

-

- sed命令如何分段提取行
- sed 命令可通过正则表达式分段提取文件行的内容。语法:sed -n '/<pattern1>/,/<pattern2>/p' file.txt。示例:'/BEGIN/,/END/p' 提取以 "BEGIN" 开头、以 "END" 结尾的段落。高级用法:可使用多个正则表达式模式,例如 '/paragraph/p' 提取包含 "paragraph" 一词的段落。扩展用例:找出重复段落、提取特定格式数据、编辑分段内容。
- web前端 . regular-expression 1278 2024-10-05 22:48:25
-

- PHP 函数在项目开发中的应用场景有哪些?
- PHP函数在项目开发中广泛用于:数据处理(如获取日期、转换大小写、转义命令)输入验证(如过滤数据、检查数据类型、验证正则表达式)字符串操作(如截取、替换、重复)数组操作(如合并、检查键、求差异)数学运算(如四舍五入、求最大最小值、计算平方根)
- web前端 . regular-expression 727 2024-10-05 19:09:02
-

- PHP 函数面试题库精选及答案解析
- 问题:列举10个PHP函数面试题及其答案。array_map()函数的作用?array_map(callback,array,...arrayN);返回回调函数在每个数组元素上执行后的新数组。替换字符串中所有空格的代码?$new_string=str_replace("","",$string);implode()函数用法?implode(separator,array);将数组元素连接成字符串,使用指定的separator分隔。preg_match()函数用于?preg_match(patte
- web前端 . regular-expression 638 2024-10-05 14:45:02
-

- 命令行如何查找文件内容
- 使用命令行查找文件内容可以采用两种方法:grep 命令:grep [选项] 模式 文件find 命令:find [路径] -exec grep [选项] 模式 {} \;
- web前端 . regular-expression 1176 2024-10-05 13:18:46
-

- PHP 函数在人工智能技术中的运用
- PHP函数在人工智能技术中发挥着重要作用,特别是以下几个方面:机器学习:array_slice()和array_map()用于处理数据集。自然语言处理:preg_match()和preg_replace()用于文本处理。图像处理:imagecreatefromjpeg()和imagejpeg()用于图像操作。计算机视觉:gd_transform()和gd_affine()用于图像变换。深度学习:PHP可与TensorFlow和Keras等第三方库集成,用于构建和训练神经网络。
- web前端 . regular-expression 1136 2024-10-04 16:36:02
-
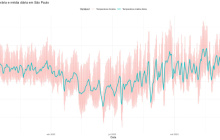
- 收集和处理 INMET-BDMEP 气候数据
- 气候数据在多个领域发挥着至关重要的作用,有助于影响农业、城市规划和自然资源管理等领域的研究和预测。国家气象研究所(inmet)每月在其网站上提供气象数据库(bdmep)。该数据库包含分布在巴西各地的数百个测量站收集的一系列历史气候信息。在bdmep中,您可以找到有关降雨量、温度、空气湿度和风速的详细数据。每小时更新一次,数据量相当大,为详细分析和明智决策提供了丰富的基础。在这篇文章中,我将展示如何从inmet-bdmep收集和处理气候数据。我们将收集inmet网站上提供的原始数据文件,然后处理这
- web前端 . regular-expression 724 2024-10-03 18:45:01
-

- PHP 函数在监控和告警系统中的应用场景
- PHP函数在监控和告警系统中发挥着至关重要的作用,提供了以下功能:实时监控:执行系统命令并返回输出,转义shell参数,执行shell命令但不返回输出。日志分析:解析INI文件,读取文件内容,使用正则表达式匹配日志消息。告警生成:发送电子邮件,使用SMTP发送电子邮件,使用HTTP请求发送数据。
- web前端 . regular-expression 953 2024-10-03 10:21:11
-

- python爬虫很多换行怎么办
- 使用Python爬虫处理多行文本的技术包括:使用strip()方法去除换行符。使用re.sub()方法根据正则表达式替换换行符。使用BeautifulSoup的get_text()和strip()方法。定义自定义函数拆分多行文本。使用join()、split()或read()等其他方法。
- web前端 . regular-expression 887 2024-10-02 18:43:14
-

- python爬虫怎么获取网站日志
- 推荐使用 Python 爬虫获取网站日志,具体步骤如下:确定日志位置,通常在网站服务器上。使用 FTP 或 SSH 访问服务器,并导航到日志文件的位置。下载日志文件到本地计算机。使用 re、csv 和 paramiko 等 Python 库解析日志文件以提取所需信息。
- web前端 . regular-expression 468 2024-10-02 18:27:53
-

- python爬虫怎么只保留文字
- 使用 Python 爬虫时,保留网页文本而不包含 HTML 标签的方法有两种:使用 BeautifulSoup 库,调用其 get_text() 方法获取文本内容。使用正则表达式匹配并替换 HTML 标签,提取纯文本内容。
- web前端 . regular-expression 453 2024-10-02 18:27:21
-

