

当前位置: 首页 > 爬虫
-

使用Python脚本连接网页并尝试组合
本文旨在指导读者如何使用Python脚本连接到网页,并尝试通过生成随机组合来模拟暴力破解优惠券代码的过程。通过搭建一个简单的本地Web服务器,并编写Python脚本向该服务器发送请求,演示了如何实现代码与网页的交互,并探讨了优化代码和提高效率的方法。文章还强调了实际应用中可能遇到的限制和伦理问题。
html教程 2952025-09-14 17:14:01
-

Go并发编程中nil指针解引用错误解析与优雅处理:以网络爬虫为例
本教程深入剖析Go语言并发程序中常见的nil指针解引用错误,特别是在处理http.Get等可能返回nil资源的函数时。通过一个网络爬虫的案例,详细解释了defer语句的错误放置如何导致运行时恐慌,并提供了正确的错误处理模式和资源清理的最佳实践,旨在帮助开发者编写更健壮、更可靠的Go并发应用。
Golang 9972025-09-14 13:09:28
-

Next.js 条件渲染中如何确保默认组件的服务器端渲染
在Next.js应用中,基于React.useState的条件渲染默认情况下无法实现服务器端渲染(SSR),因为useState的初始值在客户端初始化。为确保条件渲染的默认组件能够被服务器端渲染以优化SEO,核心解决方案是利用getServerSideProps在服务器端预设初始状态值,并将其作为props传递给组件,从而使useState在组件初始化时使用服务器提供的状态。
js教程 9962025-09-14 12:26:00
-

GoogleAI视频生文怎么用于市场分析_GoogleAI视频生文市场分析应用实例
利用AI技术解决视频内容处理难题,首先通过Veo3生成竞品广告模拟视频,结合焦点小组反馈预测市场反应;接着用Gemini2.5Pro解析社交媒体视频,提取核心卖点、情绪倾向与视觉符号;再借助GeminiDiffusion批量生成多样化脚本并联动Veo3产出预览视频,加速创意迭代;最后构建自动化监测管道,集成GoogleAIStudio实现全流程视频数据抓取、分析与趋势预警,提升市场洞察效率。
人工智能 2432025-09-14 11:45:01
-

Python API获取分类随机词汇:理解API限制与选择策略
本教程探讨了在Python项目中使用requests模块从API获取特定类别随机词汇的问题。通过分析流行的random-word-api.herokuapp.com,我们发现并非所有API都支持类别过滤功能。文章将深入解释为何尝试失败,并强调查阅API文档的重要性,以及在遇到功能限制时如何选择合适的API或替代方案,以确保项目需求得以实现。
Python教程 2642025-09-14 10:33:15
-
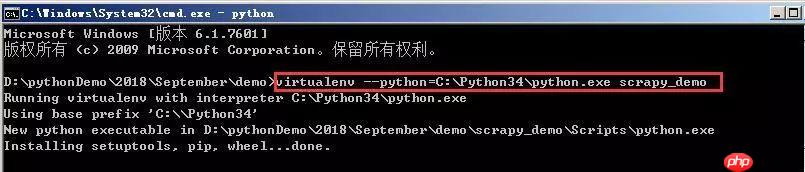
在windows下如何新建爬虫虚拟环境和进行Scrapy安装
Scrapy是一款由Python开发的高效、高层次的屏幕抓取和网络抓取框架,用于从网站中提取结构化数据。Scrapy之所以吸引人,是因为它是一个框架,用户可以根据自己的需求进行灵活的调整。Scrapy的应用范围很广,包括数据挖掘、监控和自动化测试。1、关于虚拟环境的创建,可以参考之前发布的两篇博文,介绍了在Windows下如何创建指定的虚拟环境以及如何创建默认的虚拟环境。接下来,在指定的文件夹下创建环境,命令行为“virtualenv--python=C:Python34python.exesc
Windows系列 7892025-09-14 08:59:29
-
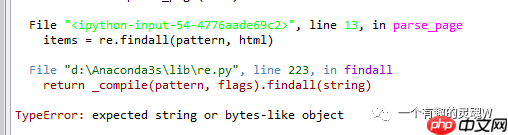
入门爬虫,不讲道理,只摆问题
其实我也算是入门爬虫,目前也还有很多东西没有吃透,比如很多人入门选择使用的正则式我就没记清楚,对于很多反扒也并不算特别深入。但这并不影响我学习爬虫的信心和兴趣。。。没办法,必须要学啊。很多数据我不能跪着求别人给,因为别人不会给。。。被逼着学习爬虫,希望我的学习能有好结果吧importjsonimportreimportrequestsfromrequestsimportRequestExceptionurl="https://movie.douban.com/cinema/nowplayi
Windows系列 4612025-09-14 08:17:16
-

