

-

- 如何以不同大小写字符时精准计算文本宽度?
- 获取文本宽度的精确方法:使用AutoSizeUI库:它提供autoSize特性来自动调整文本大小。使用CanvasAPI:通过measureText()方法获取文本宽度,不受字体影响。使用正则表达式匹配:提取特定字符类型(如大小写字母)的数量,再乘以字体大小以获取文本宽度。使用等宽字体:每个字符占用相同宽度,可通过正则表达式计算各个字符数量并乘以字体大小获得文本宽度。
- web前端 . regular-expression 1097 2024-10-22 16:44:15
-

- 仅允许数字输入的正则表达式有哪些?
- 对于输入框只允许输入数字(第一位可选负号)的需求,以下三个正则表达式可满足验证需求:允许输入空字符串:^-\d*$必须输入数字且至少一个:^-?\d{1,}$
- web前端 . regular-expression 1226 2024-10-22 10:41:38
-

- 输入框如何限制输入数字?
- 使用正则表达式可以限制输入框只能输入数字,可选第一位为"-"。具体方法如下:^-\d*^:字符串开头可选连字符后跟任意数量数字或空。^-\d{1,}$^:字符串开头可选连字符后跟至少一个数字。
- web前端 . regular-expression 1098 2024-10-22 09:25:52
-

- 正则表达式在文本验证中的常见问题有哪些?
- 文本输入验证中可使用正则表达式,具体为:可选负号,任意数量数字:^-?\d*可选负号,至少一位数字:^-?\d{1,}
- web前端 . regular-expression 688 2024-10-22 08:09:48
-

- java中pattern的用法
- Pattern 类在 Java 中运用正则表达式,匹配指定模式的字符串,广泛用于字符串处理和数据验证。通过编译正则表达式创建 Pattern 对象,可以使用匹配器(Matcher 对象)在字符串中搜索和操作匹配的模式。Pattern 提供方法如 split() 和 flags(),分别用于字符串分割和获取模式标记。Matcher 提供的方法包括 find() 和 matches(),用于在字符串中查找和匹配模式,以及 replaceFirst() 和 replaceAll() 用于替换匹配项。P
- web前端 . regular-expression 1401 2024-10-21 15:32:54
-
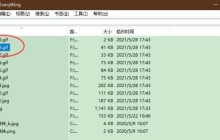
- Everything怎么使用正则条件复制文件
- Everything是一款文件搜索工具,基于名称快速定位文件和文件夹,便捷小巧、界面简洁、高效搜索。有小伙伴知道Everything怎么使用正则条件复制文件吗,下面小编就给大家详细介绍一下Everything使用正则条件复制文件的方法,大家感兴趣的话可以来看一看。操作方法:1、双击打开软件,选中需要复制的文件。2、接着点击上方工具栏中的"编辑"。3、选择下方选项列表中的"高级"。4、然后再点击其中的"高级复制"选项。5、最后在弹出的窗口界面中,找到"正则",将其小方框勾选上,随后点击确定进行保存
- web前端 . regular-expression 931 2024-10-21 15:20:44
-

- top命令如何grep
- 使用 top 命令结合 grep 查找特定进程:输入命令 "top -p PID | grep PATTERN",其中 PID 是进程 ID,PATTERN 是要搜索的模式。grep 支持正则表达式,提高过滤灵活性。可使用选项 "-i"(忽略大小写)、"-c"(显示匹配行数)和 "-v"(显示不包含匹配行的行)来细化输出。
- web前端 . regular-expression 585 2024-10-21 06:28:18
-

- mv命令如何只修改一部分名称
- 使用 mv 命令仅修改一部分文件或目录名称需要:使用 -i 参数提示覆盖确认;使用正则表达式、通配符或其他工具(例如 sed、rename)指定要修改的名称部分。
- web前端 . regular-expression 403 2024-10-21 06:03:22
-

- 新手怎么看懂python爬虫源码
- 理解 Python 爬虫源码的步骤:了解爬虫原理和组件。熟悉 requests、urllib 和 scrapy 等请求库。理解 Beautiful Soup、lxml 和正则表达式等解析库。了解 json、csv 和数据库等持久化库。分析源码模块结构。逐行阅读源码并添加注释。实际部署和修改源码,适应不同爬取场景。
- web前端 . regular-expression 1060 2024-10-18 23:45:34
-

- python编程网络爬虫怎么学
- 掌握 Python 网络爬虫技术需要以下步骤:1. 扎实掌握 Python 基础;2. 学习网络爬虫库;3. 理解网络爬虫原理;4. 实践练习;5. 进阶学习。
- web前端 . regular-expression 822 2024-10-18 23:34:10
-

