
 Technology peripherals
AI
Large-scale models can already annotate images with just a simple conversation! Research results from Tsinghua & NUS
Technology peripherals
AI
Large-scale models can already annotate images with just a simple conversation! Research results from Tsinghua & NUS
Large-scale models can already annotate images with just a simple conversation! Research results from Tsinghua & NUS

After the multi-modal large model integrates the detection and segmentation module, image cutout becomes easier!
Our model can quickly label the objects you are looking for through natural language descriptions and provide text explanations to allow you to easily complete the task.
The new multi-modal large model developed by the NExT Laboratory of the National University of Singapore and Liu Zhiyuan's team at Tsinghua University provides us with strong support. This model has been carefully crafted to provide players with comprehensive help and guidance during the puzzle-solving process. It combines information from multiple modalities to present players with new puzzle-solving methods and strategies. The application of this model will benefit players

With the launch of GPT-4v, the multimodal field has ushered in a series of new models, such as LLaVA, BLIP-2, etc. wait. The emergence of these models has made great contributions in improving the performance and effectiveness of multi-modal tasks.
In order to further improve the regional understanding capabilities of multi-modal large models, the research team developed a multi-modal model called NExT-Chat. This model has the ability to conduct dialogue, detection, and segmentation simultaneously.
The biggest highlight of NExT-Chat is the ability to introduce positional input and output into its multi-modal model. This feature enables NExT-Chat to more accurately understand and respond to user needs during interaction. Through location input, NExT-Chat can provide relevant information and suggestions based on the user's geographical location, thereby improving the user experience. Through location output, NExT-Chat can convey relevant information about specific geographical locations to users to help them better
Among them, the location input capability refers to answering questions based on the specified area, while the location output capability is Specifies the location of the object mentioned in the conversation. These two abilities are very important in puzzle games.

Even complex positioning problems can be solved:

In addition to object positioning, NExT-Chat can also Describe the image or a part of it:
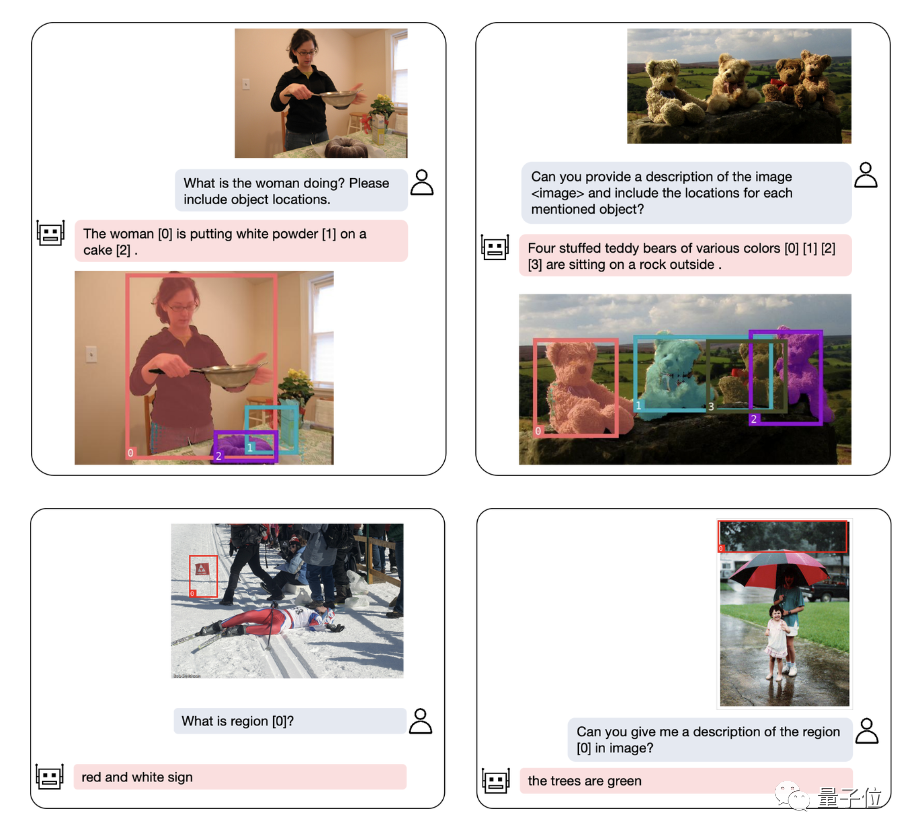
After analyzing the content of the image, NExT-Chat can use the obtained information to make inferences:

In order to accurately evaluate the performance of NExT-Chat, the research team conducted tests on multiple task data sets.
