
 Technology peripherals
AI
Extremely long sequences, extremely fast: LASP sequence parallelism for a new generation of efficient large language models
Technology peripherals
AI
Extremely long sequences, extremely fast: LASP sequence parallelism for a new generation of efficient large language models
Extremely long sequences, extremely fast: LASP sequence parallelism for a new generation of efficient large language models


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
From the international top GPT-4 128K, Claude 200K to the domestic "Red Fried Chicken" Kimi Chat that supports more than 2 million words of text, large language model (LLM) in long context technology Rolled up involuntarily. When the smartest minds in the world are working on something, the importance and difficulty of the matter are self-evident.
Extremely long contexts can greatly expand the productivity value of large models. With the popularity of AI, users are no longer satisfied with playing with large models and doing a few brain teasers. Users are beginning to desire to use large models to truly improve productivity. After all, the PPT that used to take a week to create can now be generated in minutes by just feeding the large model a string of prompt words and a few reference documents. Who wouldn't love it as a working person?
Recently, some new efficient sequence modeling methods have emerged, such as Lightning Attention (TransNormerLLM), State Space Modeling (Mamba), Linear RNN (RWKV, HGRN, Griffin), etc., which have become a hot research direction. Researchers are eager to transform the already mature 7-year-old Transformer architecture to obtain a new architecture with comparable performance but only linear complexity. This type of approach focuses on model architecture design and provides hardware-friendly implementation based on CUDA or Triton, allowing it to be efficiently calculated inside a single-card GPU like FlashAttention.
At the same time, another controller of long sequence training has also adopted a different strategy: sequence parallelism has gained more and more attention. By dividing the long sequence into multiple equally divided short sequences in the sequence dimension, and dispersing the short sequences to different GPU cards for parallel training, and supplemented by inter-card communication, the effect of sequence parallel training is achieved. From the earliest Colossal-AI sequence parallelism, to Megatron sequence parallelism, to DeepSpeed Ulysses, and more recently, Ring Attention, researchers have continued to design more elegant and efficient communication mechanisms to improve the training efficiency of sequence parallelism. Of course, these known methods are all designed for traditional attention mechanisms, which we call Softmax Attention in this article. These methods have already been analyzed by various experts, so this article will not discuss them in detail.

Paper title: Linear Attention Sequence Parallelism Paper address: https://arxiv.org /abs/2404.02882 - ##LASP code address: https://github.com/OpenNLPLab/LASP
It should be noted that the name of the natural language processing method includes Linear Attention, but it is not limited to the Linear Attention method, but can be widely used including Lightning Attention (TransNormerLLM), State Space Modeling (Mamba ), Linear RNN (RWKV, HGRN, Griffin), etc. Linear sequence modeling methods.
Introduction to LASP method
In order to better understand the idea of LASP, let us first review the calculation formula of traditional Softmax Attention: O=softmax((QK^T)⊙M)V, where Q, K, V, M, and O are respectively Query, Key, Value, Mask and Output matrices, M here is a lower triangular all-1 matrix in one-way tasks (such as GPT), and can be ignored in two-way tasks (such as BERT), that is, there is no Mask matrix for bi-directional tasks . We will split LASP into four points for explanation below:
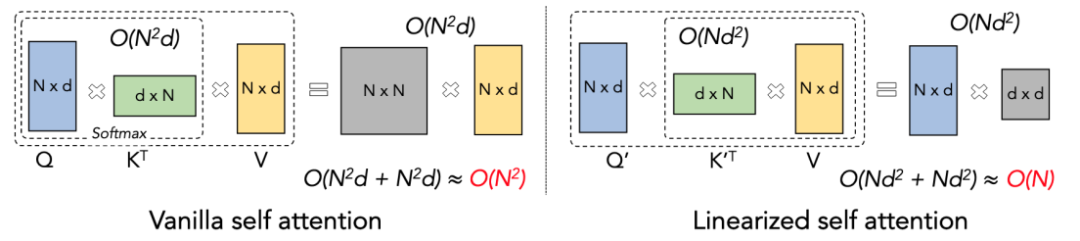
Linear Attention Principle
Linear Attention can be regarded as a variant of Softmax Attention. Linear Attention removes the computationally expensive Softmax operator, and the calculation formula of Attention can be written as a concise form of O=((QK^T)⊙M) V. However, due to the existence of the Mask matrix M in the one-way task, this form can still only perform left multiplication calculation (that is, calculate QK^T first), so the linear complexity of O (N) cannot be obtained. But for bidirectional tasks, since there is no Mask matrix, the calculation formula can be further simplified to O=(QK^T) V. The clever thing about Linear Attention is that by simply using the associative law of matrix multiplication, its calculation formula can be further transformed into: O=Q (K^T V). This calculation form is called right multiplication. It can be seen that Linear Attention is Tempting O (N) complexity can be achieved in this bidirectional task!
