

-

- PHP 函数在人工智能和机器学习中的潜在应用?
- PHP在AI和ML中的应用包括:数学运算函数:进行双曲运算、取绝对值、四舍五入和比较。字符串处理函数:预处理文本数据、提取特征和执行NLP任务。数据结构类:存储和组织数据,例如数组、集合、栈和队列。结合ML算法,这些函数可用于构建模型,例如预测客户流失。
- web前端 . regular-expression 467 2024-10-02 10:24:01
-

- 小白怎么学习python爬虫
- 网络爬虫是一种从网站收集数据的自动化工具。小白学习 Python 爬虫的步骤包括:掌握 Python 基础;安装 Requests、BeautifulSoup 和 Selenium 等库;了解 HTML 和 CSS;编写第一个爬虫程序;处理复杂网站;练习和构建项目。
- web前端 . regular-expression 525 2024-10-02 08:00:53
-

- 怎么用python爬虫数据
- 使用 Python 爬虫爬取数据分五步进行:选择爬虫库(BeautifulSoup、Scrapy、Requests、Selenium)解析 HTML 文档提取所需数据保存数据自动化爬取
- web前端 . regular-expression 465 2024-10-02 07:09:42
-

- python爬虫怎么解析html
- HTML解析是Python爬虫获取网页结构和数据的重要步骤。通常使用BeautifulSoup库解析HTML,步骤如下:安装BeautifulSoup库。使用BeautifulSoup解析HTML。访问HTML元素,包括find()/find_all()和select()。提取数据,包括使用.text和.attrs。
- web前端 . regular-expression 526 2024-10-02 07:00:55
-

- python爬虫怎么获取变量
- 使用 Selenium 通过执行 JavaScript 代码获取变量值。使用 Beautiful Soup 从 HTML 元素中提取 JavaScript 代码,然后使用 eval() 函数获取变量值。使用正则表达式从网页中匹配 JavaScript 变量声明模式,并提取变量值。
- web前端 . regular-expression 512 2024-10-02 06:57:21
-

- python爬虫怎么去换行
- Python爬虫换行方法:1. 使用"\n"转义字符;2. 使用print()函数加逗号;3. 使用splitlines()方法按换行符分隔;4. 使用re.split()正则表达式按换行符分隔。
- web前端 . regular-expression 1174 2024-10-02 06:34:08
-

- python爬虫none怎么解决
- Python爬虫中遇到None值时,解决方案包括:检查URL和选择器、处理动态内容、设置默认值、使用正则表达式和异常处理。例如,如果一个元素不存在或为空,则可以设置默认值以避免返回None。
- web前端 . regular-expression 533 2024-10-02 06:31:19
-

- python爬虫速度怎么调
- 优化 Python 爬虫速度技巧包括:使用多线程或多进程提高并发处理能力;缓存响应和优化请求以减少请求次数和响应大小;使用库优化页面解析,避免使用正则表达式;采取其他优化技巧,如使用 CDN、避免递归爬取、分布式爬取和性能分析。
- web前端 . regular-expression 325 2024-10-02 06:21:20
-

- python爬虫怎么删除空格
- 在 Python 爬虫中删除空格有以下方法:正则表达式:使用 \s+ 正则表达式匹配空格并替换为空字符串strip() 方法:从字符串开头和结尾删除空格replace() 方法:将空格替换为空字符串split() 和 join() 方法:将字符串拆分为单词列表,并用指定分隔符连接lstrip() 和 rstrip() 方法:从字符串开头或结尾删除空格
- web前端 . regular-expression 1202 2024-10-02 06:10:01
-

- python爬虫怎么抓取号码
- 可以使用 Python 爬虫抓取号码,具体方法包括:使用正则表达式,例如 r"^\d{3}-\d{3}-\d{4}$" 来匹配电话号码。使用 HTML 解析库(如 BeautifulSoup)从 HTML 元素中提取数字,例如 soup.find_all("a")。
- web前端 . regular-expression 1314 2024-10-02 05:46:15
-

- 怎么提高python爬虫技术
- 通过掌握 Python 基础、HTTP/HTTPS 协议和爬虫库,以及通过实践、处理挑战和获取进阶技巧,可以有效提升 Python 爬虫技术。
- web前端 . regular-expression 1052 2024-10-02 05:36:33
-

- 怎么用python爬虫
- 如何使用 Python 爬虫?安装请求、BeautifulSoup 和 lxml 库。发送 HTTP 请求获取网站 HTML 内容,解析 HTML 提取数据。存储或处理提取的数据,注意遵守网站使用条款、管理并发和规避反爬虫措施,并考虑伦理影响。
- web前端 . regular-expression 818 2024-10-02 05:24:17
-

