
 Technology peripherals
AI
Tsinghua University and Zhejiang University lead the explosion of open source visual models, and GPT-4V, LLaVA, CogAgent and other platforms bring revolutionary changes
Technology peripherals
AI
Tsinghua University and Zhejiang University lead the explosion of open source visual models, and GPT-4V, LLaVA, CogAgent and other platforms bring revolutionary changes
Tsinghua University and Zhejiang University lead the explosion of open source visual models, and GPT-4V, LLaVA, CogAgent and other platforms bring revolutionary changes

Currently, GPT-4 Vision has shown amazing capabilities in language understanding and visual processing.
However, for those looking for a cost-effective alternative without compromising performance, open source is an option with unlimited potential.
Youssef Hosni is a foreign developer who provides us with three open source alternatives with absolutely guaranteed accessibility to replace GPT-4V.
The three open source visual language models LLaVa, CogAgent and BakLLaVA have great potential in the field of visual processing and are worthy of our in-depth understanding. The research and development of these models can provide us with more efficient and accurate visual processing solutions. By using these models, we can improve the accuracy and efficiency of tasks such as image recognition, target detection, and image generation, and bring insights to research and applications in the field of visual processing.
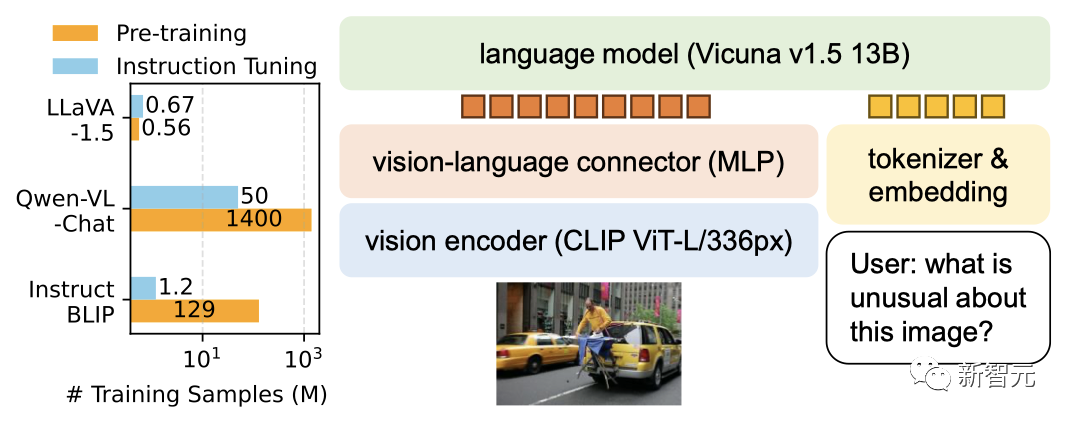
##LLaVa LLaVA is a multi-modal large model developed in collaboration between researchers at the University of Wisconsin-Madison, Microsoft Research, and Columbia University. The initial version was released in April. It combines a visual encoder and Vicuna (for general visual and language understanding) to demonstrate excellent chat capabilities.
LLaVA is a multi-modal large model developed in collaboration between researchers at the University of Wisconsin-Madison, Microsoft Research, and Columbia University. The initial version was released in April. It combines a visual encoder and Vicuna (for general visual and language understanding) to demonstrate excellent chat capabilities.