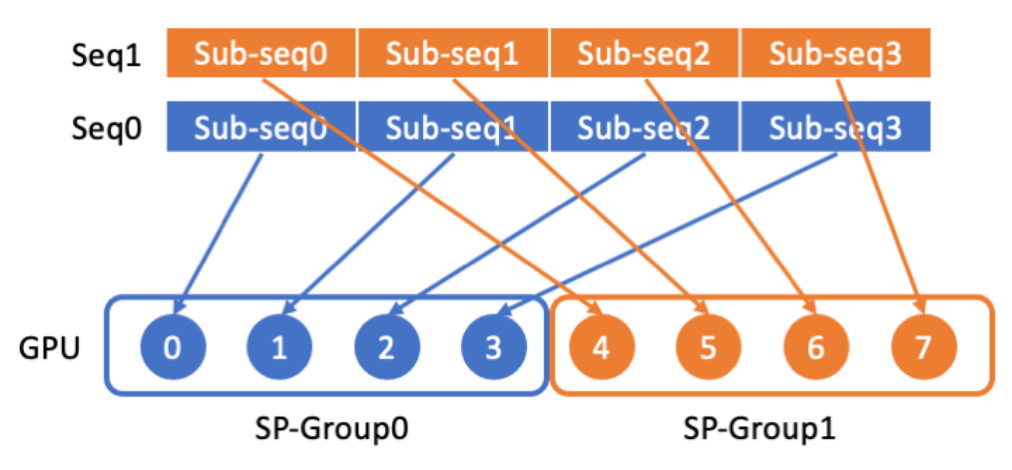
LASP data distribution
LASP first divides the long sequence data into multiple equally divided subsequences from the sequence dimension. The subsequence is then distributed to all GPUs in the sequence parallel communication group, so that each GPU has a subsequence for subsequent sequence parallel calculations.