Achieve SOTA on multiple data sets
The author first showed the experimental results of NExT-Chat on the referential expression segmentation (RES) task.
Although only using a very small amount of segmentation data, NExT-Chat has demonstrated good referential segmentation capabilities, even defeating a series of supervised models (such as MCN, VLT, etc.) and using 5 times LISA method for segmentation mask annotation above.
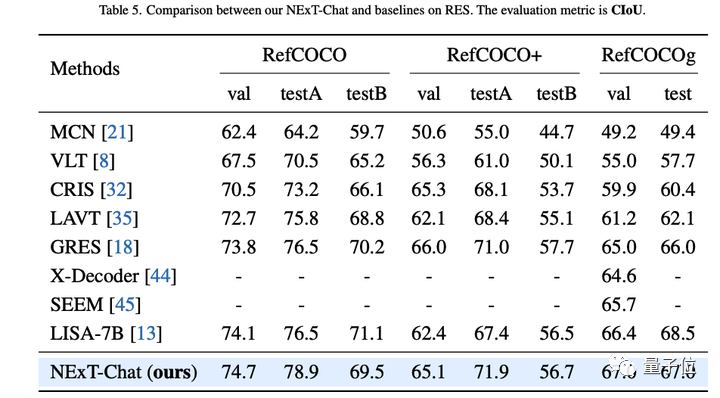
△NExT-Chat results on the RES task
Then, the research team showed the experimental results of NExT-Chat on the REC task.
As shown in the table below, NExT-Chat can achieve better results than a series of supervised methods (such as UNITER).
An interesting finding is that NExT-Chat is slightly less effective than Shikra, which uses similar box training data.
The author speculates that this is due to the fact that LM loss and detection loss in the pix2emb method are more difficult to balance, and Shikra is closer to the pre-training form of the existing plain text large model.
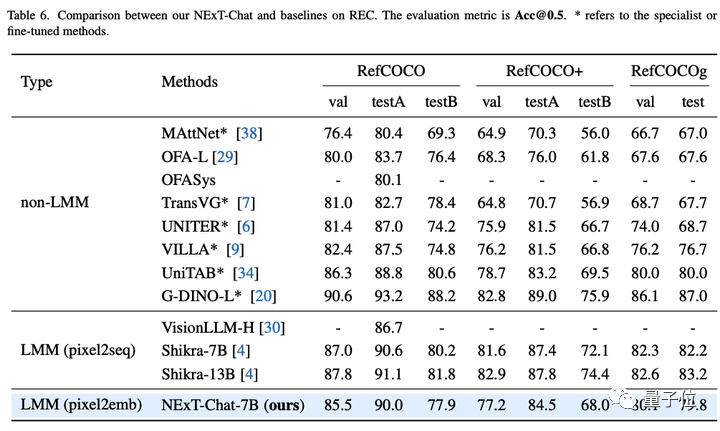
NExT-Chat results on △REC task
On the image illusion task, as shown in Table 3, NExT-Chat can perform on Random and Popular data achieve the best accuracy on the set.
