时的性能优化与去重
大规模数据抓取需兼顾性能优化与数据去重,前者通过异步并发、代理管理、高效解析和分布式架构提升效率,后者采用唯一标识、数据库唯一索引、Redis缓存、布隆过滤器及内容相似度算法实现多层级去重,在实际应用中常结合布隆过滤器快速过滤、Redis精确去重、数据库最终校验的分层策略,同时利用异步编程提升I/O效率,避免阻塞操作,实现高效稳定的数据采集。
Python教程 9892025-09-06 14:19:02
-

DedeCMS列表页如何优化?列表分页怎么改进?
DedeCMS列表页优化需从数据库、缓存、模板和前端四方面入手,核心是提升加载速度与用户体验。首先确保arclist标签的where条件利用索引,避免全表扫描;其次启用静态化或使用cacheid缓存数据块,减少重复查询;再者精简HTML结构,合并CSS/JS,启用图片懒加载;最后通过AJAX加载更多或无限滚动改进分页体验,兼顾SEO需保留静态分页链接或添加rel="next/prev"。修改GetPageList函数可实现智能页码显示,仅展示当前页附近页码,提升界面简洁度。合理利用DedeCMS
DEDECMS 3942025-09-06 11:33:02
-

DedeCMS防盗链怎么设置?Referer如何检查?
DedeCMS防盗链需在服务器层面配置,通过Nginx或Apache的Referer检查实现。Nginx使用valid_referers指令定义允许域名,配合$invalid_referer变量返回403或重定向;Apache则通过.htaccess文件中的RewriteCond和RewriteRule设置规则,阻止非法来源访问静态资源。此举可有效节省带宽、保护版权、提升SEO与用户体验。
DEDECMS 3372025-09-06 10:35:01
-

DedeCMS数据统计怎么查看?内容访问量如何分析?
答案:DedeCMS内置统计功能仅提供基础PV数据,准确性受限于缓存、爬虫等因素,建议集成百度统计等第三方工具以获取UV、来源、停留时间等精准数据,并通过分析热门内容、优化标题与内部链接、改善页面体验等方式提升内容质量与运营效果。
DEDECMS 4442025-09-06 09:48:03
-
RSS如何统计订阅量?
RSS无内置订阅统计功能,因协议设计为轻量级内容分发,不追踪用户行为。统计需依赖服务器日志分析、第三方代理服务(如FeedBurner)、嵌入追踪像素或自建代理系统。主要挑战包括:IP与用户非一一对应、爬虫干扰、缓存导致请求缺失、阅读器不加载外部资源等,导致数据仅为近似值,难以精确统计真实订阅量。
XML/RSS教程 7942025-09-06 09:06:03
-

Python批量提取Excel文件中文本框组件里的文本
推荐图书:《Python程序设计(第3版)》,(ISBN:978-7-302-55083-9),作者董付国,由清华大学出版社出版,首次印刷于2020年6月,第6次印刷于2021年1月。这本书是山东省一流本科课程“Python应用开发”的配套教材,并被评为清华大学出版社2020年度畅销图书(其第二版在2019、2020年度同样荣获畅销图书称号)。目录(二级)第1章基础知识/11.1Python版本的选择1.2Python的安装与初步使用1.3使用pip管理扩展库1.4Python的基本知识1.5
Windows系列 7002025-09-06 08:46:39
-
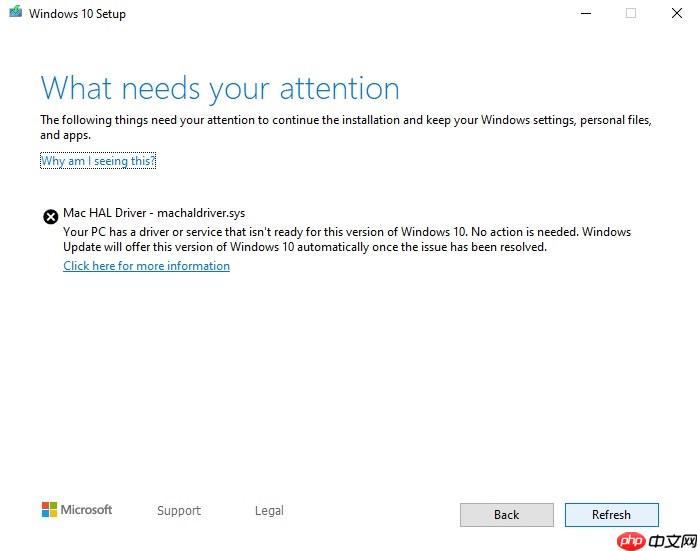
Win10 1903被阻止安装在旧款Mac设备上
微软今日发布声明称,BootCamp软件已经暂停了部分旧款Mac设备对Windows101903版本的更新。此措施将影响2012年以前发布的Mac设备。尽管微软在一份支持页面上披露了这一信息,但该页面并不容易通过搜索引擎找到,因为微软特意阻止了网络爬虫对其进行索引。在支持文档中,微软提到,由于存在兼容性问题,Windows10五月份的更新可能无法顺利安装在较老的Mac设备上。微软还指出,受影响的用户可能会遭遇更新中断,并收到类似“MacHALDriver-machaldriver.sys:
Windows系列 6122025-09-06 08:37:10
-

