
 Technology peripherals
AI
The first 100% open source large model in history is here! Record-breaking disclosure of code/weights/data sets/whole training process, AMD can train it
Technology peripherals
AI
The first 100% open source large model in history is here! Record-breaking disclosure of code/weights/data sets/whole training process, AMD can train it
The first 100% open source large model in history is here! Record-breaking disclosure of code/weights/data sets/whole training process, AMD can train it

For many years, language models have been the core of natural language processing (NLP) technology. In view of the huge commercial value behind the model, the technical details of the most advanced model have not been made public.
Now, the truly completely open source large model is here!
Researchers from the Allen Institute for Artificial Intelligence, the University of Washington, Yale University, New York University, and Carnegie Mellon University recently collaborated to publish an important work, this The work will become an important milestone for the AI open source community.
They will open source almost all the data and information in the process of training a large model from scratch!
Paper: https://allenai.org/olmo/olmo-paper.pdf
## Weight: https://huggingface.co/allenai/OLMo-7B
Code: https://github.com/allenai/OLMo
Data: https://huggingface.co/datasets/allenai/dolma
Evaluation: https://github.com/allenai/OLMo-Eval
Adaptation: https://github.com/allenai/open-instruct

Training and modeling: It includes complete model weights, training code, training logs, ablation studies, training metrics, and inference code.
Pre-training corpus: A pre-training open source corpus containing up to 3T tokens, as well as the code to generate these training data.
Model parameters: The OLMo framework provides four different architectures, optimizers and training hardware There are 7B size models under the system and a 1B size model. All models are trained on at least 2T tokens.
At the same time, the code used for model inference, various indicators of the training process, and training logs are also provided.
Evaluation Tools: exposes a suite of evaluation tools during the development process, including more than 500 checks included in every 1000 steps of each model training process points as well as the evaluation code.
All data are licensed for use under apache 2.0 (free for commercial use).

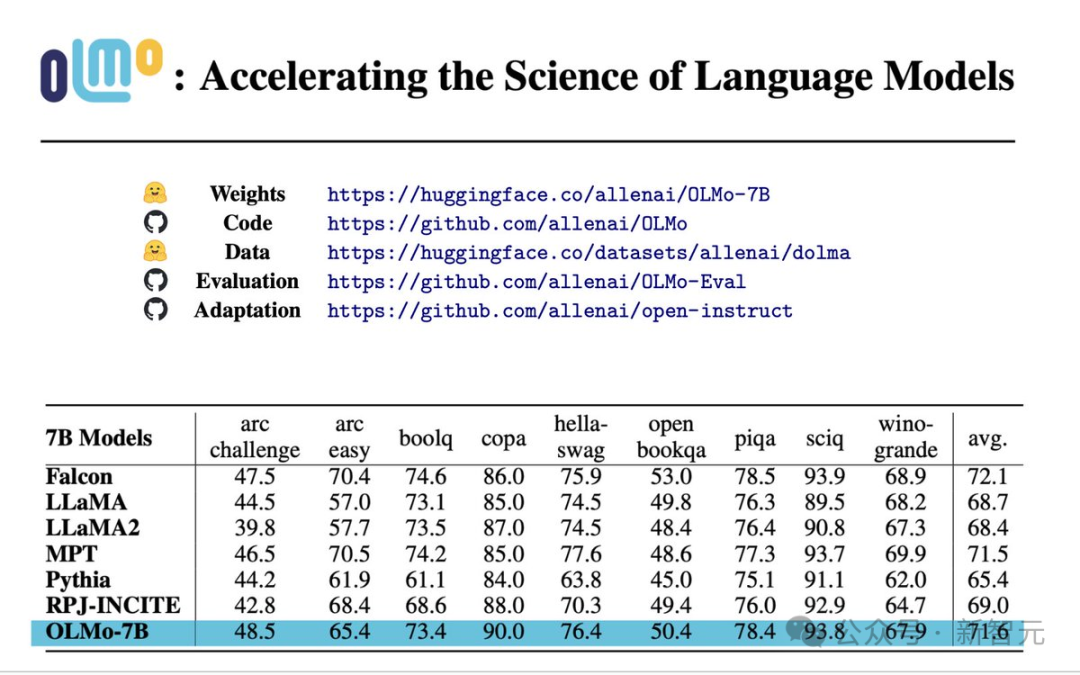
Performance Evaluation
From the core evaluation results, OLMo-7B is slightly better than similar open source models.Among the first 9 evaluations, OLMo-7B ranked in the top three in 8, and 2 of them surpassed all other models.