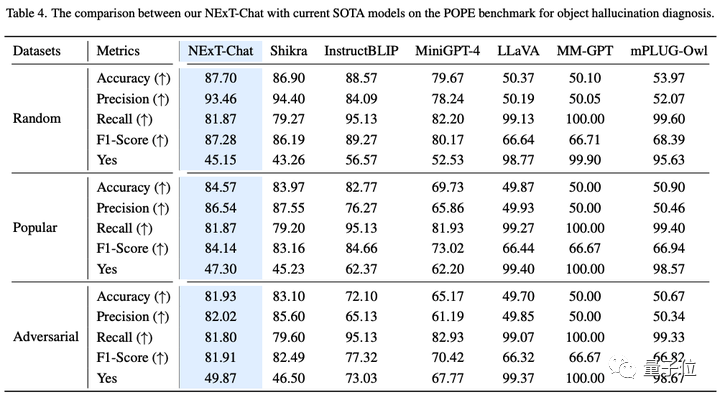
△NExT-Chat results on the POPE data set
In the area description task, NExT-Chat can also achieve the best CIDEr performance, and beat Kosmos- in the 4-shot case in this indicator. 2.
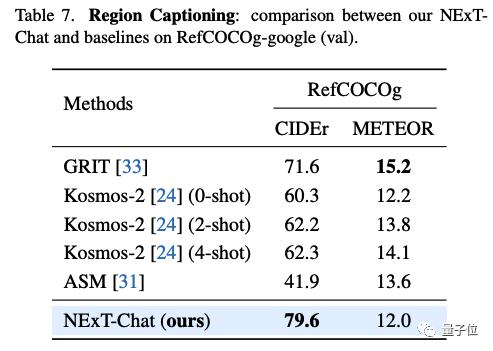
NExT-Chat results on △RefCOCOg data set
So, what methods are used behind NExT-Chat?
Propose a new method of image coding
Defects of traditional methods
The traditional model mainly performs LLM-related position modeling through pix2seq.
For example, Kosmos-2 divides the image into 32x32 blocks and uses the id of each block to represent the coordinates of the point; Shikra converts the coordinates of the object frame into plain text so that LLM can understand the coordinates. .
However, the model output using the pix2seq method is mainly limited to simple formats such as boxes and points, and it is difficult to generalize to other denser position representation formats, such as segmentation mask.
In order to solve this problem, this article proposes a new embedding-based position modeling method pix2emb.
pix2emb method
Different from pix2seq, all position information of pix2emb is encoded and decoded through the corresponding encoder and decoder, rather than relying on the text prediction header of LLM itself.
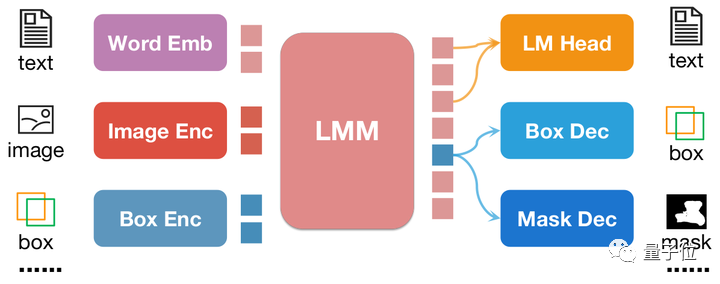
Simple example of △pix2emb method
As shown in the figure above, the position input is encoded into position embedding by the corresponding encoder, and the output position embedding is passed through Box Decoder and Mask Decoder convert to boxes and masks.
This brings two benefits:
- The output format of the model can be easily extended to more complex forms, such as segmentation mask.
- The model can easily locate the existing practical methods in the task. For example, the detection loss in this article uses L1 Loss and GIoU Loss (pix2seq can only use text to generate loss). The mask decoder in this article makes use of the existing methods. SAM to do the initialization.
By combining pix2seq with pix2emb, the author trained a new NExT-Chat model.