如何理解Python的并发与并行?
答案:Python中并发指任务交错执行,看似同时运行,而并行指任务真正同时执行;由于GIL限制,多线程无法实现CPU并行,仅适用于I/O密集型任务,而真正的并行需依赖multiprocessing或多核支持的底层库。
Python教程 3122025-09-05 23:25:02
-

如何用Python解析HTML(BeautifulSoup/lxml)?
答案是BeautifulSoup和lxml各有优势,适用于不同场景。BeautifulSoup容错性强、API直观,适合处理不规范HTML和快速开发;lxml基于C实现,解析速度快,适合处理大规模数据和高性能需求。两者可结合使用,兼顾易用性与性能。
Python教程 8122025-09-05 22:44:02
-

如何在PHP中实现文件下载?通过header设置强制下载文件
答案:通过设置Content-Type和Content-Disposition等HTTP头,结合readfile()输出文件,可强制浏览器下载文件;直接链接可能因MIME类型被识别而内联打开;大文件需注意执行时间、内存限制及流式传输;安全方面须验证权限、防止路径遍历,并将文件存于Web目录外。
php教程 7032025-09-05 22:23:02
-

协程(Coroutine)与 asyncio 库在 IO 密集型任务中的应用
协程通过asyncio实现单线程内高效并发,利用事件循环在IO等待时切换任务,避免线程开销,提升资源利用率与并发性能。
Python教程 7892025-09-05 22:17:02
-

如何用Python实现一个简单的爬虫?
答案:使用Python实现简单爬虫最直接的方式是结合requests和BeautifulSoup库。首先通过requests发送HTTP请求获取网页HTML内容,并设置headers、超时和编码;然后利用BeautifulSoup解析HTML,通过CSS选择器提取目标数据,如文章标题和链接;为避免被封IP,应遵守robots.txt协议、控制请求频率、添加time.sleep()延时,并妥善处理异常。对于动态网页,需引入Selenium模拟浏览器行为,等待JavaScript渲染后再提取数据。同
Python教程 2952025-09-05 21:22:02
-

如何应对反爬虫策略?IP 代理与用户代理池
IP代理与用户代理池协同工作可有效应对反爬虫,通过模拟多样化真实用户行为,结合高质量代理管理、请求头一致性、无头浏览器及Cookie会话控制等策略,提升爬虫隐蔽性与稳定性。
Python教程 9682025-09-05 21:16:02
社区问答
-

vue3+tp6怎么加入微信公众号啊
阅读:5015 · 6个月前
-

老师好,当客户登录并立即发送消息,这时候客服又并不在线,这时候发消息会因为touid没有赋值而报错,怎么处理?
阅读:6053 · 7个月前
-
RPC模式
阅读:5029 · 7个月前
-
insert时,如何避免重复注册?
阅读:5841 · 9个月前
-
vite 启动项目报错 不管用yarn 还是cnpm
阅读:6435 · 10个月前















最新文章
-
html 如何多个页面_HTML多页面导航与链接(index.html关联)方法
阅读:663 · 41分钟前
-
html源码如何保存到桌面_html源码保存至桌面文件夹的方法
阅读:346 · 41分钟前
-
Win7拨号711错误解决方法
阅读:493 · 41分钟前
-
todesk远程后分辨率不正常怎么调_todesk分辨率调节方法
阅读:516 · 42分钟前
-
《edge浏览器》阻止广告弹窗设置方法
阅读:691 · 42分钟前
-
edge浏览器怎么清除自动填充的表单数据_Edge表单数据管理教程
阅读:591 · 42分钟前
-
Yandex浏览器与搜索引擎使用方法 Yandex官方中文版账号登录教程
阅读:523 · 42分钟前
-
云闪付扫码付款能否追回
阅读:383 · 43分钟前
-
《冀云》修改用户名方法
阅读:562 · 43分钟前
-
图片点击变换效果实现指南:从CSS到JavaScript
阅读:167 · 43分钟前