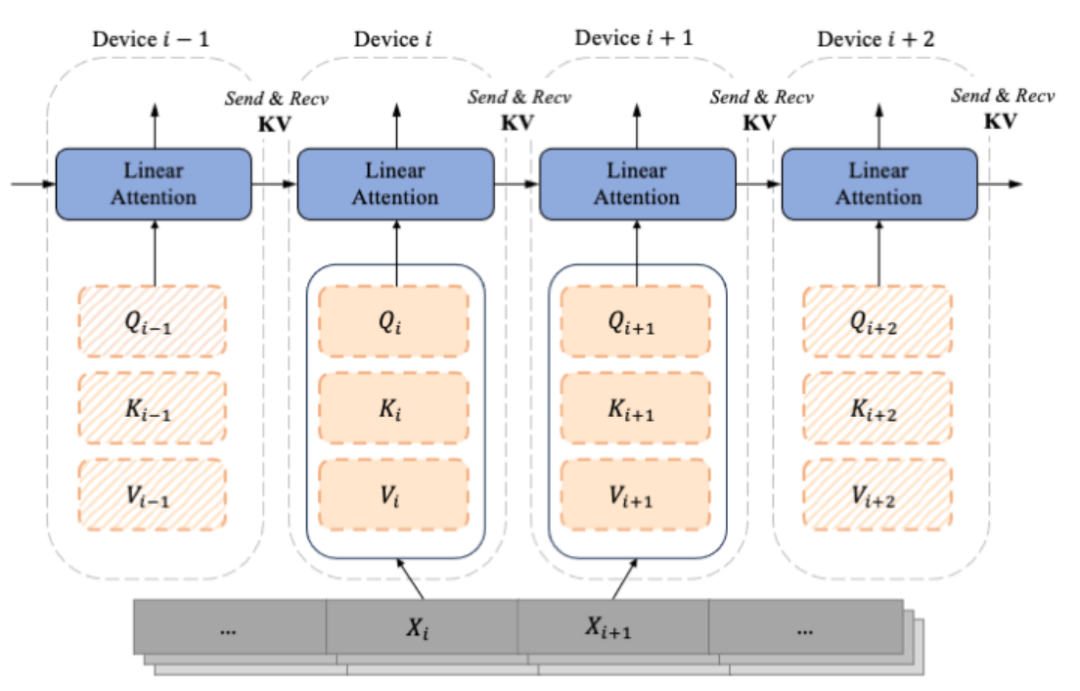
LASP core mechanism
As the decoder-only GPT-like model gradually becomes the de facto standard of LLM, LASP The design fully considers the scenario of one-way Casual tasks. Calculated from the segmented subsequence Xi are Qi, Ki, and Vi segmented according to the sequence dimensions. Each index i corresponds to a Chunk and a Device (i.e., a GPU). Due to the existence of the Mask matrix, the LASP author cleverly distinguishes the Qi, Ki, and Vi corresponding to each Chunk into two types, namely: Intra-Chunk and Inter-Chunk. Among them, Intra-Chunk is the Chunk on the diagonal after the Mask matrix is divided into blocks. It can be considered that the Mask matrix still exists, and left multiplication still needs to be used; Inter-Chunk is the Chunk on the off-diagonal line of the Mask matrix, which can be considered not With the existence of the Mask matrix, right multiplication can be used; obviously, when the more Chunks are divided, the proportion of Chunks on the diagonal will be smaller, and the proportion of Chunks on the off-diagonal will be larger. Right multiplication can be used to achieve linear complexity. The more chunks the Attention calculates. Among them, for the calculation of the right multiplied Inter-Chunk, during forward calculation, each device needs to use point-to-point communication to Recive the KV of the previous device and send its own updated KV to the next device. When calculating in reverse, it is just the opposite, except that the objects of Send and Recive become the gradient dKV of KV. The forward calculation process is shown in the figure below:
LASP code implementation
In order to improve the computing efficiency of LASP on the GPU, The author performed Kernel Fusion for the calculations of Intra-Chunk and Inter-Chunk respectively, and also integrated the update calculations of KV and dKV into the calculations of Intra-Chunk and Inter-Chunk. Additionally, in order to avoid recomputing the activation KV during backpropagation, the authors chose to store it in the GPU's HBM immediately after the forward propagation calculation. During the subsequent backpropagation, LASP directly accesses the KV for use. It should be noted that the KV size stored in HBM is d x d and is completely unaffected by the sequence length N. When the input sequence length N is large, the memory footprint of KV becomes insignificant. Inside a single GPU, the author implemented Lightning Attention implemented by Triton to reduce the IO overhead between HBM and SRAM, thereby accelerating single-card Linear Attention calculations.
Readers who want to know more details can read Algorithm 2 (LASP forward process) and Algorithm 3 (LASP reverse process) in the paper, as well as the detailed derivation process in the paper.