- python爬虫怎么解析网页代码
- 解析网页代码的常见方法包括:BeautifulSoup:使用 BeautifulSoup 库解析 HTML 和 XML 文档,提供直观 API。lxml:功能更强大的库,支持 XPath 表达式,适合处理复杂网页。正则表达式:模式匹配技术,灵活且强大,但编写和维护相对复杂。
- web前端 . regular-expression 761 2024-10-18 23:31:19
-

- 北京找python爬虫怎么样
- 北京 Python 爬虫工作前景广阔,需求量高。求职者可通过招聘网站、行业活动、人脉推荐等方式找工作。Python 爬虫工程师薪资平均年薪约 22.5 万元,主要受益于大数据、AI、金融科技等行业的数据处理需求增长。成功者需要具备 Python 编程技能、网络协议知识、数据提取技术、数据库管理技能以及 HTML 和 CSS 知识。
- web前端 . regular-expression 1157 2024-10-18 23:06:43
-

- Python爬虫怎么找不到mp4
- Python爬虫找不到MP4的原因包括:网页上不存在MP4。提取规则不正确。文件类型处理问题。网站反爬虫措施。网页加载缓慢或中断。网络连接问题。文件已删除或移动。爬虫配置错误。
- web前端 . regular-expression 751 2024-10-18 23:00:33
-

- python爬虫怎么获取em里面的文字
- 要使用Python爬虫获取EM元素中的文本,需要依次执行以下步骤:1. DOM解析:使用库解析HTML文档对象模型(DOM)。2. 元素查找:使用CSS选择器或XPath查找具有“em”标签的元素。3. 文本提取:使用.text或.text_content属性提取元素内容。
- web前端 . regular-expression 941 2024-10-18 22:54:20

PHP讨论组
组员:3305人话题:1500
PHP一种被广泛应用的开放源代码的多用途脚本语言,和其他技术相比,php本身开源免费; 可以将程序嵌入于HTML中去执行, 执行效率比完全生成htmL标记的CGI要高许多,它运行在服务器端,消耗的系统资源相当少,具有跨平台强、效率高的特性,而且php支持几乎所有流行的数据库以及操作系统,最重要的是








工具推荐






WOBIZ电子商务2.0程序
WO@BIZ电子商务2.0软件是窝窝团队基于对互联网发展和业务深入研究后,采用互联网2.0的思想设计、开发的电子商务和社会化网络(SNS)结合的解决方案产品。WOBIZ是互联网2.0创业、传统网站转型、中小企业宣传产品网应用的最佳选择。 它精心设计的架构、强大的功能机制、友好的用户体验和灵活的管理系统,适合从个人到企业各方面应用的要求,为您提供一个安全、稳定、高效、 易用而快捷的电子商务2.0网络解决方案。WO@BIZ包括用户秀系统(Space)、产品秀系统(Blog)、群组系统(Group)、交友应用
电商源码
2025-10-27
H5竞价在线订单系统1.0
H5竞价在线订单系统是以php进行开发的在线订单网站源码。竞价单页一直都是比较火爆的一类源码,很多做产品竞价的朋友几乎都会找这样的源码,因为做搜索引擎的竞价推广,如果人工一一对接的话会很累,而且可能下单量要少得多,但是使用竞价单页就不一样了,很多消费者从竞价单页上看完产品介绍以后,直接就填写信息然后下单了,这样就可以让自己的订单滚滚而来。
企业站源码
2025-10-27
发货100简约发卡系统
发货100简约发卡系统(含小程序)是一套功能强大的在线视频课程教育系统/文章付费阅读系统,无需人工值守,客户在线购买即可自动完成交易。支持缺货提醒/快捷登录/回收站/免登录购买等多种功能。
电商源码
2025-10-27



马赛克风格音乐节广告海报设计下载
马赛克风格音乐节广告海报设计适用于音乐节广告海报设计 本作品提供马赛克风格音乐节广告海报设计的图片会员免费下载,格式为PSD,文件大小为1.5M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-27


驾照考试驾校HTML5网站模板
驾照考试驾校HTML5网站模板是一款适合提供驾驶培训和组织驾照考试服务机构宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-06-10

驾照培训服务机构宣传网站模板
驾照培训服务机构宣传网站模板是一款适合提供一般驾驶和计划培训的驾校宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-07


HTML5房地产公司宣传网站模板
HTML5房地产公司宣传网站模板是一款适合从事房地产服务行业宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-06






