

Detailed explanation of practical tutorials on using Elasticsearch in spring

This article mainly introduces the detailed code implementation of using Elasticsearch in spring. It has certain reference value. Those who are interested can learn about it.
Before using Elasticsearch, let me talk about some dry information.
1. Both ES and Solr appear as full-text search engines. Both are search servers based on Lucene.
2. ES is not a reliable storage system or a database. It has the risk of losing data.
3. ES is not a real-time system. The success of data writing is only the success of trans log (similar to the bin log of MySQL). Query## immediately after the writing is successful. #It is normal that it cannot be found. Because the data may still be in memory at the moment rather than entering the storage engine. In the same way, after deleting a piece of data, it does not disappear immediately. When can the write be queried? There is a background thread inside ES that regularly writes a batch of data in the memory to the storage engine, and the data is visible thereafter. By default, the background thread runs once per second. The more frequently this thread is run, the lower the write performance. The lower the running frequency, the higher the write performance (not infinitely high).
date ability. All updates mark the old document for deletion and then re-insert a new document.
First:
<bean id="client" factory-bean="esClientBuilder" factory-method="init" destroy-method="close"/>
<bean id="esClientBuilder" class="com.***.EsClientBuilder">
<property name="clusterName" value="集群名称" />
<property name="nodeIpInfo" value="集群地址" />
</bean>Secondly:
package ***;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Map;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
public class EsClientBuilder {
private String clusterName;
private String nodeIpInfo;
private TransportClient client;
public Client init(){
//设置集群的名字
Settings settings = Settings.settingsBuilder()
.put("client.transport.sniff", false)
.put("cluster.name", clusterName)
.build();
//创建集群client并添加集群节点地址
client = TransportClient.builder().settings(settings).build();
Map<String, Integer> nodeMap = parseNodeIpInfo();
for (Map.Entry<String,Integer> entry : nodeMap.entrySet()){
try {
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(entry.getKey()), entry.getValue()));
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
return client;
}
/**
* 解析节点IP信息,多个节点用逗号隔开,IP和端口用冒号隔开
*
* @return
*/
private Map<String, Integer> parseNodeIpInfo(){
String[] nodeIpInfoArr = nodeIpInfo.split(",");
Map<String, Integer> map = new HashMap<String, Integer>(nodeIpInfoArr.length);
for (String ipInfo : nodeIpInfoArr){
String[] ipInfoArr = ipInfo.split(":");
map.put(ipInfoArr[0], Integer.parseInt(ipInfoArr[1]));
}
return map;
}
public String getClusterName() {
return clusterName;
}
public void setClusterName(String clusterName) {
this.clusterName = clusterName;
}
public String getNodeIpInfo() {
return nodeIpInfo;
}
public void setNodeIpInfo(String nodeIpInfo) {
this.nodeIpInfo = nodeIpInfo;
}
}Finally:
api of es (the 2.X version we show here) indexName is equivalent to the database name, and typeName is equivalent to the table name
package ***;
@Service("esService")
public class EsServiceImpl{
@Autowired
private Client client;
/**
* 用docId获取document
* @param indexName
* @param typeName
* @param docId
*/
private static void getWithId(String indexName, String typeName, String docId) {
//get with id
GetResponse gResponse = client.prepareGet(indexName, typeName, docId).execute().actionGet();
System.out.println(gResponse.getIndex());
System.out.println(gResponse.getType());
System.out.println(gResponse.getVersion());
System.out.println(gResponse.isExists());
Map<String, Object> results = gResponse.getSource();
if(results != null) {
for(String key : results.keySet()) {
Object field = results.get(key);
System.out.println(key);
System.out.println(field);
}
}
}
private static void indexWithBulk(String index, String type) {
//指定索引名称,type名称和documentId(documentId可选,不设置则系统自动生成)创建document
IndexRequest ir1 = new IndexRequest();
String source1 = "{" + "\"user\":\"kimchy\"," + "\"price\":\"6.3\"," + "\"tid\":\"20001\"," + "\"message\":\"Elasticsearch\"" + "}";
ir1.index(index).type(type).id("100").source(source1);
IndexRequest ir2 = new IndexRequest();
String source2 = "{" + "\"user\":\"kimchy2\"," + "\"price\":\"7.3\"," + "\"tid\":\"20002\"," + "\"message\":\"Elasticsearch\"" + "}";
ir2.index(index).type(type).id("102").source(source2);
IndexRequest ir3 = new IndexRequest();