Traffic Analysis
In the LASP algorithm, it should be noted that forward propagation requires KV activation communication at each Linear Attention module layer. The traffic is Bd^2/h, where B is the batch size and h is the number of heads. In contrast, Megatron-SP uses an All-Gather operation after the two Layer Norm layers in each Transformer layer, and a Reduce-Scatter operation after the Attention and FFN layers, which causes its communication The quantity is 2BNd 4BNd/T, where T is the sequence parallel dimension. DeepSpeed-Ulysses uses an All-to-All set communication operation to process the input Q, K, V and output O of each Attention module layer, resulting in a communication volume of 4BNd/T. The communication volume comparison between the three is shown in the table below. where d/h is the head dimension, usually set to 128. In practical applications, LASP can achieve the lowest theoretical communication volume when N/T>=32. Furthermore, LASP's communication volume is not affected by sequence length N or subsequence length C, which is a huge advantage for parallel computing of extremely long sequences across large GPU clusters.
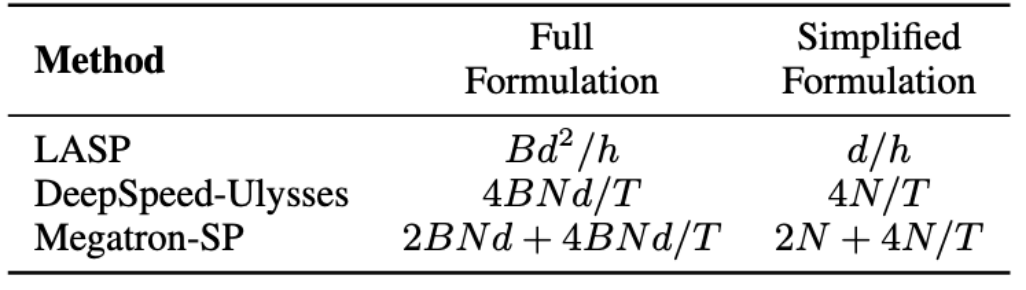
Data-Sequence Hybrid Parallel
Data parallelism (i.e. Batch-level data segmentation) is already distributed training For regular operations, based on original data parallelism (PyTorch DDP), sliced data parallelism has evolved to save more graphics memory. From the original DeepSpeed ZeRO series to the FSDP officially supported by PyTorch, sliced data parallelism has been mature enough and has been More and more users are using it. As a sequence-level data segmentation method, LASP is compatible with various data parallel methods including PyTorch DDP, Zero-1/2/3, and FSDP. This is undoubtedly good news for LASP users.
Accuracy Experiment
The experimental results on TransNormerLLM (TNL) and Linear Transformer show that LASP, as a system optimization method, can be combined with various DDP backends, and Both can achieve the same performance as Baseline.
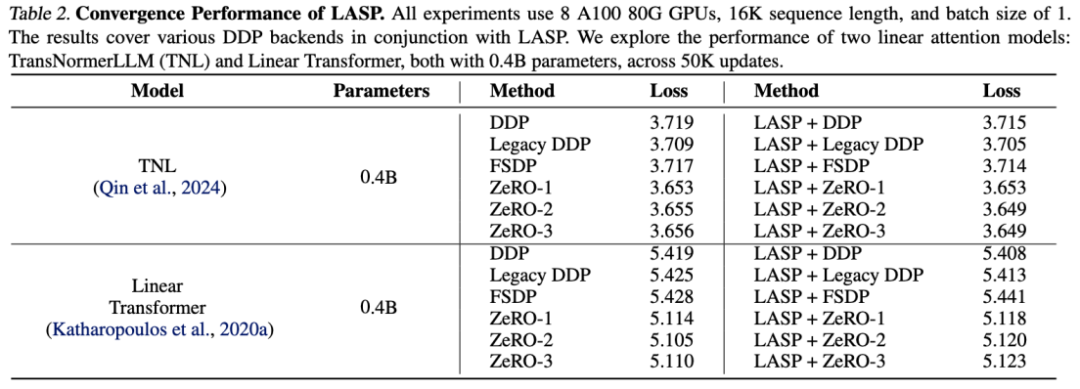
Scalability Experiment
Thanks to the efficient communication mechanism design, LASP can be easily expanded to hundreds of GPU cards, and Maintains great scalability.