Picture
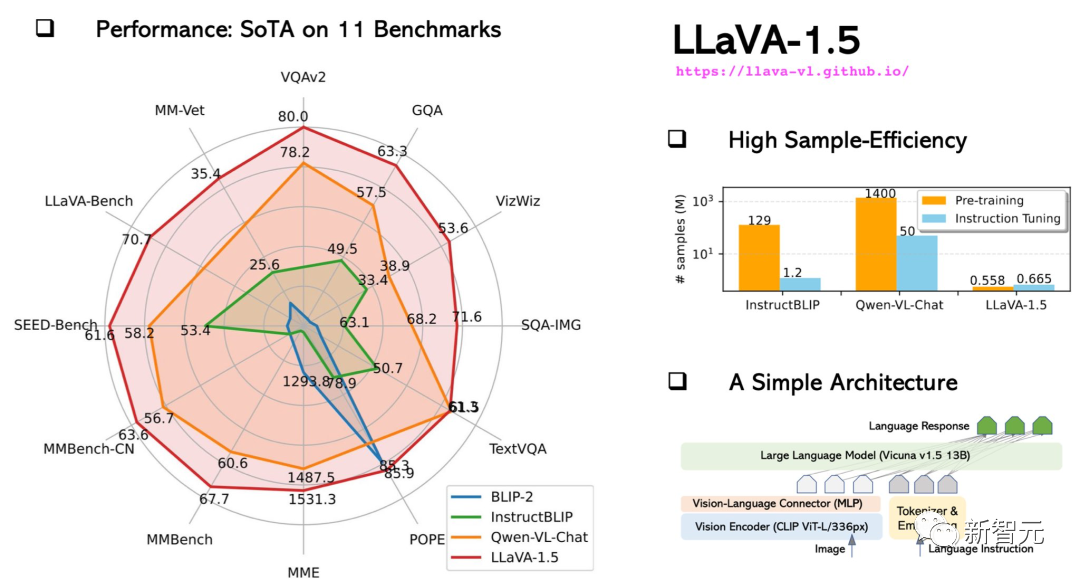
In October, the upgraded LLaVA-1.5 was close to multi-modal GPT-4 in performance, and performed well on the Science QA data set State-of-the-art results (SOTA) were achieved. Picture
Picture
 Picture
Picture
 LLaVA demonstrates some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in visual chat. In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
LLaVA demonstrates some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in visual chat. In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
Picture
In terms of visual reasoning, its performance is very eye-catching. Picture
Picture
 Picture
Picture
 LLaVA still can't answer completely correctly. The upgraded LLaVA-1.5 gave the perfect answer: "There is no desert at all in the picture, but there are palm trees beaches, city skylines and a large body of water."
LLaVA still can't answer completely correctly. The upgraded LLaVA-1.5 gave the perfect answer: "There is no desert at all in the picture, but there are palm trees beaches, city skylines and a large body of water."
Picture
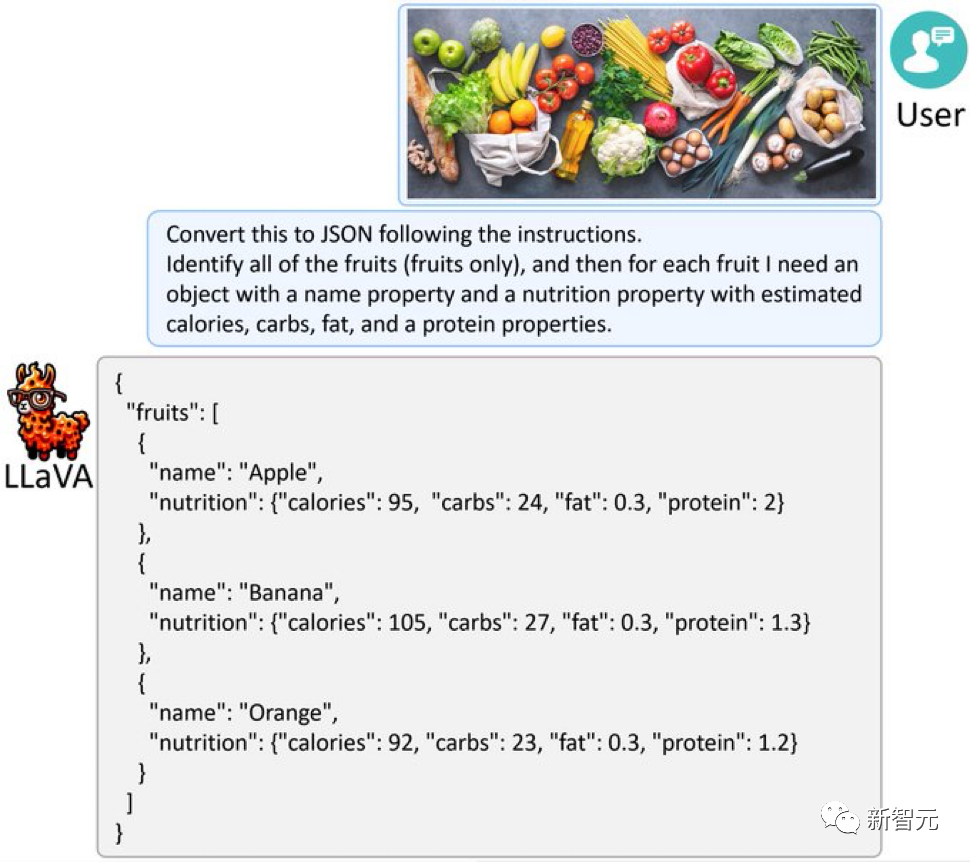
In addition, LLaVA-1.5 can also extract information from the picture and answer according to the required format, such as outputting it in JSON format. Picture
Picture
 Picture
Picture
What does the picture below mean?