On many generation tasks or reading comprehension tasks (such as truthfulQA), OLMo-7B surpasses Llama 2, but on some popular question and answer tasks (such as MMLU or Big-bench Hard ), the performance is worse.
The first 9 tasks are the researchers’ internal evaluation criteria for the pre-trained model, while the following three tasks are added to improve the HuggingFace Open LLM rankings
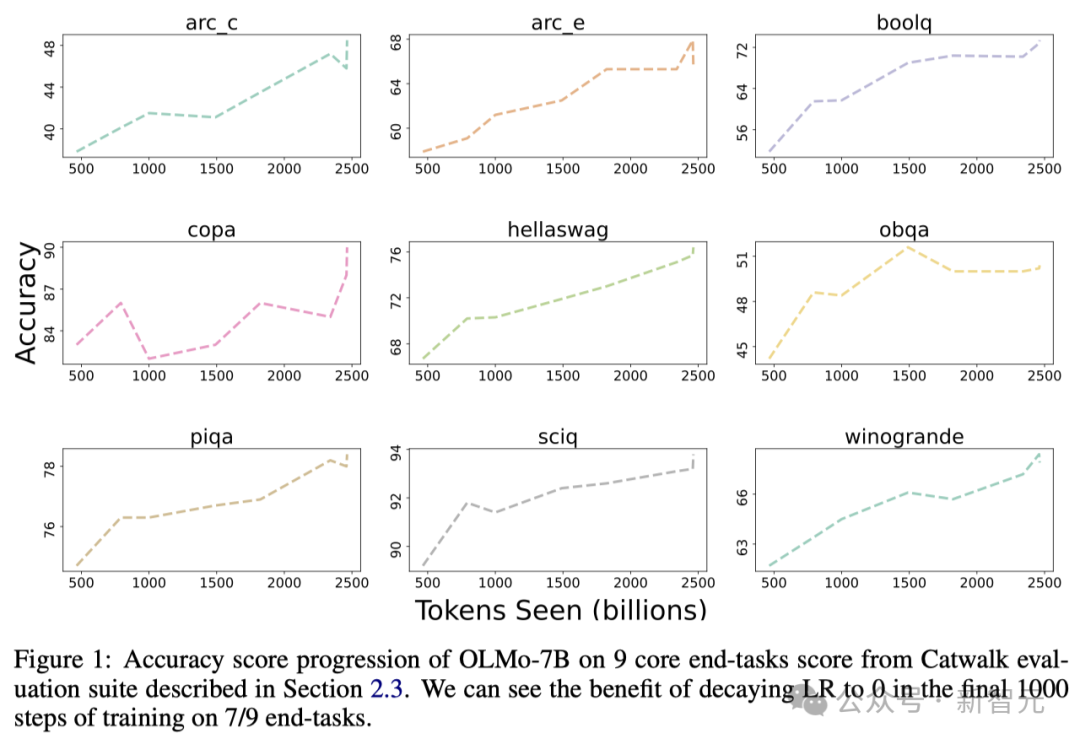
The figure below shows the changing trend of the accuracy of 9 core tasks.
Except for OBQA, as OLMo-7B receives more data for training, the accuracy of almost all tasks shows an upward trend.
Meanwhile, the core evaluation results of OLMo 1B and its similar models show that OLMo is on the same level as them.
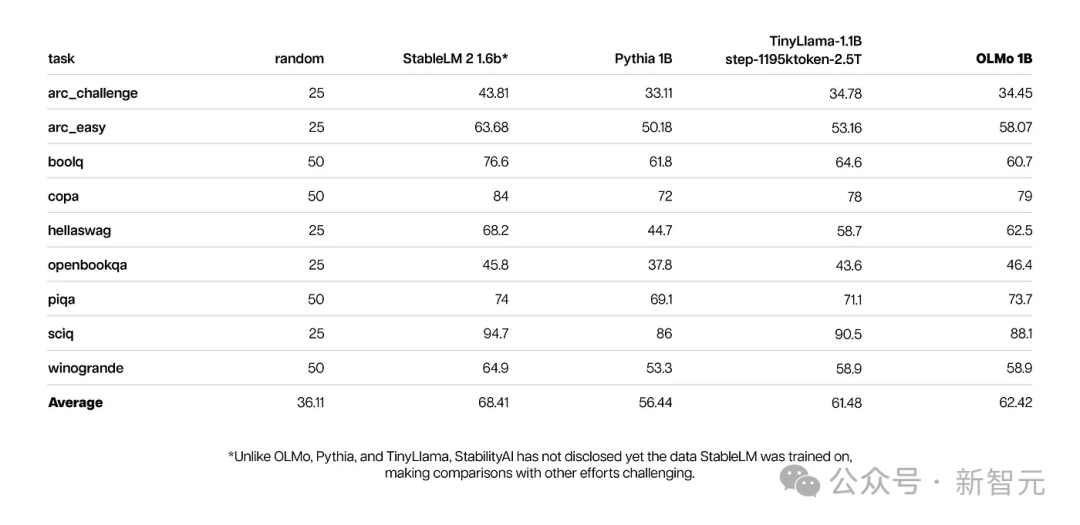
By using the Allen AI Institute’s Paloma, a benchmark, and accessible checkpoints, the researchers analyzed the model’s ability to predict language Relationship with model size factors (such as the number of tokens trained).