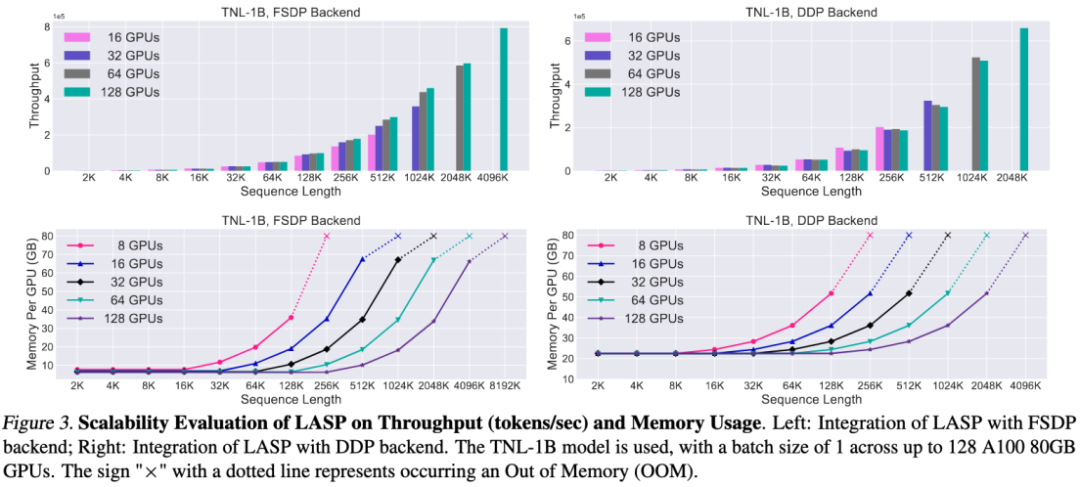
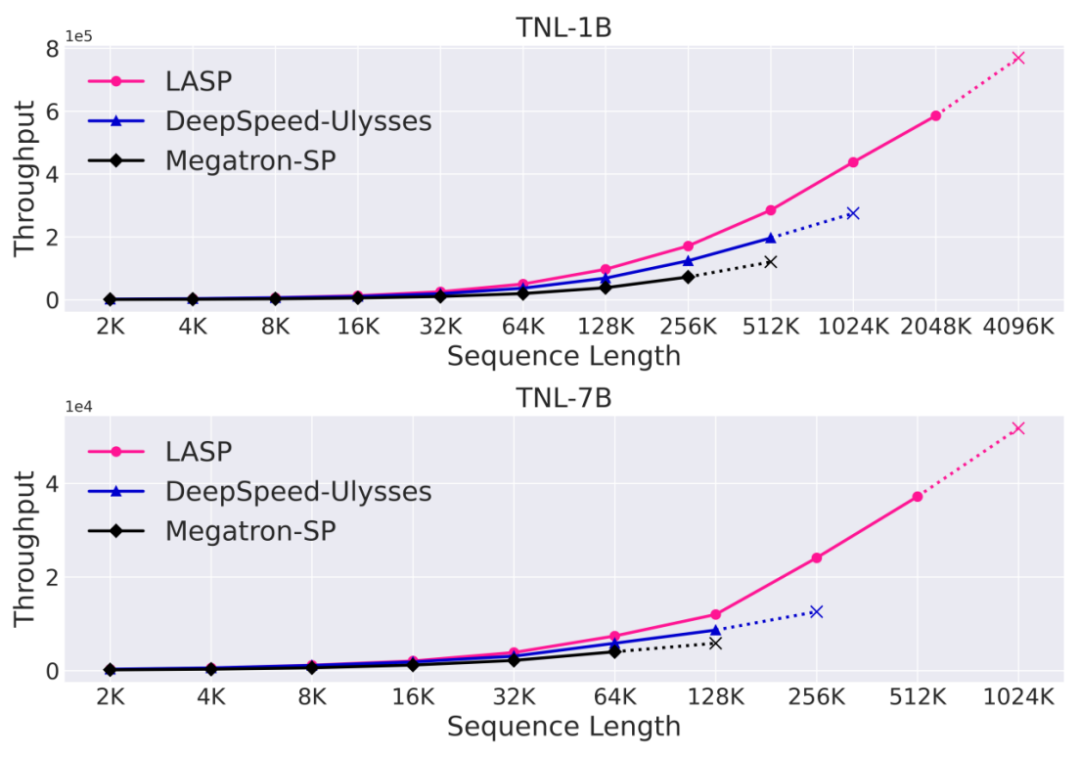
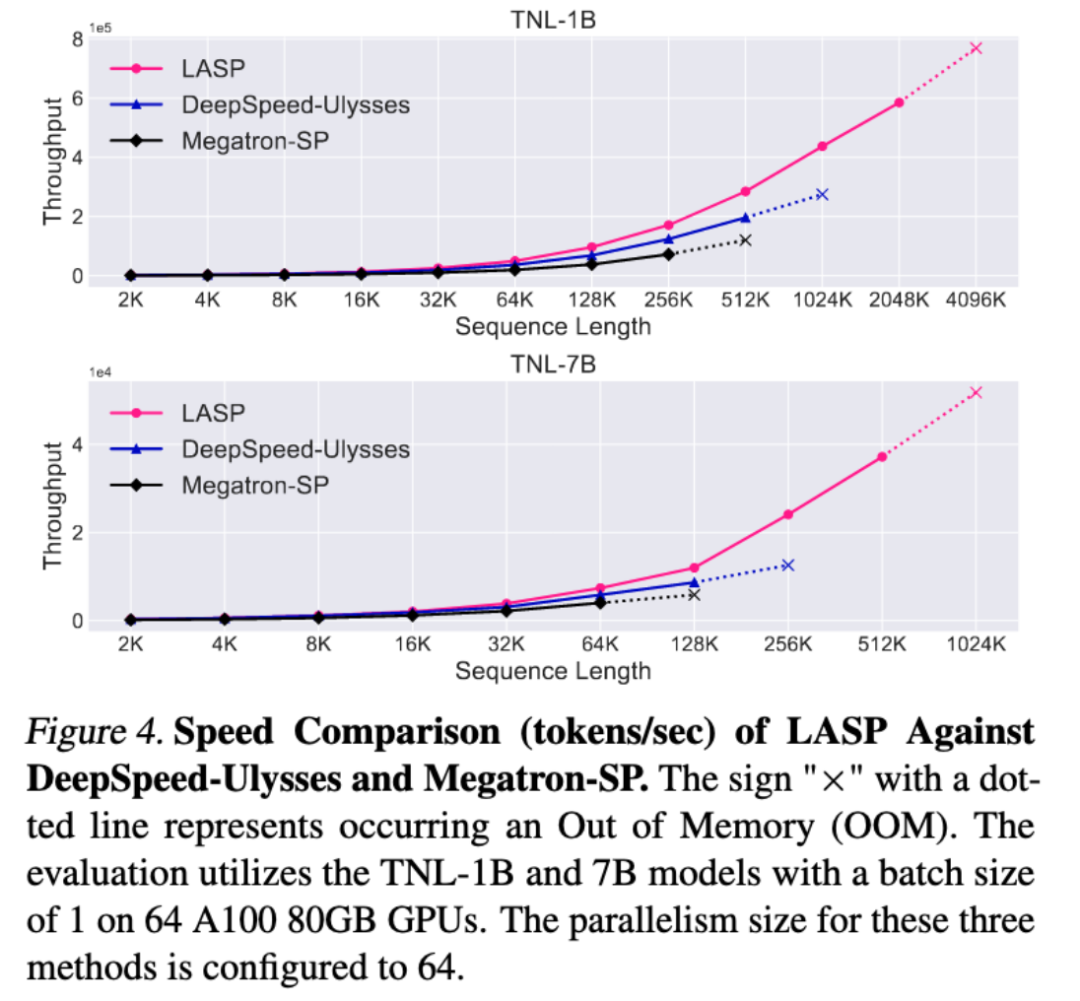
Speed comparison experiment
Compared with the mature sequence parallel methods Megatron-SP and DeepSpeed-Ulysses, LASP is the most trainable The long sequence length is 8 times that of Megatron-SP and 4 times that of DeepSpeed-Ulysses, and the speed is 136% and 38% faster respectively.
