

Detailed explanation of browser multi-threading mechanism
This time I will bring you a detailed explanation of the browser's multi-threading mechanism. What are the precautions when using the browser's multi-threading mechanism? Here are practical cases, let's take a look.
Before talking, everyone knows that js is based on a single thread, and this thread is the browser's js engine.
First, let’s take a look at the threads that everyone uses in their browsers. 
If we want to perform some time-consuming operations, such as loading a large picture, we may need a progress bar to let the user wait. During the waiting process, the entire The js thread will be blocked and the subsequent code cannot run normally, which may greatly reduce the user experience. At this time, we expect to have a worker thread to handle these time-consuming operations. It was basically impossible to achieve in the traditional HTML era, but now, we have something called a worker. It is a class in js, and we only need to create an instance of it to use it.
var worker = new Worker(js file path);
ConstructionParameters of the functionFill in the path of your js file. This js file will be run in a newly opened thread of the browser and will be merged with the thread of the original js engine. No impact.
So since they do not affect each other, how do we communicate between the two threads? The answer is actually already in the code, that is, the two functions onPostMessage and onmessage, where the parameters of onPostMessage (data) are you The data to be passed, and onmessage is a callback function. Onmessage will be called back only when data is received. Onmessage has a hidden parameter, which is event. We can use event.data to get the passed The incoming data is used to update the main thread.
JavaScript's setTimeout and setInterval are two methods that can easily deceive others' feelings, because we often think that when called, it will be executed in the established way. I think many people are deeply aware of this. I feel the same way, for example
[javascript] view plain copy print?
setTimeout( function() { alert('Hello!'); } , 0);
setInterval( callbackFunction , 100);
think The greeting method in setTimeout will be executed immediately, because this is not said out of thin air, but the JavaScript API document clearly defines the meaning of the second parameter as the number of milliseconds after which the callback method will be executed. It is set to 0 milliseconds here, of course. It was executed immediately.
Similarly, I have no doubt that the callbackFunction method of setInterval is executed immediately every 100 milliseconds!
But as JavaScript application development experience continues to increase and enrich, one day you will I found a weird piece of code and couldn't figure it out:
[javascript] view plain copy print?
p.onclick = function(){
setTimeout( function(){document.getElementById('inputField').focus();}, 0);
};
Since it is executed after 0 milliseconds, why use setTimeout? At this moment, the firm belief has begun to waver.
Until the last day, you accidentally wrote a piece of bad code:
The first line of code enters an infinite loop , but soon you will find that the second and third lines are not what you expected, the alert greeting has not appeared, and there is no news from callbacKFunction!At this time, you are completely confused. This situation is It is difficult to accept, because the process of changing long-established cognitions to accept new ideas is painful, but the facts are before our eyes, and the search for the truth of JavaScript will not stop because of pain. Let us expand the JavaScript thread and Timer exploration journey![javascript] view plain copy print?
setTimeout( function(){ while(true){} } , 100);
- ##setTimeout( function(){ alert('Hello! '); } , 200);
- setInterval( callbackFunction , 200);
Open the clouds and see the moon
The main reason for all the above misunderstandings is: subconsciously believing that JavaScript engines have multiple The thread is executing, and the timer callback function of JavaScript is executed asynchronously.In fact, JavaScript uses a blinding method to deceive our eyes most of the time. The backlight here must clarify a fact:The JavaScript engine uses Single-threaded operation is also meaningful. Single-threaded does not have to worry about complex issues such as thread synchronization, and the problem is simplified.So how does the single-threaded JavaScript engine cooperate with the browser kernel to process these timers and respond to browser events? What about?The JavaScript engine runs in a single thread. The browser has only one thread running the JavaScript program at any time.
The following is a brief explanation based on the browser kernel processing method.