It can be seen that OLMo-7B is on par with mainstream models in performance. Among them, the lower the number of bits per byte (Bits per Byte), the better.
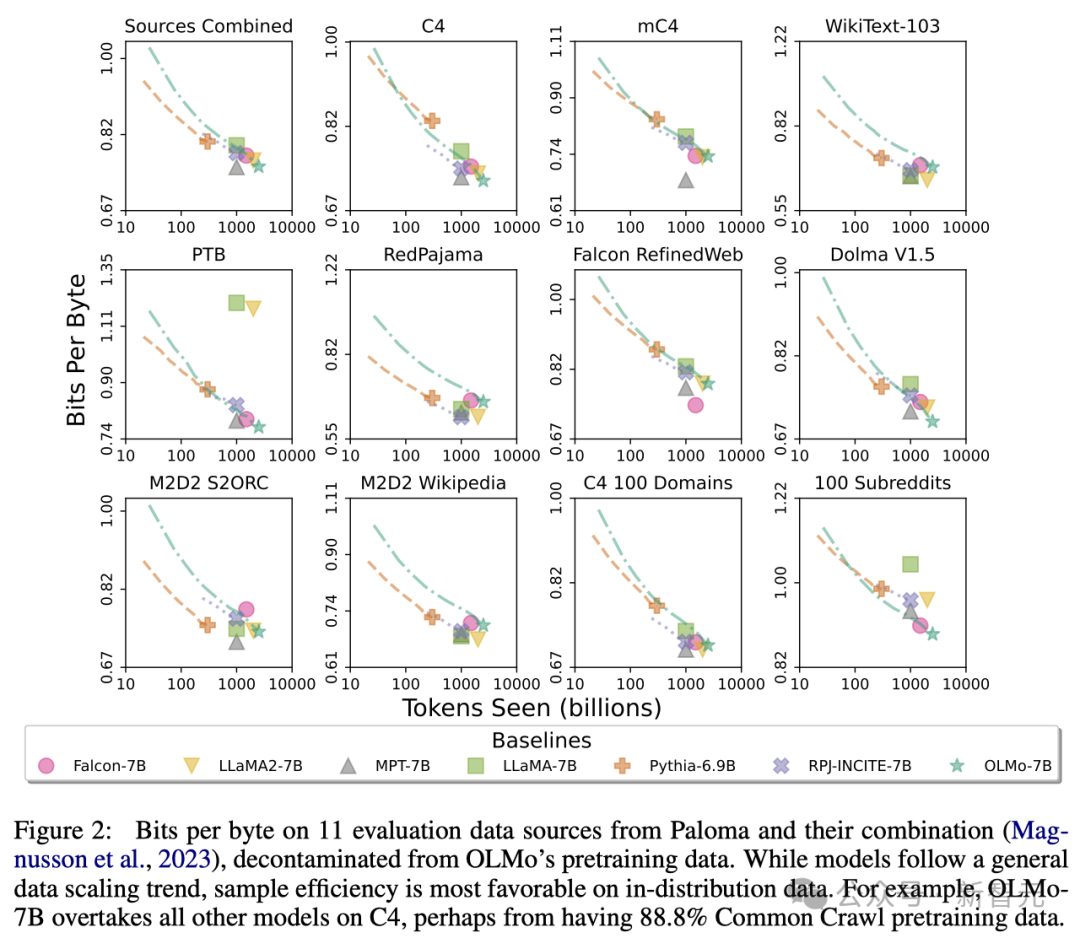
Through these analyses, the researchers found that the efficiency of the models in processing different data sources varies greatly, which mainly depends on the model training data and evaluation Data similarity.
