

-

- python爬虫网页解析器怎么写
- Python网页解析器是网络爬虫中的关键组件,用于解析HTML或XML内容并提取信息。解析器可以使用正则表达式或HTML解析库(如BeautifulSoup),通过选择器查找元素并提取其属性来获取所需信息。对于复杂网页,可编写自定义解析器。为了提高性能,可以使用CSS选择器、避免重复解析和缓存解析结果。
- web前端 . regular-expression 1158 2024-10-18 22:49:02
-

- python爬虫div中的信息怎么爬取
- 如何使用 Python 爬虫获取 div 中的信息?使用 requests 库获取网页内容。使用 BeautifulSoup 解析 HTML 内容。找到要获取信息的 div。从 div 中提取所需的信息。
- web前端 . regular-expression 753 2024-10-18 22:42:35
-

- python爬虫是怎么跳过一个td
- 对于Python爬虫中跳过td元素,有四种方法:使用XPath选择器,例如:xpath("//td[position() > 1]")。使用CSS选择器,例如:select("td:not(:first-child)")。使用BeautifulSoup的find_all()方法,例如:find_all("td")[1:]。使用正则表达式,例如:re.findall(r"<td>(1+)</td>&
- web前端 . regular-expression 812 2024-10-18 17:46:19
-

- python爬虫怎么判断出现滑块验证码
- 使用 Python 爬虫检测滑块验证码的方法有:Selenium:自动模拟用户行为,检测并解决验证码。分析页面源代码:提取编码在源代码中的滑块目标位置。第三方库:例如 pytesseract 或 solvecaptcha,识别图像或提供专业求解服务。
- web前端 . regular-expression 939 2024-10-18 17:42:25
-

- python爬虫文本中有很多div怎么办
- 处理 HTML 文本中的大量 div 标签的方法包括:使用正则表达式匹配并提取 div 内容;使用 BeautifulSoup 库导航 HTML 文档并查找 div 标签;使用 HTML 解析器获取 DOM 结构并提取 div 标签。
- web前端 . regular-expression 906 2024-10-18 17:27:25
-

- python怎么清洗爬虫数据
- 清洗爬虫数据是移除原始数据中的错误和不一致性。Python 中清洗爬虫数据的步骤包括:检查数据类型移除重复项处理空值标准化数据验证数据错误处理使用工具定期更新
- web前端 . regular-expression 691 2024-10-18 16:58:23
-

- python爬虫怎么去掉空格
- 可以使用以下方法在 Python 爬虫中去除空格字符:正则表达式替换:使用 re.sub() 函数匹配并替换空格字符。字符串方法:使用 strip()、replace() 或 split() 方法去除空格字符。
- web前端 . regular-expression 1222 2024-10-18 16:33:55
-

- Python怎么写爬虫脚本
- 使用 Python 编写爬虫脚本:安装 Beautiful Soup、requests 和 Selenium 库。确定要爬取的网站或页面。使用 Beautiful Soup 解析 HTML 提取所需数据。使用 requests 发送 HTTP 请求获取页面。使用正则表达式或 XPath 匹配和提取特定数据。将提取的数据存储在数据库、文件中或其他存储介质中。
- web前端 . regular-expression 946 2024-10-18 16:03:37
-

- python怎么提升爬虫效率
- 提升 Python 爬虫效率的方法包括:使用并发技术(多进程、多线程、线程池);优化请求(批量处理、异步 HTTP 客户端);缓存机制;解析优化(正则表达式、HTML 解析库);优化网络(高速连接、代理);避免重复追踪;利用数据库存储结果;限制并发级别;遵守机器人协议;使用爬虫库或框架。
- web前端 . regular-expression 806 2024-10-18 16:00:41
-

- python下标文字怎么爬虫
- 在Python中,爬取下标文字有三种方法:使用BeautifulSoup库,通过find_all('sub')查找包含下标文字的元素并提取text属性。使用Selenium库,通过find_elements_by_css_selector('sub')查找包含下标文字的元素并提取text属性。使用re(正则表达式)模块,通过findall()匹配子序列并提取group(1)属性。
- web前端 . regular-expression 885 2024-10-18 15:58:11
-

- 怎么找python爬虫工作
- 为获得 Python 爬虫工作,需要:掌握 Python 编程、网络请求库、并发性编程、数据处理技能。积累个人项目和开源贡献经验。建立人际网络、使用求职平台,寻找职位空缺。准备面试,展示技能和经验。提升竞争力,获得认证、持续学习并分享知识。
- web前端 . regular-expression 446 2024-10-18 15:57:48
-

- 怎么学好python网络爬虫
- 掌握 Python 网络爬虫的方法:理解 Python 基础知识。学习 requests 和 BeautifulSoup 等网络库。定义目标数据和收集 URL 列表。使用 requests 发送请求。用 BeautifulSoup 解析 HTML 并提取数据。使用正则表达式获取所需信息。存储和处理重复项,并处理错误。考虑道德和法律因素。使用多线程、代理和自定义爬虫以提高效率和满足特定需求。
- web前端 . regular-expression 852 2024-10-18 15:57:21
-