String source3 = "{" + "\"user\":\"kimchy3\"," + "\"price\":\"8.3\"," + "\"tid\":\"20003\"," + "\"message\":\"Elasticsearch\"" + "}";
ir3.index(index).type(type).id("103").source(source3);
BulkResponse response = client.prepareBulk().add(ir1).add(ir2).add(ir3).execute().actionGet();
BulkItemResponse[] responses = response.getItems();
if(responses != null && responses.length > 0) {
for(BulkItemResponse r : responses) {
String i = r.getIndex();
String t = r.getType();
System.out.println(i+","+t);
}
}
}
private static void sumCountSearch(String indexName, String typeName,
String sumField, String countField, String searchField, String searchValue) {
SumBuilder sb = AggregationBuilders.sum("sumPrice").field(sumField);
TermQueryBuilder tb = QueryBuilders.termQuery(searchField, searchValue);
SearchResponse sResponse = client.prepareSearch(indexName).setTypes(typeName).setQuery(tb).addAggregation(sb).execute().actionGet();
Map<String, Aggregation> aggMap = sResponse.getAggregations().asMap();
if(aggMap != null && aggMap.size() > 0) {
for(String key : aggMap.keySet()) {
if("sumPrice".equals(key)) {
Sum s = (Sum)aggMap.get(key);
System.out.println(key + "," + s.getValue());
}
else if("countTid".equals(key)) {
StatsBuilder c = (StatsBuilder)aggMap.get(key);
System.out.println(key + "," + c.toString());
}
}
}
}
private static void updateDoc(String indexName, String typeName, String id) throws IOException, InterruptedException, ExecutionException {
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index(indexName);
updateRequest.type(typeName);
updateRequest.id(id);
updateRequest.doc(jsonBuilder().startObject().field("gender", "male").endObject());
UpdateResponse resp = client.update(updateRequest).get();
resp.getClass();
}
private static void scrollSearch(String indexName, String typeName, String... ids) {
IdsQueryBuilder qb = QueryBuilders.idsQuery().addIds(ids);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
.setSearchType(SearchType.SCAN)
.setQuery(qb)
.setScroll(new TimeValue(100))
.setSize(50)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards+","+timeCost+","+sShards);
while (true) {
SearchHits hits = sResponse.getHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < hitArray.length; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
sResponse = client.prepareSearchScroll(sResponse.getScrollId()).setScroll(new TimeValue(100)).execute().actionGet();
if (sResponse.getHits().getHits().length == 0) {
break;
}
}
}
private static void deleteDocuments(String string, String string2) {
SearchResponse sResponse = client.prepareSearch(string)
.setTypes(string2)
.setSearchType(SearchType.QUERY_THEN_FETCH)
.setQuery(QueryBuilders.matchAllQuery())
.setFrom(0).setSize(60)
.execute()
.actionGet();
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
List<String> ids = new ArrayList<String>(hitArray.length);
for(int i = 0; i < count; i++) {
System.out.println("==================================");
SearchHit hit = hitArray[i];
ids.add(hit.getId());
}
for(String id : ids) {
DeleteResponse response = client.prepareDelete(string, string2, id).execute().actionGet();
}
}
private static void dateRangeSearch(String indexName, String typeName,
String termName, String from, String to) {
// 构建range query
//2015-08-20 12:27:11
QueryBuilder qb = QueryBuilders.rangeQuery(termName).from(from).to(to);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(qb)
// 设置排序field
.addSort(termName, SortOrder.DESC)
// 设置分页
.setFrom(0).setSize(60).execute().actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards + "," + timeCost + "," + sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for (String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
private static void dateRangeSearch2(String indexName, String typeName,
String termName, String from, String to) {
// 构建range query
QueryBuilder qb = QueryBuilders.rangeQuery(termName).from(from).to(to);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(qb)
// 设置排序field
.addSort(termName, SortOrder.DESC)
// 设置分页
.setFrom(0).setSize(60).execute().actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards + "," + timeCost + "," + sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for (String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
private static void countWithQuery(String indexName, String typeName, String termName, String termValue, String sortField, String highlightField) {
//search result get source
CountResponse cResponse = client.prepareCount(indexName)
.setTypes(typeName)
.setQuery(QueryBuilders.termQuery(termName, termValue))
.execute()
.actionGet();
int tShards = cResponse.getTotalShards();
int sShards = cResponse.getSuccessfulShards();