In particular, OLMo-7B performs well on data sources mainly based on Common Crawl (such as C4).
However, OLMo-7B is less efficient than other models on data sources that have little to do with web scraping text, such as WikiText-103, M2D2 S2ORC and M2D2 Wikipedia .
RedPajama's evaluation also reflects a similar trend, possibly because only 2 of its 7 fields are derived from Common Crawl, and Paloma's evaluation of each field in each data source given equal weight.
Given that curated data sources like Wikipedia and arXiv papers provide far less heterogeneous data than web scraped text, maintaining an understanding of these as pre-training datasets continue to expand Efficient language distribution will be more difficult.
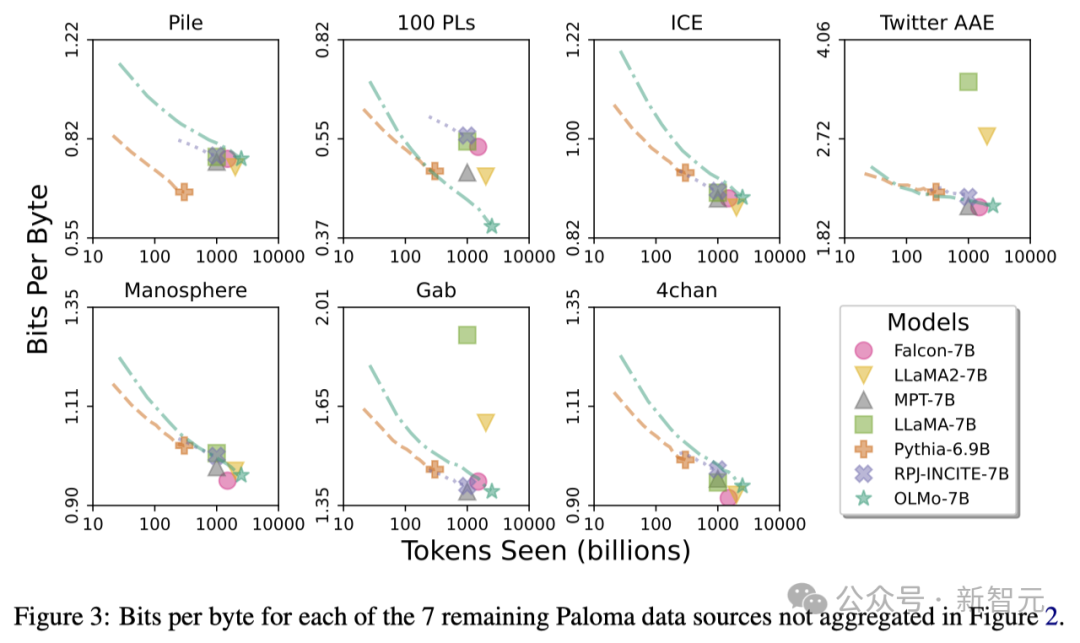
OLMo Architecture
In terms of model architecture, the team is based on the decoder-only Transformer architecture and adopts PaLM and the SwiGLU activation function used by Llama, introduced Rotated Position Embedding (RoPE), and improved GPT-NeoX-20B’s Byte Pair Encoding (BPE)-based tokenizer to reduce personally identifiable information in the model output.
In addition, in order to ensure the stability of the model, the researchers did not use bias terms (this is the same as PaLM).