- python爬虫怎么防止入坑
- 常见的 Python 爬虫陷阱及解决方案:过度抓取:使用礼貌延时并避免违反网站指示。IP 被封:使用代理或 Tor 网络隐藏 IP 地址。动态加载内容:使用 Selenium 模拟浏览器抓取 JavaScript 内容。正则表达式滥用:仔细设计并测试正则表达式,或使用其他解析方法。HTML 结构变化:监控并调整爬虫以适应 HTML 变化。数据重复:使用哈希值或 Bloom 过滤器过滤重复数据。脚本效率低:优化脚本性能并有效利用多线程/多进程。法律和道德问题:遵守网站使用条款和法律限制,仅抓取
- web前端 . regular-expression 565 2024-10-02 18:21:54
-

- python爬虫怎么学最牛逼
- 成为一名优秀的 Python 爬虫开发者的步骤:掌握 Python 基础知识,包括语法、数据结构、算法、库和并发性。熟悉 HTML 和 CSS 结构和语法,并学习使用XPath、CSS选择器和正则表达式解析和提取数据。从简单到复杂的爬虫项目实战,分析网站结构并制定有效策略。使用代理和标头避免检测,实现延迟和礼貌限制,优化代码提高效率。利用 Python 库处理和存储数据,清洗和规范数据提高质量,考虑使用数据库或云存储存储大规模数据。持续学习和改进,关注最新趋势和技术,参与社区交流和优化爬虫代码。
- web前端 . regular-expression 634 2024-10-02 18:03:22
-

- python爬虫怎么处理字符串
- Python 爬虫中的字符串处理技巧包括:1. 字符串拆分;2. 字符串连接;3. 字符串替换;4. 正则表达式;5. HTML 解析。此外,还有字符编码处理、字符过滤、字符转义等补充技巧。这些技术可用于有效地解析和提取网页中的信息。
- web前端 . regular-expression 493 2024-10-02 17:48:49
-

- python爬虫怎么爬span里的内容
- Python爬虫抓取Span内容的方法:使用BeautifulSoup库解析HTML文档通过CSS选择器或正则表达式定位Span元素及其内容
- web前端 . regular-expression 688 2024-10-02 17:36:17
-

- python爬虫出来的信息怎么去样式
- Python 爬虫剔除 HTML 样式信息的方法如下:使用 BeautifulSoup 库的 get_text() 方法剔除 HTML 标记和样式。使用正则表达式匹配并替换 HTML 标记和样式,获得纯文本。使用第三方库 lxml.html.fromstring() 解析 HTML 字符串并遍历元素树获取纯文本。
- web前端 . regular-expression 898 2024-10-02 17:27:44

PHP讨论组
组员:3305人话题:1500
PHP一种被广泛应用的开放源代码的多用途脚本语言,和其他技术相比,php本身开源免费; 可以将程序嵌入于HTML中去执行, 执行效率比完全生成htmL标记的CGI要高许多,它运行在服务器端,消耗的系统资源相当少,具有跨平台强、效率高的特性,而且php支持几乎所有流行的数据库以及操作系统,最重要的是








工具推荐






WOBIZ电子商务2.0程序
WO@BIZ电子商务2.0软件是窝窝团队基于对互联网发展和业务深入研究后,采用互联网2.0的思想设计、开发的电子商务和社会化网络(SNS)结合的解决方案产品。WOBIZ是互联网2.0创业、传统网站转型、中小企业宣传产品网应用的最佳选择。 它精心设计的架构、强大的功能机制、友好的用户体验和灵活的管理系统,适合从个人到企业各方面应用的要求,为您提供一个安全、稳定、高效、 易用而快捷的电子商务2.0网络解决方案。WO@BIZ包括用户秀系统(Space)、产品秀系统(Blog)、群组系统(Group)、交友应用
电商源码
2025-10-27
H5竞价在线订单系统1.0
H5竞价在线订单系统是以php进行开发的在线订单网站源码。竞价单页一直都是比较火爆的一类源码,很多做产品竞价的朋友几乎都会找这样的源码,因为做搜索引擎的竞价推广,如果人工一一对接的话会很累,而且可能下单量要少得多,但是使用竞价单页就不一样了,很多消费者从竞价单页上看完产品介绍以后,直接就填写信息然后下单了,这样就可以让自己的订单滚滚而来。
企业站源码
2025-10-27
发货100简约发卡系统
发货100简约发卡系统(含小程序)是一套功能强大的在线视频课程教育系统/文章付费阅读系统,无需人工值守,客户在线购买即可自动完成交易。支持缺货提醒/快捷登录/回收站/免登录购买等多种功能。
电商源码
2025-10-27


马赛克风格音乐节广告海报设计下载
马赛克风格音乐节广告海报设计适用于音乐节广告海报设计 本作品提供马赛克风格音乐节广告海报设计的图片会员免费下载,格式为PSD,文件大小为1.5M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27


万圣节主题活动方形海报ps素材下载
万圣节主题活动方形海报ps素材适用于万圣节主题活动海报设计 本作品提供万圣节主题活动方形海报ps素材的图片会员免费下载,格式为PSD,文件大小为34.0M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27

驾照考试驾校HTML5网站模板
驾照考试驾校HTML5网站模板是一款适合提供驾驶培训和组织驾照考试服务机构宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-06-10

驾照培训服务机构宣传网站模板
驾照培训服务机构宣传网站模板是一款适合提供一般驾驶和计划培训的驾校宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-07


HTML5房地产公司宣传网站模板
HTML5房地产公司宣传网站模板是一款适合从事房地产服务行业宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-06