System.out.println(tShards+","+sShards);
long count = cResponse.getCount();
}
private static void rangeSearchWithOtherSearch(String indexName, String typeName,
String termName, String min, String max, String termQueryField) {
// 构建range query
QueryBuilder qb = QueryBuilders.rangeQuery(termName).from(min).to(max);
TermQueryBuilder tb = QueryBuilders.termQuery(termName, termQueryField);
BoolQueryBuilder bq = boolQuery().must(qb).must(tb);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(bq)
// 设置排序field
.addSort(termName, SortOrder.DESC)
// 设置分页
.setFrom(0).setSize(60).execute().actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards + "," + timeCost + "," + sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for (String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
private static void termRangeSearch(String indexName, String typeName,
String termName, String min, String max, String highlightField) {
QueryBuilder qb = QueryBuilders.rangeQuery(termName).from(min).to(max);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(qb)
// 设置排序field
.addSort(termName, SortOrder.DESC)
//设置高亮field
.addHighlightedField(highlightField)
// 设置分页
.setFrom(0).setSize(60).execute().actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards + "," + timeCost + "," + sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for (String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
private static void sumOneField(String indexName, String typeName, String fieldName) {
SumBuilder sb = AggregationBuilders.sum("sum").field(fieldName);
//search result get source
SearchResponse sResponse = client.prepareSearch(indexName).setTypes(typeName).addAggregation(sb).execute().actionGet();
Map<String, Aggregation> aggMap = sResponse.getAggregations().asMap();
if(aggMap != null && aggMap.size() > 0) {
for(String key : aggMap.keySet()) {
Sum s = (Sum)aggMap.get(key);
System.out.println(s.getValue());
}
}
}
private static void searchWithTermQueryAndRetureSpecifiedFields(String indexName, String typeName, String termName,String termValue, String sortField, String highlightField,String... fields) {
SearchRequestBuilder sb = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(QueryBuilders.termQuery(termName, termValue))
// 设置排序field
.addSort(sortField, SortOrder.DESC)
// 设置高亮field
.addHighlightedField(highlightField)
// 设置分页
.setFrom(0).setSize(60);
for (String field : fields) {
sb.addField(field);
}
SearchResponse sResponse = sb.execute().actionGet();
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, SearchHitField> fm = hit.getFields();
for (String key : fm.keySet()) {
SearchHitField f = fm.get(key);
System.out.println(f.getName());
System.out.println(f.getValue());
}
}
}
private static void searchWithIds(String indexName, String typeName, String sortField, String highlightField, String... ids) {
IdsQueryBuilder qb = QueryBuilders.idsQuery().addIds(ids);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
//设置search type
//常用search type用:query_then_fetch
//query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
//查询的termName和termvalue
.setQuery(qb)
//设置排序field
.addSort(sortField, SortOrder.DESC)
//设置高亮field
.addHighlightedField(highlightField)
//设置分页
.setFrom(0).setSize(60)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards+","+timeCost+","+sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 在index:indexName, type:typeName中做通配符查询
* @param indexName
* @param typeName
* @param termName
* @param termValue
* @param sortField
* @param highlightField
*/
private static void wildcardSearch(String indexName, String typeName, String termName, String termValue, String sortField, String highlightField) {
QueryBuilder qb = QueryBuilders.wildcardQuery(termName, termValue);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
//设置search type
//常用search type用:query_then_fetch
//query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
//查询的termName和termvalue
.setQuery(qb)
//设置排序field
// .addSort(sortField, SortOrder.DESC)
//设置高亮field
// .addHighlightedField(highlightField)
//设置分页
.setFrom(0).setSize(60)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards+","+timeCost+","+sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 在index:indexName, type:typeName中做模糊查询
* @param indexName
* @param typeName
* @param termName
* @param termValue
* @param sortField
* @param highlightField
*/
private static void fuzzySearch(String indexName, String typeName, String termName, String termValue, String sortField, String highlightField) {
QueryBuilder qb = QueryBuilders.fuzzyQuery(termName, termValue);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
//设置search type