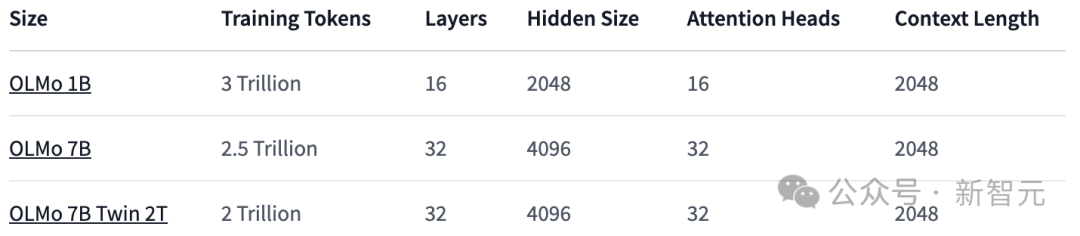
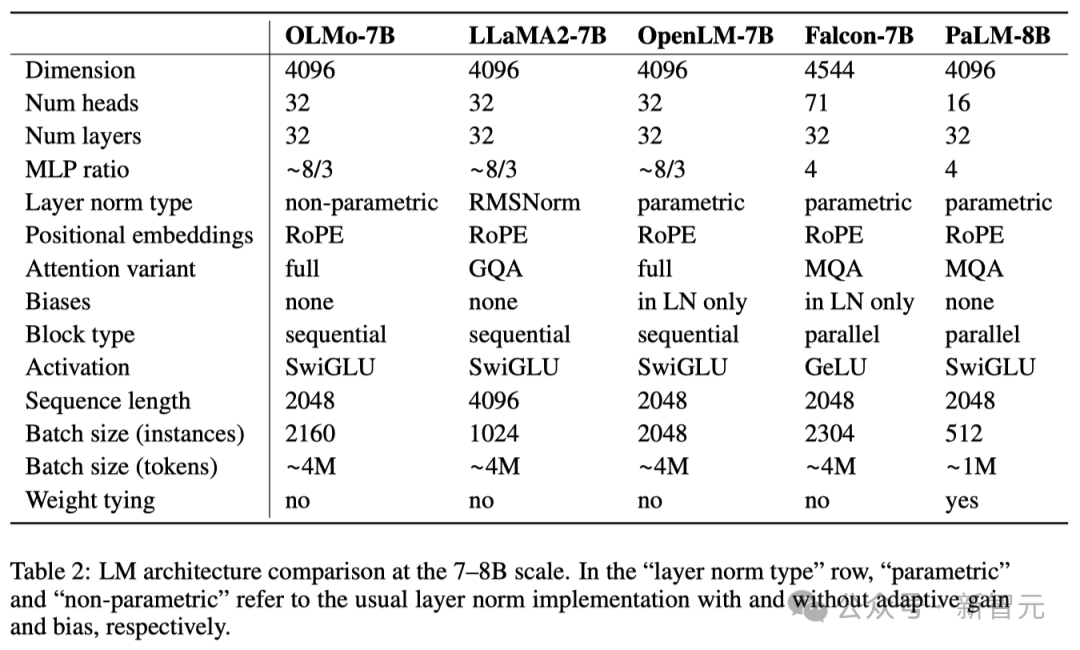
As shown in the table below, the researchers have released two versions, 1B and 7B, and also plan to launch a 65B version soon.
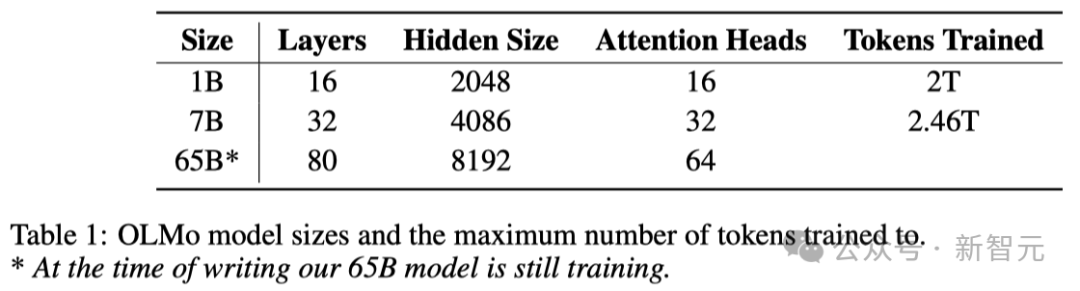
The table below details the performance of the 7B architecture with these other models at similar scales.
Pre-training data set: Dolma
Although researchers have made certain progress in obtaining model parameters progress, but the current openness of pre-training data sets in the open source community is far from enough.
Previous pre-training data is often not made public with the open source of the model (let alone closed source models).
And the documentation about these data often lacks sufficient details that are crucial to replicating the research or fully understanding the related work.
This situation makes language model research more difficult—for example, understanding how training data affects model capabilities and its limitations.