- python爬虫进阶怎么学
- 进阶学习 Python 爬虫需遵循以下步骤:掌握基础:熟悉 Python、HTTP、网页结构,熟练使用爬虫库。提升抓取效率:使用多线程/进程、优化网络请求、应用代理和反爬虫策略。处理复杂网页:解析 JavaScript 动态页面、处理 AJAX 请求数据、应对验证码和反爬虫机制。数据处理和存储:使用正则表达式提取数据、存储数据到数据库/文件/云端、分析大量数据。分布式爬取:了解分布式爬取框架、配置爬虫集群。实践项目:参与开源爬虫项目、构建个人爬虫工具/应用,解决实际问题
- web前端 . regular-expression 772 2024-10-18 15:45:47
-

- python爬虫编写怎么运作
- Python 爬虫的工作原理:发送 HTTP 请求获取目标网页响应;解析 HTML 文档提取结构化数据;按照预定义规则从 HTML 中提取所需数据;将提取的数据存储在持久化存储中;循环处理页面,使用队列或栈跟踪抓取进度;处理抓取过程中发生的异常,保证爬虫稳定性。
- web前端 . regular-expression 560 2024-10-18 15:00:25
-

- python 爬虫单词怎么学
- 学习 Python 爬虫单词的有效策略:了解基础词汇,如 URL、HTML、XPath 和正则表达式。学习技术术语,如 HTTP 状态码、代理、Cookie 和网络爬虫。通过实际编写爬虫代码练习应用词汇。阅读官方文档和教程以获得详细说明。利用在线资源,例如论坛、博客和课程,获取见解和技巧。定期复习词汇以巩固知识和填补空白。
- web前端 . regular-expression 852 2024-10-18 14:42:24

PHP讨论组
组员:3305人话题:1500
PHP一种被广泛应用的开放源代码的多用途脚本语言,和其他技术相比,php本身开源免费; 可以将程序嵌入于HTML中去执行, 执行效率比完全生成htmL标记的CGI要高许多,它运行在服务器端,消耗的系统资源相当少,具有跨平台强、效率高的特性,而且php支持几乎所有流行的数据库以及操作系统,最重要的是








工具推荐






WOBIZ电子商务2.0程序
WO@BIZ电子商务2.0软件是窝窝团队基于对互联网发展和业务深入研究后,采用互联网2.0的思想设计、开发的电子商务和社会化网络(SNS)结合的解决方案产品。WOBIZ是互联网2.0创业、传统网站转型、中小企业宣传产品网应用的最佳选择。 它精心设计的架构、强大的功能机制、友好的用户体验和灵活的管理系统,适合从个人到企业各方面应用的要求,为您提供一个安全、稳定、高效、 易用而快捷的电子商务2.0网络解决方案。WO@BIZ包括用户秀系统(Space)、产品秀系统(Blog)、群组系统(Group)、交友应用
电商源码
2025-10-27
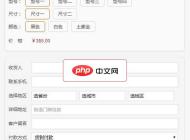
H5竞价在线订单系统1.0
H5竞价在线订单系统是以php进行开发的在线订单网站源码。竞价单页一直都是比较火爆的一类源码,很多做产品竞价的朋友几乎都会找这样的源码,因为做搜索引擎的竞价推广,如果人工一一对接的话会很累,而且可能下单量要少得多,但是使用竞价单页就不一样了,很多消费者从竞价单页上看完产品介绍以后,直接就填写信息然后下单了,这样就可以让自己的订单滚滚而来。
企业站源码
2025-10-27
发货100简约发卡系统
发货100简约发卡系统(含小程序)是一套功能强大的在线视频课程教育系统/文章付费阅读系统,无需人工值守,客户在线购买即可自动完成交易。支持缺货提醒/快捷登录/回收站/免登录购买等多种功能。
电商源码
2025-10-27


马赛克风格音乐节广告海报设计下载
马赛克风格音乐节广告海报设计适用于音乐节广告海报设计 本作品提供马赛克风格音乐节广告海报设计的图片会员免费下载,格式为PSD,文件大小为1.5M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27


万圣节主题活动方形海报ps素材下载
万圣节主题活动方形海报ps素材适用于万圣节主题活动海报设计 本作品提供万圣节主题活动方形海报ps素材的图片会员免费下载,格式为PSD,文件大小为34.0M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27

驾照考试驾校HTML5网站模板
驾照考试驾校HTML5网站模板是一款适合提供驾驶培训和组织驾照考试服务机构宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-06-10

驾照培训服务机构宣传网站模板
驾照培训服务机构宣传网站模板是一款适合提供一般驾驶和计划培训的驾校宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-07


HTML5房地产公司宣传网站模板
HTML5房地产公司宣传网站模板是一款适合从事房地产服务行业宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-06