//常用search type用:query_then_fetch
//query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
//查询的termName和termvalue
.setQuery(qb)
//设置排序field
.addSort(sortField, SortOrder.DESC)
//设置高亮field
.addHighlightedField(highlightField)
//设置分页
.setFrom(0).setSize(60)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards+","+timeCost+","+sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 在index:indexName, type:typeName中做区间查询
* @param indexName
* @param typeName
* @param termName
* @param min
* @param max
* @param highlightField
*/
private static void numericRangeSearch(String indexName, String typeName,
String termName, double min, double max, String highlightField) {
// 构建range query
QueryBuilder qb = QueryBuilders.rangeQuery(termName).from(min).to(max);
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
// 设置search type
// 常用search type用:query_then_fetch
// query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
// 查询的termName和termvalue
.setQuery(qb)
// 设置排序field
.addSort(termName, SortOrder.DESC)
//设置高亮field
.addHighlightedField(highlightField)
// 设置分页
.setFrom(0).setSize(60).execute().actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards + "," + timeCost + "," + sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for (int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for (String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 在索引indexName, type为typeName中查找两个term:term1(termName1, termValue1)和term2(termName2, termValue2)
* @param indexName
* @param typeName
* @param termName1
* @param termValue1
* @param termName2
* @param termValue2
* @param sortField
* @param highlightField
*/
private static void searchWithBooleanQuery(String indexName, String typeName, String termName1, String termValue1,
String termName2, String termValue2, String sortField, String highlightField) {
//构建boolean query
BoolQueryBuilder bq = boolQuery().must(termQuery(termName1, termValue1)).must(termQuery(termName2, termValue2));
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
//设置search type
//常用search type用:query_then_fetch
//query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
//查询的termName和termvalue
.setQuery(bq)
//设置排序field
.addSort(sortField, SortOrder.DESC)
//设置高亮field
.addHighlightedField(highlightField)
//设置分页
.setFrom(0).setSize(60)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
System.out.println(tShards+","+timeCost+","+sShards);
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < count; i++) {
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 在索引indexName, type为typeName中查找term(termName, termValue)
* @param indexName
* @param typeName
* @param termName
* @param termValue
* @param sortField
* @param highlightField
*/
private static void searchWithTermQuery(String indexName, String typeName, String termName, String termValue, String sortField, String highlightField) {
SearchResponse sResponse = client.prepareSearch(indexName)
.setTypes(typeName)
//设置search type
//常用search type用:query_then_fetch
//query_then_fetch是先查到相关结构,然后聚合不同node上的结果后排序
.setSearchType(SearchType.QUERY_THEN_FETCH)
//查询的termName和termvalue
.setQuery(QueryBuilders.termQuery(termName, termValue))
//设置排序field
// .addSort(sortField, SortOrder.DESC)
//设置高亮field
// .addHighlightedField(highlightField)
//设置分页
.setFrom(0).setSize(60)
.execute()
.actionGet();
int tShards = sResponse.getTotalShards();
long timeCost = sResponse.getTookInMillis();
int sShards = sResponse.getSuccessfulShards();
SearchHits hits = sResponse.getHits();
long count = hits.getTotalHits();
SearchHit[] hitArray = hits.getHits();
for(int i = 0; i < count; i++) {
System.out.println("==================================");
SearchHit hit = hitArray[i];
Map<String, Object> fields = hit.getSource();
for(String key : fields.keySet()) {
System.out.println(key);
System.out.println(fields.get(key));
}
}
}
/**
* 用java的map构建document
*/
private static void indexWithMap(String indexName, String typeName) {
Map<String, Object> json = new HashMap<String, Object>();
//设置document的field
json.put("user","kimchy2");
json.put("postDate",new Date());
json.put("price",6.4);
json.put("message","Elasticsearch");
json.put("tid","10002");
json.put("endTime","2015-08-25 09:00:00");
//指定索引名称,type名称和documentId(documentId可选,不设置则系统自动生成)创建document
IndexResponse response = client.prepareIndex(indexName, typeName, "2").setSource(json).execute().actionGet();
//response中返回索引名称,type名称,doc的Id和版本信息
String index = response.getIndex();
String type = response.getType();
String id = response.getId();
long version = response.getVersion();
boolean created = response.isCreated();
System.out.println(index+","+type+","+id+","+version+","+created);