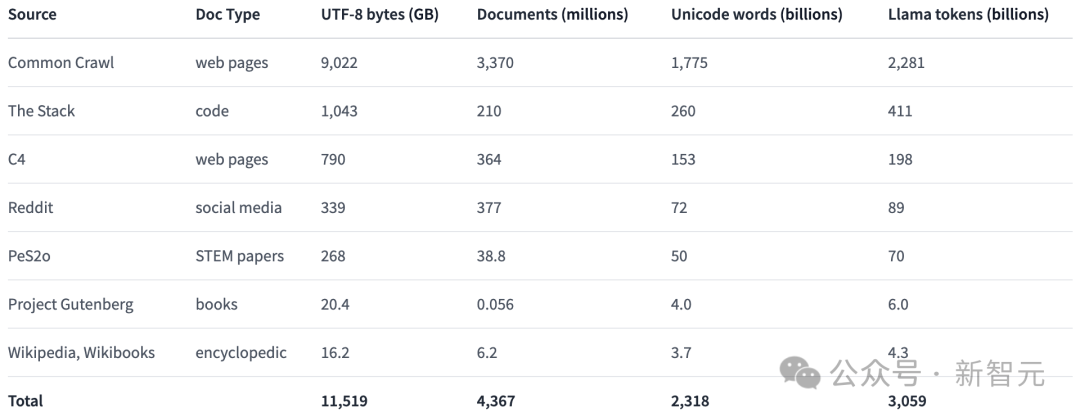
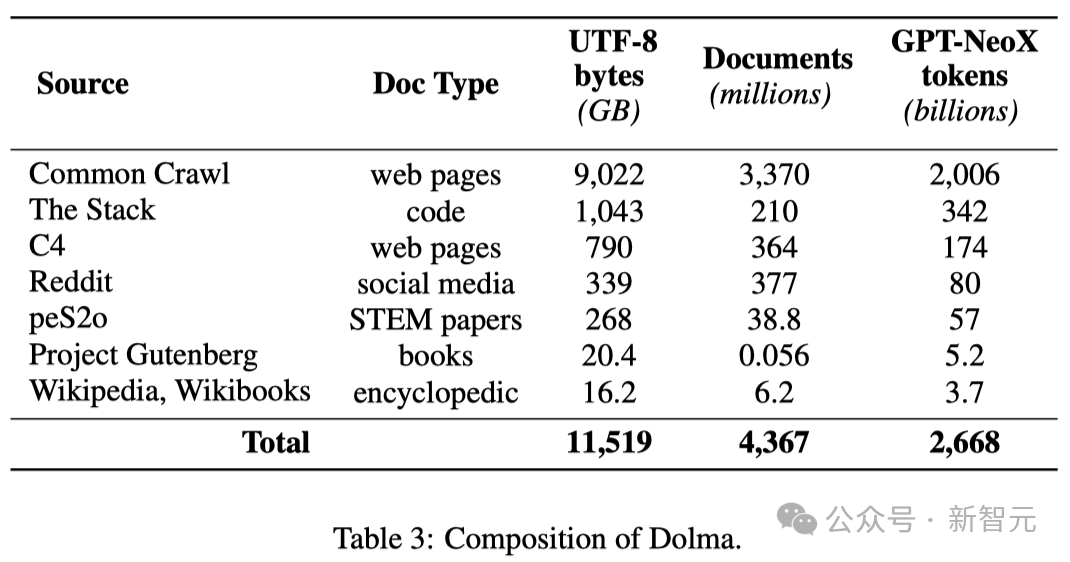
In order to promote open research in the field of language model pre-training, researchers constructed and made public the pre-training data set Dolma.
This is a diverse, multi-source corpus containing 3 trillion tokens obtained from 7 different data sources.
On the one hand, these data sources are common in large-scale language model pre-training, and on the other hand, they are also accessible to the general public.
The table below gives an overview of the data volume from various data sources.
Dolma’s construction process includes six steps: language filtering, quality filtering, content filtering, deduplication, multi-source mixing and tokenization.
During the process of collating and final publishing Dolma, researchers ensured that documents from each data source remained independent.
They also open sourced a set of efficient data sorting tools, which can help further study Dolma, replicate results, and simplify the sorting of pre-training corpus.
In addition, researchers have also open sourced the WIMBD tool to facilitate data set analysis.

Network data processing process

Code processing process
Training OLMo
Distributed training framework
The researchers used PyTorch’s FSDP framework and ZeRO optimizer strategy to train the model . This approach effectively reduces memory usage by splitting the model’s weights and their corresponding optimizer states across multiple GPUs.
When processing models up to 7B in size, this technology enables researchers to process micro-batch sizes of 4096 tokens per GPU for more efficient training.
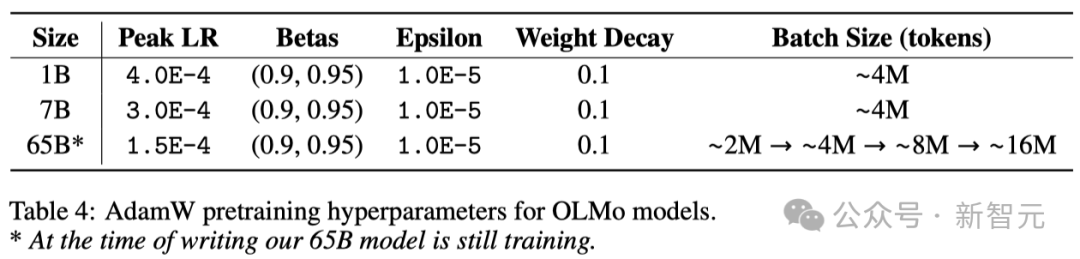
For the OLMo-1B and 7B models, the researchers fixed a global batch size of approximately 4M tokens (2048 data instances, each instance containing a sequence of 2048 tokens).