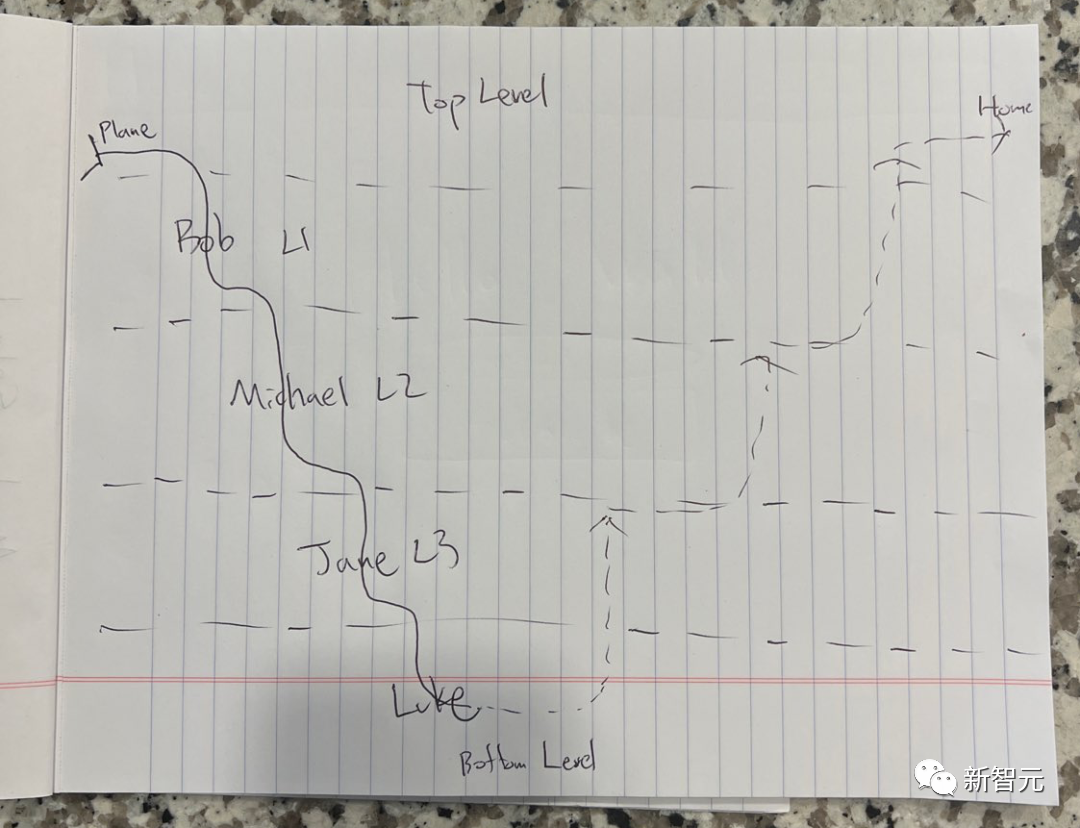 Picture
Picture
This is a simplified sketch based on Nolan's "Inception". In order to increase the difficulty, the character's name has been changed to a pseudonym. .