Python怎么实现多线程_Python多线程编程入门指南
Python多线程通过threading模块实现,适用于I/O密集型任务。尽管GIL限制了CPU密集型任务的并行执行,但在I/O操作时会释放GIL,允许多线程并发提升性能。使用Lock可避免共享数据的竞态条件,确保操作原子性;而queue.Queue提供线程安全的数据交换机制,适用于生产者-消费者模型等场景,降低线程耦合,提升程序健壮性。
Python教程 7682025-09-13 20:35:01
-

php如何判断访问来源是移动设备还是PC php检测客户端设备类型技巧
答案是通过解析HTTP_USER_AGENT字符串可判断设备类型。核心方法为:利用PHP的$_SERVER['HTTP_USER_AGENT']获取客户端标识,通过关键词匹配(如Mobile、Android、iPhone)区分移动设备与PC;基础函数可用stripos遍历关键词实现,但存在伪造、新设备兼容性等问题;推荐使用Mobile_Detect等第三方库,其内置完整规则库,支持精准识别设备类型、操作系统及浏览器,提升准确率与开发效率。
php教程 6192025-09-13 14:40:02
-

Python怎么用Beautiful Soup解析HTML_Beautiful Soup HTML解析实战教程
答案:BeautifulSoup通过解析HTML为结构化对象,结合find、find_all和select等方法高效定位元素,可与Selenium配合处理动态内容,并需注意编码、容错、性能及反爬策略。
Python教程 8942025-09-13 13:06:01
-

如何在Linux中批量下载 Linux wget递归下载技巧
使用wget递归下载需结合-r与-np、-A、-R等参数控制范围和过滤文件,如wget-r-np-A".pdf"-R".html"指定下载PDF并排除HTML,同时用--limit-rate限速、-U伪装浏览器,避免过度请求或被拦截,确保高效精准抓取目标内容。
linux运维 1612025-09-13 11:28:01
-

python如何实现多进程编程_python multiprocessing模块多进程编程实践
Python多进程编程依赖multiprocessing模块,通过Process类或Pool进程池实现并行计算,有效规避GIL限制,适用于CPU密集型任务。
Python教程 10182025-09-12 19:41:01
-

python怎么实现多线程或多进程_python多线程与多进程编程入门
多线程适用于IO密集型任务,因GIL在IO等待时释放,可实现高效并发;多进程则通过独立解释器绕过GIL,适合CPU密集型任务实现真正并行,但存在内存开销大、IPC复杂等问题。
Python教程 10152025-09-12 15:47:01
-

应对动态网页抓取挑战:通过内部API获取稳定HTML数据
本教程深入探讨了网络爬虫在抓取动态网页时,因HTML结构不一致而导致失败的常见问题。针对IBM文档网站的案例,我们揭示了直接请求可能返回不完整或错误页面的原因,并提供了一种通过识别并调用网站内部API来稳定获取目标数据(特别是表格数据)的专业解决方案,确保爬取过程的可靠性和效率。
js教程 7852025-09-12 12:57:00
-

Python怎么发送HTTP请求_Python HTTP请求发送实践指南
Python发送HTTP请求最推荐使用requests库,它封装了GET、POST、认证、会话管理等操作,API简洁易用。首先安装:pipinstallrequests。发送GET请求获取数据:importrequests;response=requests.get('https://api.github.com/events');print(response.status_code,response.json()[:3])。发送POST请求提交数据:requests.post('https:/
Python教程 9232025-09-12 11:38:01
-

应对动态网页爬取中HTML结构不一致的策略
在网页抓取过程中,由于网站采用动态内容加载或内部API调用,同一页面可能返回不同的HTML结构,导致传统解析方法失效。本文将深入探讨这一常见问题,并提供一套基于异步HTTP请求和API调用的解决方案,利用httpx、trio和pandas等库,实现稳定高效的数据提取,特别适用于处理复杂网站的表格数据。
js教程 2582025-09-12 10:36:01
社区问答
-

vue3+tp6怎么加入微信公众号啊
阅读:5015 · 6个月前
-

老师好,当客户登录并立即发送消息,这时候客服又并不在线,这时候发消息会因为touid没有赋值而报错,怎么处理?
阅读:6053 · 7个月前
-
RPC模式
阅读:5029 · 7个月前
-
insert时,如何避免重复注册?
阅读:5841 · 9个月前
-
vite 启动项目报错 不管用yarn 还是cnpm
阅读:6435 · 10个月前















最新文章
-
C# 如何在 EF Core 中执行原生 SQL 查询_C# EF Core 原生 SQL 查询方法
阅读:386 · 24分钟前
-
qq音乐在线播放入口 qq音乐网页版官方网站入口
阅读:632 · 24分钟前
-
曝小米eSIM手机/平板已在路上!
阅读:523 · 24分钟前
-
win11怎么检查内存条是否有问题_Windows 11内存检测教程
阅读:390 · 24分钟前
-
小红书搜索不到热门笔记如何解决
阅读:363 · 25分钟前
-
Doctrine 原生SQL与存储过程调用:弃用方法替代方案详解
阅读:749 · 25分钟前
-
CSS块级元素水平居中指南:掌握 margin: auto; 的应用
阅读:481 · 25分钟前
-
天猫双11主会场入口2025活动页面及领券入口
阅读:925 · 26分钟前
-
铁路12306车票已出票是什么意思_铁路12306车票已出票状态解析
阅读:184 · 26分钟前
-
使用JavaScript和HTML5实现Div内容保存与加载的教程
阅读:394 · 26分钟前