For the OLMo-65B model currently being trained, the researchers adopted a batch size warm-up strategy, starting at about 2M tokens (1024 data instances), and then every Adding 100B tokens doubles the batch size until it finally reaches about 16M tokens (8192 data instances).
In order to speed up model training, the researchers used mixed precision training technology, which is used through the internal configuration of FSDP and PyTorch This is implemented using the amp module.
This method is specially designed to ensure that some key calculation steps (such as the softmax function) are always performed with the highest accuracy to ensure the stability of the training process.
Meanwhile, most other calculations use a half-precision format called bfloat16 to reduce memory usage and increase computational efficiency.
In specific configurations, model weights and optimizer state are saved with maximum accuracy on each GPU.
Only when performing forward propagation and back propagation of the model, that is, calculating the output of the model and updating the weights, the weights within each Transformer module will be temporarily converted to bfloat16 format.
In addition, when gradient updates are synchronized between GPUs, they will also be performed with the highest accuracy to ensure training quality.
Optimizer
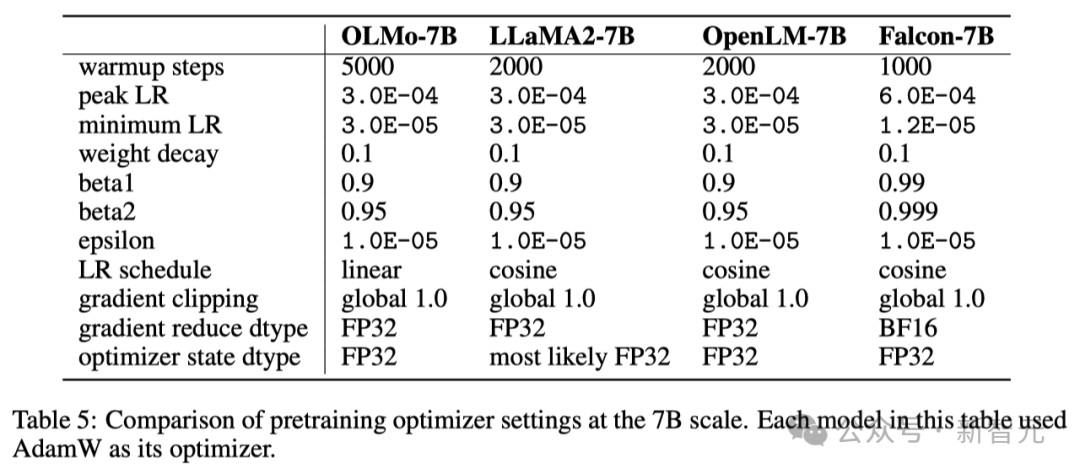
The researchers used the AdamW optimizer to adjust model parameters.
Regardless of the size of the model, researchers will gradually increase the learning rate within the first 5,000 steps of training (approximately processing 21B tokens). This process is called learning rate warm-up.
After the warm-up is completed, the learning rate will gradually decrease linearly until it drops to one-tenth of the maximum learning rate.
In addition, the researchers will also clip the gradients of the model parameters to ensure that their total L1 norm does not exceed 1.0.
In the table below, the researchers compare their optimizer configuration at 7B model scale to other recent large language models using the AdamW optimizer.
Dataset
The researchers used a 2T token sample in the open data set Dolma, constructed their training data set.
The researchers connected the tokens of each document, added a special EOS token at the end of each document, and then divided these tokens into groups of 2048 to form training samples. .
These training samples will be randomly shuffled in the same way during each training. The researchers also provide tools that allow anyone to recover the specific data order and composition of each training batch.
All models that researchers have released have been trained for at least one round (2T tokens). Some of these models were additionally trained by running a second round of training on the data, but with a different random shuffling order.
According to previous research, the impact of reusing a small amount of data in this way is minimal.
NVIDIA and AMD both want YES!