}
/**
* 用java字符串创建document
*/
private static void indexWithStr(String indexName, String typeName) {
//手工构建json字符串
//该document包含user, postData和message三个field
String json = "{" + "\"user\":\"kimchy\"," + "\"postDate\":\"2013-01-30\"," + "\"price\":\"6.3\"," + "\"tid\":\"10001\"," + "}";
//指定索引名称,type名称和documentId(documentId可选,不设置则系统自动生成)创建document
IndexResponse response = client.prepareIndex(indexName, typeName, "1")
.setSource(json)
.execute()
.actionGet();
//response中返回索引名称,type名称,doc的Id和版本信息
String index = response.getIndex();
String type = response.getType();
String id = response.getId();
long version = response.getVersion();
boolean created = response.isCreated();
System.out.println(index+","+type+","+id+","+version+","+created);
}
private static void deleteDocWithId(String indexName, String typeName, String docId) {
DeleteResponse dResponse = client.prepareDelete(indexName, typeName, docId).execute().actionGet();
String index = dResponse.getIndex();
String type = dResponse.getType();
String id = dResponse.getId();
long version = dResponse.getVersion();
System.out.println(index+","+type+","+id+","+version);
}
/**
* 创建索引
* 注意:在生产环节中通知es集群的owner去创建index
* @param client
* @param indexName
* @param documentType
* @throws IOException
*/
private static void createIndex(String indexName, String documentType) throws IOException {
final IndicesExistsResponse iRes = client.admin().indices().prepareExists(indexName).execute().actionGet();
if (iRes.isExists()) {
client.admin().indices().prepareDelete(indexName).execute().actionGet();
}
client.admin().indices().prepareCreate(indexName).setSettings(Settings.settingsBuilder().put("number_of_shards", 1).put("number_of_replicas", "0")).execute().actionGet();
XContentBuilder mapping = jsonBuilder()
.startObject()
.startObject(documentType)
// .startObject("_routing").field("path","tid").field("required", "true").endObject()
.startObject("_source").field("enabled", "true").endObject()
.startObject("_all").field("enabled", "false").endObject()
.startObject("properties")
.startObject("user")
.field("store", true)
.field("type", "string")
.field("index", "not_analyzed")
.endObject()
.startObject("message")
.field("store", true)
.field("type","string")
.field("index", "analyzed")
.field("analyzer", "standard")
.endObject()
.startObject("price")
.field("store", true)
.field("type", "float")
.endObject()
.startObject("nv1")
.field("store", true)
.field("type", "integer")
.field("index", "no")
.field("null_value", 0)
.endObject()
.startObject("nv2")
.field("store", true)
.field("type", "integer")
.field("index", "not_analyzed")
.field("null_value", 10)
.endObject()
.startObject("tid")
.field("store", true)
.field("type", "string")
.field("index", "not_analyzed")
.endObject()
.startObject("endTime")
.field("type", "date")
.field("store", true)
.field("index", "not_analyzed")
.field("format", "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd'T'HH:mm:ss.SSSZ")
.endObject()
.startObject("date")
.field("type", "date")
.endObject()
.endObject()
.endObject()
.endObject();
client.admin().indices()
.preparePutMapping(indexName)
.setType(documentType)
.setSource(mapping)
.execute().actionGet();
}
}Detailed explanation of usage code examples of Spring framework annotations
2 .Java transaction management learning: Detailed code explanation of Spring and Hibernate
3.Sharing example tutorials on using Spring Boot to develop Restful programs
4.Detailed explanation of the seven return methods supported by spring mvc
5.Detailed explanation of Spring's enhanced implementation examples based on Aspect
6. PHPRPC for Java Spring example
7. Java Spring mvc operation Redis and Redis cluster
The above is the detailed content of Detailed explanation of practical tutorials on using Elasticsearch in spring. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
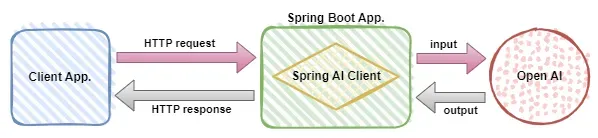
In 2023, AI technology has become a hot topic and has a huge impact on various industries, especially in the programming field. People are increasingly aware of the importance of AI technology, and the Spring community is no exception. With the continuous advancement of GenAI (General Artificial Intelligence) technology, it has become crucial and urgent to simplify the creation of applications with AI functions. Against this background, "SpringAI" emerged, aiming to simplify the process of developing AI functional applications, making it simple and intuitive and avoiding unnecessary complexity. Through "SpringAI", developers can more easily build applications with AI functions, making them easier to use and operate.
