

Redis interview questions and distributed clusters

This article mainly introduces the Redis interview questions and distributed clusters. It has certain reference value. Now I share it with you. Friends in need can refer to it

1. What are the benefits of using Redis?
(1) It is fast because the data is stored in memory, similar to HashMap. The advantage of HashMap is that the time complexity of search and operation is O(1)
(2) It supports rich data types, Supports string, list, set, sorted set, hash
(3) Supports transactions, operations are atomic. The so-called atomicity means that all changes to the data are either executed or not executed
(4) Rich Features: Can be used for caching, messaging, and setting the expiration time by key. It will be automatically deleted after expiration
Topic recommendation: 2020 redis interview questions collection (latest)
2. What are the advantages of redis compared to memcached?
(1) All values in memcached are simple strings. As its replacement, redis supports richer data types
(2) Redis is much faster than memcached
( 3) redis can persist its data
3. Redis common performance problems and solutions:
(1) Master is best not to do any persistence work, such as RDB memory snapshots and AOF logs File
(2) If the data is more important, a Slave enables AOF backup data, and the policy is set to synchronize once per second
(3) For the speed of master-slave replication and the stability of the connection, Master and Slave are the best In the same LAN
(4) Try to avoid adding slave libraries to the master library that is under great pressure
(5) Do not use a graph structure for master-slave replication. It is more stable to use a one-way linked list structure, that is: Master Such a structure is convenient to solve the single point of failure problem and realize the replacement of Master by Slave. If the Master hangs up, you can immediately enable Slave1 as the Master, leaving everything else unchanged.
4. There are 20 million data in MySQL, but only 200,000 data are stored in redis. How to ensure that the data in redis are hot data
Related knowledge: The size of the redis memory data set has increased to a certain size When the time comes, a data elimination strategy will be implemented. redis provides 6 data elimination strategies:
voltile-lru: Select the least recently used data from the data set (server.db[i].expires) with an expiration time set to eliminate it
volatile-ttl: Select the data that is about to expire from the data set (server.db[i].expires) with an expiration time set for elimination
volatile-random: Randomly select data for elimination from the data set (server.db[i].expires) with expiration time set
allkeys-lru: From the data set (server.db[i] .dict) to select the least recently used data for elimination
allkeys-random: Select any data from the data set (server.db[i].dict) for elimination
no-enviction (eviction ): Prohibit eviction of data
5. What are the differences between Memcache and Redis?
1), Storage method
Memecache stores all data in the memory. It will hang up after power failure, and the data cannot exceed the memory size.
Redis is partially stored on the hard disk, which ensures data persistence.
2), Data support type
Memcache’s support for data types is relatively simple.
Redis has complex data types.
3). Different underlying models are used.
The underlying implementation methods and application protocols used to communicate with clients are different.
Redis directly built its own VM mechanism, because if the general system calls system functions, it will waste a certain amount of time to move and request.
4), value size
Redis can reach a maximum of 1GB, while memcache is only 1MB
6. What are the common performance problems of Redis? How to solve?
1).Master writes memory snapshots, and the save command schedules the rdbSave function, which will block the work of the main thread. When the snapshot is relatively large, the impact on performance will be very large, and the service will be suspended intermittently, so Master is the best Do not write memory snapshots.
2). Master AOF persistence. If the AOF file is not rewritten, this persistence method will have the smallest impact on performance, but the AOF file will continue to grow. If the AOF file is too large, it will affect the recovery of the Master restart. speed. It is best not to do any persistence work on the Master, including memory snapshots and AOF log files. In particular, do not enable memory snapshots for persistence. If the data is critical, a Slave should enable AOF backup data, and the strategy is to synchronize once per second.
3). Master calls BGREWRITEAOF to rewrite the AOF file. AOF will occupy a large amount of CPU and memory resources during rewriting, causing the service load to be too high and temporary service suspension.