In order to ensure that the code base can run efficiently on both NVIDIA and AMD GPUs, the researchers selected two different clusters for model training and testing:
Using the LUMI supercomputer, researchers deployed up to 256 nodes, each equipped with 4 AMD MI250X GPUs. Each GPU has 128GB of memory and a data transfer rate of 800Gbps.
With the support of MosaicML (Databricks), the researchers used 27 nodes, each node is equipped with 8 NVIDIA A100 GPUs, each GPU has 40GB memory and 800Gbps data transmission rate.
Although the researchers fine-tuned the batch size to improve training efficiency, after completing the evaluation of 2T tokens, there was almost no difference in the performance of the two clusters.
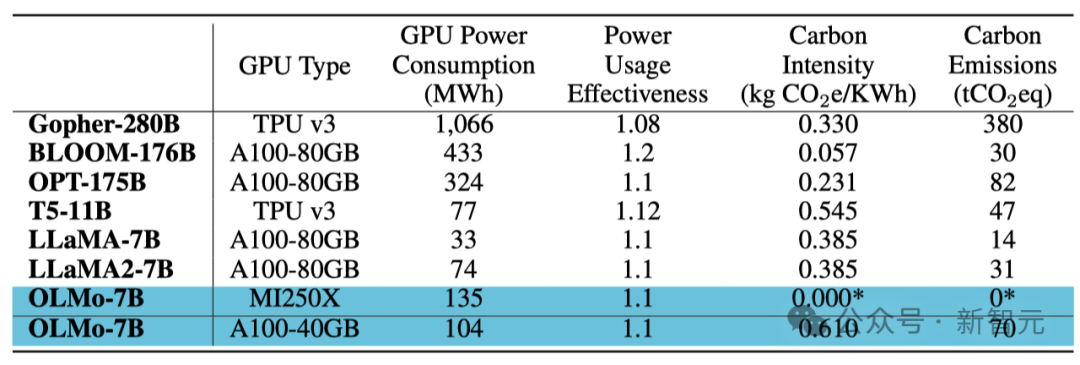
Training energy consumption
Summary
Unlike most previous models that only provide models The models of weight and inference code are different. The researchers open sourced all the contents of OLMo, including training data, training and evaluation code, as well as training logs, experimental results, important findings, records of Weights & Biases, etc.
Additionally, the team is studying how to improve OLMo through instruction optimization and different types of reinforcement learning (RLHF). These fine-tuned codes, data and fine-tuned models will also be open source.
Researchers are committed to continuously supporting and developing OLMo and its framework, promoting the development of open language models (LM), and assisting the development of open research communities. To this end, the researchers plan to introduce more models of different scales, multiple modalities, data sets, security measures and evaluation methods to enrich the OLMo family.
They hope that through continued thorough open source work in the future, they will strengthen the power of the open source research community and trigger a new wave of innovation.
Team introduction
Yizhong Wang (王义中)

Yizhong Wang is Washington PhD student in the university's Paul G. Allen School of Computer Science and Engineering, mentored by Hannaneh Hajishirzi and Noah Smith. At the same time, he is also a part-time research intern at the Allen Institute for Artificial Intelligence.
Previously, he had interned at Meta AI, Microsoft Research and Baidu NLP. Previously, he received a master's degree from Peking University and a bachelor's degree from Shanghai Jiao Tong University.
His research directions are Natural Language Processing, Machine Learning, and Large Language Model (LLM).
- Adaptability of LLM: How to more efficiently build and evaluate models that can follow instructions? What factors should we consider when fine-tuning these models, and how do they affect the generalizability of the model? Which types of supervision are both effective and scalable?
- Continuous learning for LLM: Where is the boundary between pre-training and fine-tuning? What architectures and learning strategies can allow LLM to continue to evolve after pre-training? How does existing knowledge within the model interact with newly learned knowledge?
- Application of large-scale synthetic data: Today, when generative models rapidly generate data, what impact does this data have on our model development and even the entire Internet and society? How do we ensure we can generate diverse and high-quality data at scale? Can we distinguish this data from human-generated data?
Yuling Gu

##Yuling Gu is a member of the Aristo team at the Allen Institute for Artificial Intelligence (AI2) A researcher.
In 2020, she received her bachelor’s degree from New York University (NYU). In addition to her computer science major, she also minored in an interdisciplinary major, Language and Mind, which combines linguistics, psychology, and philosophy. She subsequently earned a master's degree from the University of Washington (UW).
She is full of enthusiasm for the integration and application of machine learning technology and cognitive science theory.
The above is the detailed content of The first 100% open source large model in history is here! Record-breaking disclosure of code/weights/data sets/whole training process, AMD can train it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