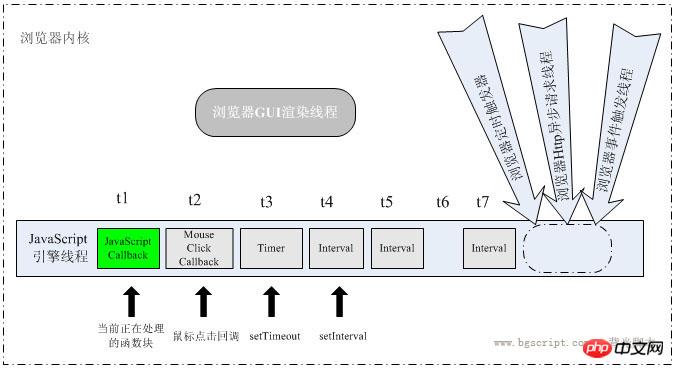
t1 time:
GUI rendering thread:
This thread is responsible for rendering the browser interfaceHTML element
, when the interface needs to be repainted (Repaint) or when a reflow is caused by some operation, this thread will be executed. Although this article focuses on explaining the JavaScript timing mechanism, it is necessary to talk about it at this time The rendering thread is mutually exclusive with the JavaScript engine thread. This is easy to understand because JavaScript scripts can manipulate DOM elements. When modifying the properties of these elements and rendering the interface at the same time, the element data obtained before and after the rendering thread may be inconsistent. While the JavaScript engine is running the script, the browser rendering thread is in a suspended state, which means it is "frozen".GUI event triggering thread:So, updates to the interface performed in the script, such as adding nodes, deleting nodes, or changing the appearance of nodes, will not be reflected immediately. These operations will be saved in a queue until the JavaScript engine is idle. Only then will there be a chance to render it.
The execution of JavaScript script does not affect the triggering of html element events. During the t1 time period, the user first clicks a mouse button. The click is captured by the browser event triggering thread and forms a mouse click event. As can be seen from the figure, for For the JavaScript engine thread, this event is asynchronously transmitted to the end of the task queue by other threads. Since the engine is processing the task at t1, this mouse click event is waiting to be processed.
Timing trigger thread:
Note that the browser model timing counter here is not counted by the JavaScript engine, because the JavaScript engine is single-threaded. If it is in a blocked thread state, it cannot count the time. It must rely on the outside to time and trigger the timing, so the queue The timing event is also an asynchronous event.
As can be seen from the figure, in this t1 time period, after the mouse click event is triggered, the previously set setTimeout timing has also arrived. At this moment, for the JavaScript engine, the timing The triggering thread generates an asynchronous timed event and puts it in the task queue. The event is queued after the click event callback and waits for processing.
Similarly, still within the t1 time period, a setInterval timer is also called next. Added, because it is interval timing, it is triggered twice in succession within the t1 period, and these two events are queued to the end of the queue to wait for processing.
It can be seen that if the time period t1 is very long, much larger than setInterval Timing interval, then the timing trigger thread will continuously generate asynchronous timing events and put them at the end of the task queue regardless of whether they have been processed. However, once t1 and the tasks before the first timing event have been processed, the tasks in these arrangements will Timing events are executed in sequence without interruption. This is because, for the JavaScript engine, each task in the processing queue is processed in the same way, but in a different order.
After t1, That is to say, the currently processed task has been returned. The JavaScript engine will check the task queue and find that the current queue is not empty. Then it will take out the corresponding task under t2 and execute it, and so on at other times. From this point of view:
If the queue is not empty, the engine will take out a task from the head of the queue until the task is processed, that is, after returning, the engine will then run the next task. Other tasks in the queue cannot be executed before the task returns. .
I believe you now have a clear understanding of whether JavaScript can be multi-threaded, and also understand the JavaScript timer operating mechanism. Let’s analyze some cases:
Case 1: setTimeout and setInterval
[javascript] view plain copy print?

setTimeout(function(){
/* Code block... */
setTimeout(arguments.callee, 10);
}, 10);
- ##setInterval(function(){
- /*Code block... */
- }, 10);
Case 2: Is the Ajax asynchronous request really asynchronous?
Many classmates and friends are confused. Since JavaScript is said to run in a single thread, is XMLHttpRequest really asynchronous after connecting?In fact, the request is indeed asynchronous, but this request is newly opened by the browser. A thread request (see the figure above), when the requested status changes, if a callback has been set previously, the asynchronous thread will generate a status change event and put it in the JavaScript engine's processing queue to wait for processing. When the task is processed, the JavaScript engine will always It is a single-thread running callback function. Specifically, it is a function set by single-thread running onreadystatechange.
The use of single-threaded JS and multi-threaded browsers
Some minor issues about type conversion in js
How to implement horizontal scrolling and floating navigation in js
The above is the detailed content of Detailed explanation of browser multi-threading mechanism. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Solve caching issues in Craft CMS: Using wiejeben/craft-laravel-mix plug-in
Apr 18, 2025 am 09:24 AM
Solve caching issues in Craft CMS: Using wiejeben/craft-laravel-mix plug-in
Apr 18, 2025 am 09:24 AM
When developing websites using CraftCMS, you often encounter resource file caching problems, especially when you frequently update CSS and JavaScript files, old versions of files may still be cached by the browser, causing users to not see the latest changes in time. This problem not only affects the user experience, but also increases the difficulty of development and debugging. Recently, I encountered similar troubles in my project, and after some exploration, I found the plugin wiejeben/craft-laravel-mix, which perfectly solved my caching problem.