4). Redis master-slave replication performance issues, for the speed of master-slave replication and the stability of the connection, it is best for Slave and Master to be in the same LAN
7, redis is most suitable Scenario
Redis is most suitable for all data in-momory scenarios. Although Redis also provides persistence function, it is actually more of a disk-backed function, which is quite different from persistence in the traditional sense. The difference, then you may have questions. It seems that Redis is more like an enhanced version of Memcached, so when to use Memcached and when to use Redis?
If you simply compare the difference between Redis and Memcached, most of them will get it. The following points of view:
1. Redis not only supports simple k/v type data, but also provides storage of data structures such as list, set, zset, and hash.
2. Redis supports data backup, that is, data backup in master-slave mode.
3. Redis supports data persistence, which can keep data in memory on disk and can be loaded again for use when restarting.
(1) Session Cache
The most commonly used scenario for using Redis is session cache. The advantage of using Redis to cache sessions over other storage (such as Memcached) is that Redis provides persistence. When maintaining a cache that doesn't strictly require consistency, most people would be unhappy if all of the user's shopping cart information was lost. Now, would they still be?
Fortunately, as Redis has improved over the years, it is easy to find how to properly use Redis to cache session documents. Even the well-known commercial platform Magento provides Redis plug-ins.
(2), Full Page Cache (FPC)
In addition to the basic session token, Redis also provides a very simple FPC platform. Back to the consistency issue, even if the Redis instance is restarted, users will not see a decrease in page loading speed because of disk persistence. This is a great improvement, similar to PHP local FPC.
Taking Magento as an example again, Magento provides a plug-in to use Redis as a full-page cache backend.
In addition, for WordPress users, Pantheon has a very good plug-in wp-redis, which can help you load the pages you have browsed as quickly as possible.
(3) Queue
One of the great advantages of Redis in the field of memory storage engines is that it provides list and set operations, which allows Redis to be used as a good message queue platform. The operations used by Redis as a queue are similar to the push/pop operations of list in local programming languages (such as Python).
If you quickly search "Redis queues" in Google, you will immediately find a large number of open source projects. The purpose of these projects is to use Redis to create very good back-end tools to meet various queue needs. . For example, Celery has a backend that uses Redis as a broker. You can view it from here.
(4), Ranking/Counter
Redis implements the operation of incrementing or decrementing numbers in memory very well. Sets and Sorted Sets also make it very simple for us to perform these operations. Redis just provides these two data structures. So, we want to get the top 10 users from the sorted set - we call them "user_scores", we just need to execute like the following:
Of course, this is assuming that you are Sort in ascending order based on your users' scores. If you want to return the user and the user's score, you need to execute it like this:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games is a good example, implemented in Ruby, with its ranking list It uses Redis to store data, you can see it here.
(5), Publish/Subscribe
Last (but certainly not least) is the publish/subscribe function of Redis. There are indeed many use cases for publish/subscribe. I've seen people use it in social network connections, as triggers for publish/subscribe based scripts, and even to build chat systems using Redis' publish/subscribe functionality! (No, this is true, you can check it out).
Of all the features provided by Redis, I feel that this is the one that people like the least, although it provides users with this multi-function.
High availability distributed cluster
1. High availability
High availability (High Availability) means that when a server stops serving, it will have no impact on the business and users. . The reason for stopping the service may be due to unpredictable reasons such as network cards, routers, computer rooms, excessive CPU load, memory overflow, natural disasters, etc. In many cases, it is also called a single point problem.
(1) There are two main ways to solve single-point problems:
Main and backup methods
This is usually one host and one or more backup machines. Under normal circumstances, The lower host provides services to the outside world and synchronizes data to the standby machine. When the host machine goes down, the standby machine starts serving immediately.
Keepalived is commonly used in Redis HA, which allows the host and backup machines to provide the same virtual IP to the outside world. The client performs data operations through the virtual IP. During normal periods, the host always provides services to the outside world. After a downtime, the VIP automatically drifts to the backup machine. on board.