LLaVA-1.5 surprisingly answered: "This is a picture about the movie "Inception". It shows different levels in the dream world, each level is represented by a line. The picture is written in A piece of paper, the paper is placed on a table."
 Picture
Picture
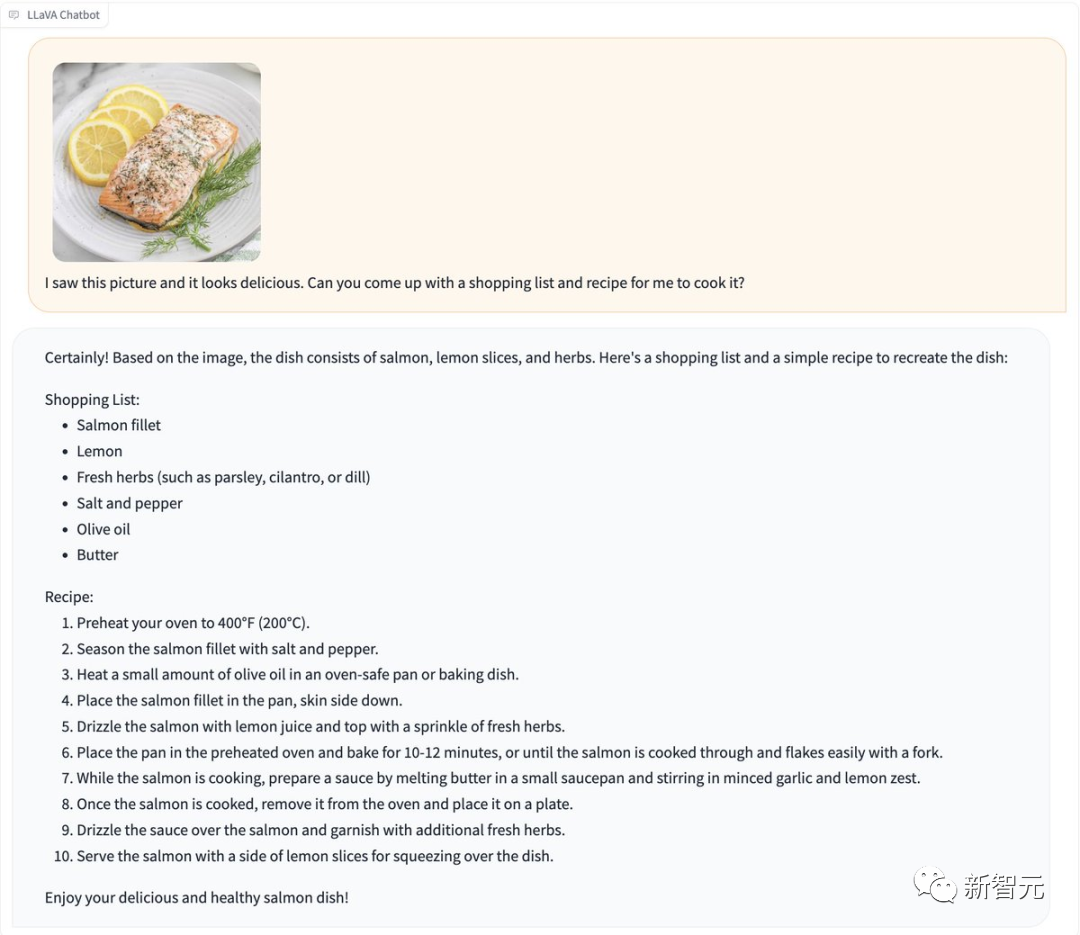
A food picture is sent directly to LLaVA-1.5, and it will be given to you quickly Generate a recipe.