Conclusion
In order to facilitate your trial, the author has provided a ready-to-use LASP code implementation without downloading data. Set and model, just use PyTorch to experience the extremely long and extremely fast sequence parallel capabilities of LASP in minutes.
Code portal: https://github.com/OpenNLPLab/LASP
The above is the detailed content of Extremely long sequences, extremely fast: LASP sequence parallelism for a new generation of efficient large language models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to update code in git
Apr 17, 2025 pm 04:45 PM
How to update code in git
Apr 17, 2025 pm 04:45 PM
Steps to update git code: Check out code: git clone https://github.com/username/repo.git Get the latest changes: git fetch merge changes: git merge origin/master push changes (optional): git push origin master
 How to download git projects to local
Apr 17, 2025 pm 04:36 PM
How to download git projects to local
Apr 17, 2025 pm 04:36 PM
To download projects locally via Git, follow these steps: Install Git. Navigate to the project directory. cloning the remote repository using the following command: git clone https://github.com/username/repository-name.git
 How to merge code in git
Apr 17, 2025 pm 04:39 PM
How to merge code in git
Apr 17, 2025 pm 04:39 PM
Git code merge process: Pull the latest changes to avoid conflicts. Switch to the branch you want to merge. Initiate a merge, specifying the branch to merge. Resolve merge conflicts (if any). Staging and commit merge, providing commit message.
 What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
Resolve: When Git download speed is slow, you can take the following steps: Check the network connection and try to switch the connection method. Optimize Git configuration: Increase the POST buffer size (git config --global http.postBuffer 524288000), and reduce the low-speed limit (git config --global http.lowSpeedLimit 1000). Use a Git proxy (such as git-proxy or git-lfs-proxy). Try using a different Git client (such as Sourcetree or Github Desktop). Check for fire protection
 How to use git commit
Apr 17, 2025 pm 03:57 PM
How to use git commit
Apr 17, 2025 pm 03:57 PM
Git Commit is a command that records file changes to a Git repository to save a snapshot of the current state of the project. How to use it is as follows: Add changes to the temporary storage area Write a concise and informative submission message to save and exit the submission message to complete the submission optionally: Add a signature for the submission Use git log to view the submission content
 How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
When developing an e-commerce website, I encountered a difficult problem: How to achieve efficient search functions in large amounts of product data? Traditional database searches are inefficient and have poor user experience. After some research, I discovered the search engine Typesense and solved this problem through its official PHP client typesense/typesense-php, which greatly improved the search performance.
 How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local Git code? Use git fetch to pull the latest changes from the remote repository. Merge remote changes to the local branch using git merge origin/<remote branch name>. Resolve conflicts arising from mergers. Use git commit -m "Merge branch <Remote branch name>" to submit merge changes and apply updates.
 How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
To delete a Git repository, follow these steps: Confirm the repository you want to delete. Local deletion of repository: Use the rm -rf command to delete its folder. Remotely delete a warehouse: Navigate to the warehouse settings, find the "Delete Warehouse" option, and confirm the operation.