The advantage is that it has no impact on the client and still operates through VIP.
The shortcomings are also obvious. Most of the time, the backup machine is not used and is wasted.
Master-slave method
This method adopts one master and multiple slaves, and data synchronization is performed between masters and slaves. When the Master goes down, a new Master is elected from the slave through the election algorithm (Paxos, Raft) to continue providing services to the outside world. After the master recovers, it rejoins as the slave.
Another purpose of master-slave is to separate reading and writing. This is a general solution when the reading and writing pressure of a single machine is too high. Its host role only provides write operations or a small amount of reading, and offloads redundant read requests to a single or multiple slave servers through a load balancing algorithm.
The disadvantage is that after the host goes down, although the Slave is elected as the new Master, the IP service address provided to the outside world has changed, which means that it will affect the client. Solving this situation requires some additional work. When the host address changes, the client is notified in time. After the client receives the new address, it uses the new address to continue sending new requests.
(2) Data synchronization
Both master and slave or master-slave are involved in the problem of data synchronization. This is also divided into two situations:
Synchronization method: When the host receives the client After the end-side write operation, the data is synchronized to the slave machine in a synchronous manner. When the slave machine also successfully writes, the host returns success to the client, which is also called strong data consistency. Obviously, the performance of this method will be reduced a lot. When there are many slave machines, it is not necessary to synchronize each one. After the master synchronizes a certain slave machine, the slave machine will then synchronize the data distribution to other slave machines, thus improving the performance sharing of the host machine. Synchronous pressure. This configuration is supported in redis, with one master and one slave. At the same time, this salve serves as the master of other slaves.
Asynchronous mode: After receiving the write operation, the host directly returns success, and then synchronizes the data to the slave in the background in asynchronous mode. This kind of synchronization performance is relatively good, but it cannot guarantee the integrity of the data. For example, if the host suddenly crashes during the asynchronous synchronization process, this method is also called weak data consistency.
Redis master-slave synchronization uses an asynchronous method, so there is a risk of losing a small amount of data. There is also a special case of weak consistency called eventual consistency. Please refer to the CAP principle and consistency model for details.
(3) Solution selection
The keepalived solution is simple to configure and has low labor costs. It is recommended when the amount of data is small and the pressure is low. If the amount of data is relatively large and you don’t want to waste too much machines, and you also want to take some customized measures after the downtime, such as alarming, logging, data migration, etc., it is recommended to use the master-slave method, because it matches the master-slave method. Usually there is also a management and monitoring center.
Downtime notification can be integrated into the client component or separated separately. Redis official Sentinel supports automatic failover, notification, etc. For details, see Low-cost and High-Availability Solution Design (4).
Logic diagram: 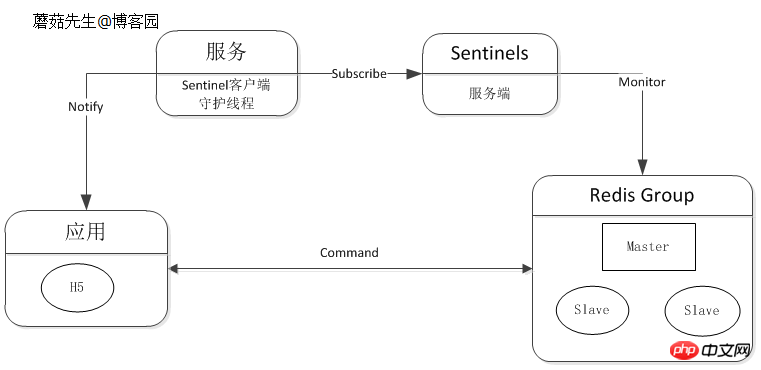
2. Distributed
Distributed (distributed) means that when the business volume and data volume increase, it can be processed through any Increase or decrease the number of servers to solve the problem.