- 爬虫python怎么用
- Python 爬虫是一种利用 Python 自动化从网站提取数据的工具。步骤如下:安装 bs4、requests、lxml 库。使用 requests 库连接到目标网站。使用 bs4 库解析 HTML。通过标签、CSS 选择器或正则表达式提取数据。清理、转换和存储提取的数据。最佳实践包括尊重 robots.txt、限制爬取频率、处理错误、使用代理和遵守网站条款。
- web前端 . regular-expression 597 2024-10-02 05:21:22
-

- 函数式编程中的 lambda 表达式如何处理异常?
- 在函数式编程中,Lambda表达式异常处理有三种方法:抛出异常、使用try-catch块、使用ErrorHandling函数。其中,抛出异常将执行流传递回调用Lambda表达式的代码,try-catch块允许在Lambda表达式内部处理异常,ErrorHandling函数允许Lambda表达式以声明方式处理异常。实战案例中,代码使用try-catch块处理文本文件中的正则表达式匹配异常,并在匹配失败时将行打印到标准错误流中。
- web前端 . regular-expression 645 2024-10-01 20:45:02
-

- PHP 函数版本更新指南:面向未来的演变
- PHP函数版本不断更新,使用以下格式表示:_。更新类型有:新函数、功能增强、性能优化、错误修复、弃用和删除。例如,str_replace_7.4表示str_replace函数的版本7.4。此版本添加了新选项'e',允许使用正则表达式进行替换,并引入了$count参数来跟踪替换次数。
- web前端 . regular-expression 337 2024-09-30 17:27:02

PHP讨论组
组员:3305人话题:1500
PHP一种被广泛应用的开放源代码的多用途脚本语言,和其他技术相比,php本身开源免费; 可以将程序嵌入于HTML中去执行, 执行效率比完全生成htmL标记的CGI要高许多,它运行在服务器端,消耗的系统资源相当少,具有跨平台强、效率高的特性,而且php支持几乎所有流行的数据库以及操作系统,最重要的是








工具推荐






WOBIZ电子商务2.0程序
WO@BIZ电子商务2.0软件是窝窝团队基于对互联网发展和业务深入研究后,采用互联网2.0的思想设计、开发的电子商务和社会化网络(SNS)结合的解决方案产品。WOBIZ是互联网2.0创业、传统网站转型、中小企业宣传产品网应用的最佳选择。 它精心设计的架构、强大的功能机制、友好的用户体验和灵活的管理系统,适合从个人到企业各方面应用的要求,为您提供一个安全、稳定、高效、 易用而快捷的电子商务2.0网络解决方案。WO@BIZ包括用户秀系统(Space)、产品秀系统(Blog)、群组系统(Group)、交友应用
电商源码
2025-10-27
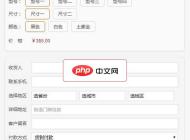
H5竞价在线订单系统1.0
H5竞价在线订单系统是以php进行开发的在线订单网站源码。竞价单页一直都是比较火爆的一类源码,很多做产品竞价的朋友几乎都会找这样的源码,因为做搜索引擎的竞价推广,如果人工一一对接的话会很累,而且可能下单量要少得多,但是使用竞价单页就不一样了,很多消费者从竞价单页上看完产品介绍以后,直接就填写信息然后下单了,这样就可以让自己的订单滚滚而来。
企业站源码
2025-10-27
发货100简约发卡系统
发货100简约发卡系统(含小程序)是一套功能强大的在线视频课程教育系统/文章付费阅读系统,无需人工值守,客户在线购买即可自动完成交易。支持缺货提醒/快捷登录/回收站/免登录购买等多种功能。
电商源码
2025-10-27


马赛克风格音乐节广告海报设计下载
马赛克风格音乐节广告海报设计适用于音乐节广告海报设计 本作品提供马赛克风格音乐节广告海报设计的图片会员免费下载,格式为PSD,文件大小为1.5M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27


万圣节主题活动方形海报ps素材下载
万圣节主题活动方形海报ps素材适用于万圣节主题活动海报设计 本作品提供万圣节主题活动方形海报ps素材的图片会员免费下载,格式为PSD,文件大小为34.0M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27

驾照考试驾校HTML5网站模板
驾照考试驾校HTML5网站模板是一款适合提供驾驶培训和组织驾照考试服务机构宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-06-10

驾照培训服务机构宣传网站模板
驾照培训服务机构宣传网站模板是一款适合提供一般驾驶和计划培训的驾校宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-07


HTML5房地产公司宣传网站模板
HTML5房地产公司宣传网站模板是一款适合从事房地产服务行业宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-06