NExT-Chat model
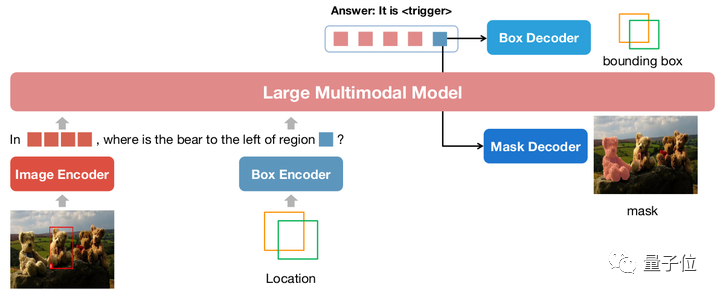
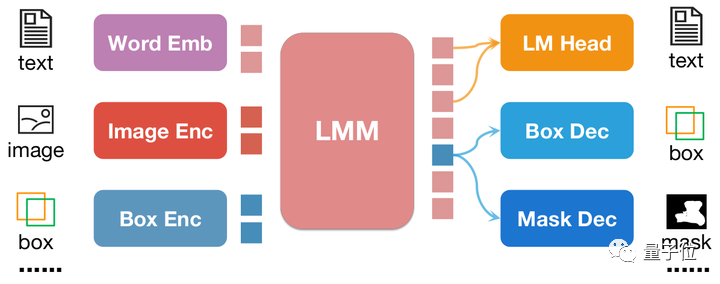
△NExT-Chat model architecture
NExT-Chat adopts the LLaVA architecture as a whole, that is, through Image Encoder To encode image information and input it into LLM for understanding, and on this basis, the corresponding Box Encoder and the Decoder for two position outputs are added.
In order to solve the problem of LLM not knowing when to use the language's LM head or the position decoder, NExT-Chat additionally introduces a new token type to identify position information.
If the model outputs, the embedding of the token will be sent to the corresponding position decoder for decoding instead of the language decoder.
In addition, in order to maintain the consistency of position information in the input stage and output stage, NExT-Chat introduces an additional alignment constraint:
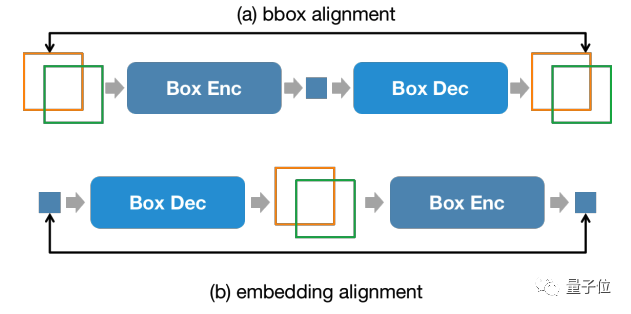
△Position input, Output constraints
As shown in the figure above, the box and position embedding will be combined through the decoder, encoder or decoder-encoder respectively, and are required not to change before and after.
The author found that this method can greatly promote the convergence of position input capabilities.
The model training of NExT-Chat mainly includes three stages:
- The first stage: training modelBasic box input and output basic capabilities. NExT-Chat uses Flickr-30K, RefCOCO, VisualGenome and other data sets containing box input and output for pre-training. During the training process, all LLM parameters will be trained.
- Second stage: Adjust LLM’s instruction following ability. Fine-tuning the data through some Shikra-RD, LLaVA-instruct and other instructions allows the model to better respond to human requirements and output more humane results.
- The third stage: Give the NExT-Chat model segmentation capabilities. Through the above two stages of training, the model already has good position modeling capabilities. The author further extends this capability to mask output. Experiments have found that by using a very small amount of mask annotation data and training time (about 3 hours), NExT-Chat can quickly achieve good segmentation capabilities.
The advantage of such a training process is that the detection frame data is rich and the training overhead is smaller.
NExT-Chat trains basic position modeling capabilities on abundant detection frame data, and can then quickly expand to segmentation tasks that are more difficult and have scarcer annotations.
The above is the detailed content of Large-scale models can already annotate images with just a simple conversation! Research results from Tsinghua & NUS. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