Cluster Era
Deploy at least two Redis servers to form a small cluster, with two main purposes:
High availability: After the host hangs up, automatic failover makes the front-end service accessible to users no effect.
Read and write separation: offload the read pressure from the host to the slave.
Load balancing can be achieved on the client component, and different proportions of read request pressure can be shared according to the operating conditions of different servers.
Logic diagram: 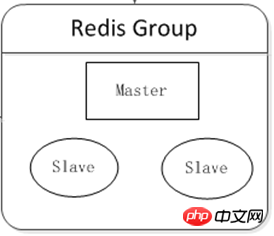
3. Distributed cluster era
When the amount of cached data continues to increase, the memory of a single machine is not enough, and the data needs to be cut. Divide into different parts and distribute them to multiple servers.
Data can be fragmented on the client side. For details on the data fragmentation algorithm, see C# Consistent Hash Detailed Explanation and C# Virtual Bucket Fragmentation.
Logic diagram: 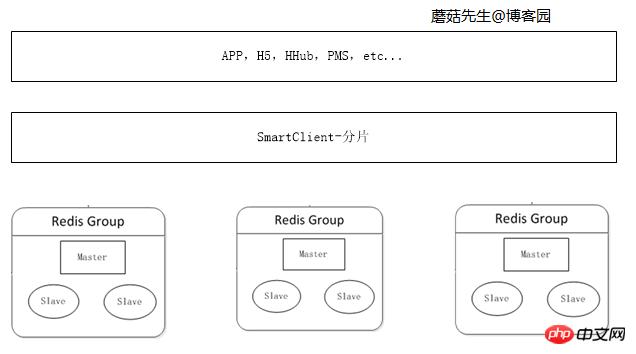
Large-scale distributed cluster era
When the amount of data continues to increase, applications can apply for corresponding distributed services based on the business in different scenarios cluster. The most critical part of this is cache management, and the most important part is the addition of proxy services. The application accesses the real Redis server through a proxy for reading and writing. The advantage of this is:
It avoids the risk caused by more and more clients directly accessing the Redis server, which is difficult to manage and causes risks.
Corresponding security measures can be implemented at the proxy layer, such as current limiting, authorization, and sharding.
Avoid more and more logic codes on the client side, which is not only bloated but also troublesome to upgrade.
The proxy layer is stateless and can expand nodes arbitrarily. For the client, accessing the proxy is the same as accessing stand-alone Redis.
Currently, the host company uses two solutions: client component and proxy, because using a proxy will affect certain performance. The corresponding solutions for proxy implementation include Twitter's Twemproxy and Wandoujia's codis.
Logic diagram: 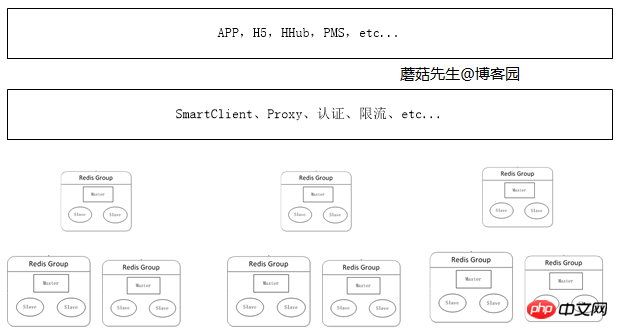
Four, Summary
The distributed cache is followed by the cloud service cache, which completely shields the details from the user. Each application can apply for its own size and traffic plan, such as Taobao OCS cloud service cache.
The required implementation components for distributed cache are:
A cache monitoring, migration, and management center.
A custom client component, SmartClient in the picture above.
A stateless proxy service.
N servers.
Related learning recommendations: redis video tutorial
Related learning recommendations: mysql video tutorial
The above is the detailed content of Redis interview questions and distributed clusters. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