 What is apache server? What is apache server for?
Apr 13, 2025 am 11:57 AM
What is apache server? What is apache server for?
Apr 13, 2025 am 11:57 AM
Apache server is a powerful web server software that acts as a bridge between browsers and website servers. 1. It handles HTTP requests and returns web page content based on requests; 2. Modular design allows extended functions, such as support for SSL encryption and dynamic web pages; 3. Configuration files (such as virtual host configurations) need to be carefully set to avoid security vulnerabilities, and optimize performance parameters, such as thread count and timeout time, in order to build high-performance and secure web applications.
 Tips for using HDFS file system on CentOS
Apr 14, 2025 pm 07:30 PM
Tips for using HDFS file system on CentOS
Apr 14, 2025 pm 07:30 PM
The Installation, Configuration and Optimization Guide for HDFS File System under CentOS System This article will guide you how to install, configure and optimize Hadoop Distributed File System (HDFS) on CentOS System. HDFS installation and configuration Java environment installation: First, make sure that the appropriate Java environment is installed. Edit /etc/profile file, add the following, and replace /usr/lib/java-1.8.0/jdk1.8.0_144 with your actual Java installation path: exportJAVA_HOME=/usr/lib/java-1.8.0/jdk1.8.0_144exportPATH=$J
 How to view thread status in Tomcat log
Apr 13, 2025 am 08:36 AM
How to view thread status in Tomcat log
Apr 13, 2025 am 08:36 AM
To view the thread status in the Tomcat log, you can use the following methods: TomcatManagerWeb interface: Enter the management address of Tomcat (usually http://localhost:8080/manager) in the browser, and you can view the status of the thread pool after logging in. JMX Monitoring: Use JMX monitoring tools (such as JConsole) to connect to Tomcat's MBean server to view the status of Tomcat's thread pool. Select in JConsole
 Nginx performance monitoring and troubleshooting tools
Apr 13, 2025 pm 10:00 PM
Nginx performance monitoring and troubleshooting tools
Apr 13, 2025 pm 10:00 PM
Nginx performance monitoring and troubleshooting are mainly carried out through the following steps: 1. Use nginx-V to view version information, and enable the stub_status module to monitor the number of active connections, requests and cache hit rate; 2. Use top command to monitor system resource occupation, iostat and vmstat monitor disk I/O and memory usage respectively; 3. Use tcpdump to capture packets to analyze network traffic and troubleshoot network connection problems; 4. Properly configure the number of worker processes to avoid insufficient concurrent processing capabilities or excessive process context switching overhead; 5. Correctly configure Nginx cache to avoid improper cache size settings; 6. By analyzing Nginx logs, such as using awk and grep commands or ELK
 Nginx log analysis and statistics to understand website access
Apr 13, 2025 pm 10:06 PM
Nginx log analysis and statistics to understand website access
Apr 13, 2025 pm 10:06 PM
This article describes how to analyze Nginx logs to improve website performance and user experience. 1. Understand the Nginx log format, such as timestamps, IP addresses, status codes, etc.; 2. Use tools such as awk to parse logs and count indicators such as visits, error rates, etc.; 3. Write more complex scripts according to needs or use more advanced tools, such as goaccess, to analyze data from different dimensions; 4. For massive logs, consider using distributed frameworks such as Hadoop or Spark. By analyzing logs, you can identify website access patterns, improve content strategies, and ultimately optimize website performance and user experience.
 How to monitor HDFS status on CentOS
Apr 14, 2025 pm 07:33 PM
How to monitor HDFS status on CentOS
Apr 14, 2025 pm 07:33 PM
There are many ways to monitor the status of HDFS (Hadoop Distributed File System) on CentOS systems. This article will introduce several commonly used methods to help you choose the most suitable solution. 1. Use Hadoop’s own WebUI, Hadoop’s own Web interface to provide cluster status monitoring function. Steps: Make sure the Hadoop cluster is up and running. Access the WebUI: Enter http://:50070 (Hadoop2.x) or http://:9870 (Hadoop3.x) in your browser. The default username and password are usually hdfs/hdfs. 2. Command line tool monitoring Hadoop provides a series of command line tools to facilitate monitoring
 How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Configuring an HTTPS server on a Debian system involves several steps, including installing the necessary software, generating an SSL certificate, and configuring a web server (such as Apache or Nginx) to use an SSL certificate. Here is a basic guide, assuming you are using an ApacheWeb server. 1. Install the necessary software First, make sure your system is up to date and install Apache and OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