 Use Spring Boot and Spring AI to build generative artificial intelligence applications
Apr 28, 2024 am 11:46 AM
Use Spring Boot and Spring AI to build generative artificial intelligence applications
Apr 28, 2024 am 11:46 AM
As an industry leader, Spring+AI provides leading solutions for various industries through its powerful, flexible API and advanced functions. In this topic, we will delve into the application examples of Spring+AI in various fields. Each case will show how Spring+AI meets specific needs, achieves goals, and extends these LESSONSLEARNED to a wider range of applications. I hope this topic can inspire you to understand and utilize the infinite possibilities of Spring+AI more deeply. The Spring framework has a history of more than 20 years in the field of software development, and it has been 10 years since the Spring Boot 1.0 version was released. Now, no one can dispute that Spring
 What are the implementation methods of spring programmatic transactions?
Jan 08, 2024 am 10:23 AM
What are the implementation methods of spring programmatic transactions?
Jan 08, 2024 am 10:23 AM
How to implement spring programmatic transactions: 1. Use TransactionTemplate; 2. Use TransactionCallback and TransactionCallbackWithoutResult; 3. Use Transactional annotations; 4. Use TransactionTemplate in combination with @Transactional; 5. Customize the transaction manager.
 How to set transaction isolation level in Spring
Jan 26, 2024 pm 05:38 PM
How to set transaction isolation level in Spring
Jan 26, 2024 pm 05:38 PM
How to set the transaction isolation level in Spring: 1. Use the @Transactional annotation; 2. Set it in the Spring configuration file; 3. Use PlatformTransactionManager; 4. Set it in the Java configuration class. Detailed introduction: 1. Use the @Transactional annotation, add the @Transactional annotation to the class or method that requires transaction management, and set the isolation level in the attribute; 2. In the Spring configuration file, etc.
 Spring Annotation Revealed: Analysis of Common Annotations
Dec 30, 2023 am 11:28 AM
Spring Annotation Revealed: Analysis of Common Annotations
Dec 30, 2023 am 11:28 AM
Spring is an open source framework that provides many annotations to simplify and enhance Java development. This article will explain commonly used Spring annotations in detail and provide specific code examples. @Autowired: Autowired @Autowired annotation can be used to automatically wire beans in the Spring container. When we use the @Autowired annotation where dependencies are required, Spring will find matching beans in the container and automatically inject them. The sample code is as follows: @Auto
 Detailed explanation of Bean acquisition methods in Spring
Dec 30, 2023 am 08:49 AM
Detailed explanation of Bean acquisition methods in Spring
Dec 30, 2023 am 08:49 AM
Detailed explanation of the Bean acquisition method in Spring In the Spring framework, Bean acquisition is a very important part. In applications, we often need to use dependency injection or dynamically obtain instances of beans. This article will introduce in detail how to obtain beans in Spring and give specific code examples. Obtaining the Bean@Component annotation through the @Component annotation is one of the commonly used annotations in the Spring framework. We can do this by adding @Compone on the class
 Spring Security permission control framework usage guide
Feb 18, 2024 pm 05:00 PM
Spring Security permission control framework usage guide
Feb 18, 2024 pm 05:00 PM
In back-end management systems, access permission control is usually required to limit different users' ability to access interfaces. If a user lacks specific permissions, he or she cannot access certain interfaces. This article will use the waynboot-mall project as an example to introduce how common back-end management systems introduce the permission control framework SpringSecurity. The outline is as follows: waynboot-mall project address: https://github.com/wayn111/waynboot-mall 1. What is SpringSecurity? SpringSecurity is an open source project based on the Spring framework, aiming to provide powerful and flexible security for Java applications.
 Application of JUnit unit testing framework in Spring projects
Apr 18, 2024 pm 04:54 PM
Application of JUnit unit testing framework in Spring projects
Apr 18, 2024 pm 04:54 PM
JUnit is a widely used Java unit testing framework in Spring projects and can be applied by following steps: Add JUnit dependency: org.junit.jupiterjunit-jupiter5.8.1test Write test cases: Use @ExtendWith(SpringExtension.class) to enable extension, use @Autowired inject beans, use @BeforeEach and @AfterEach to prepare and clean, and mark test methods with @Test.