 Picture
Picture
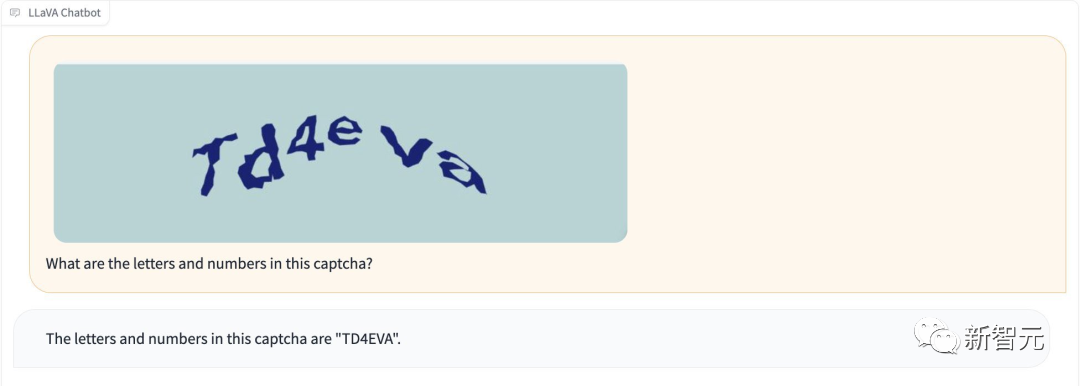
Moreover, LLaVA-1.5 can recognize the verification code without "jailbreaking".
 Picture
Picture
It can also detect what kind of coin is in the picture.
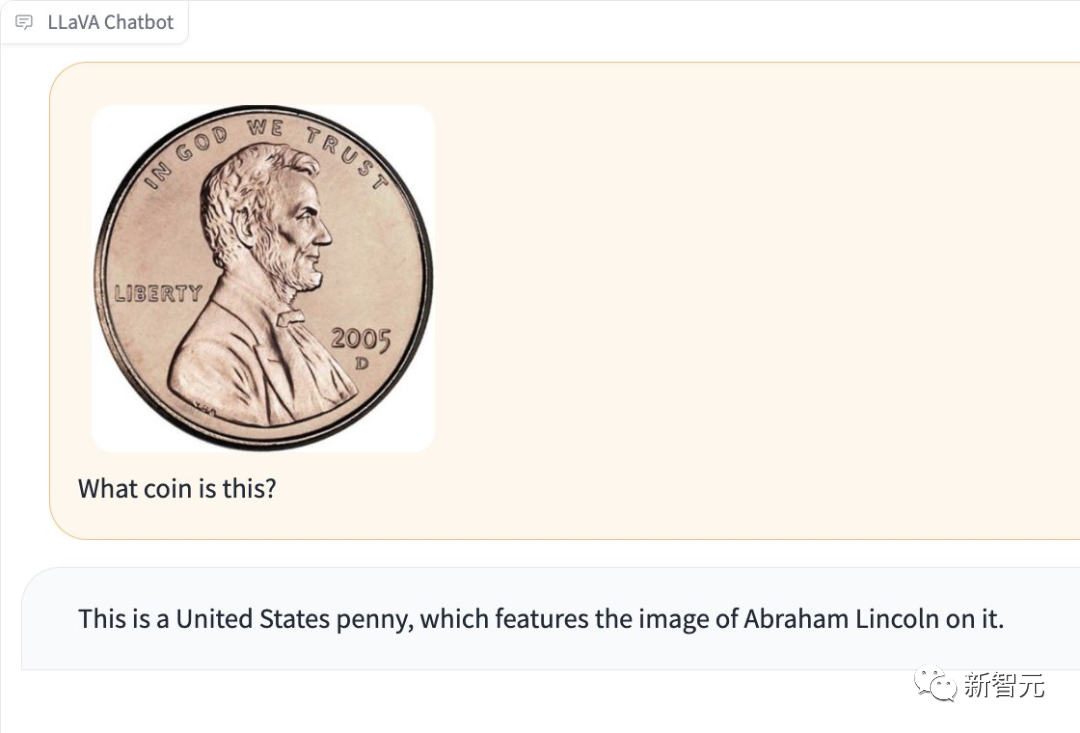 Picture
Picture
What’s particularly impressive is that LLaVA-1.5 can also tell you what breed the dog in the picture is.
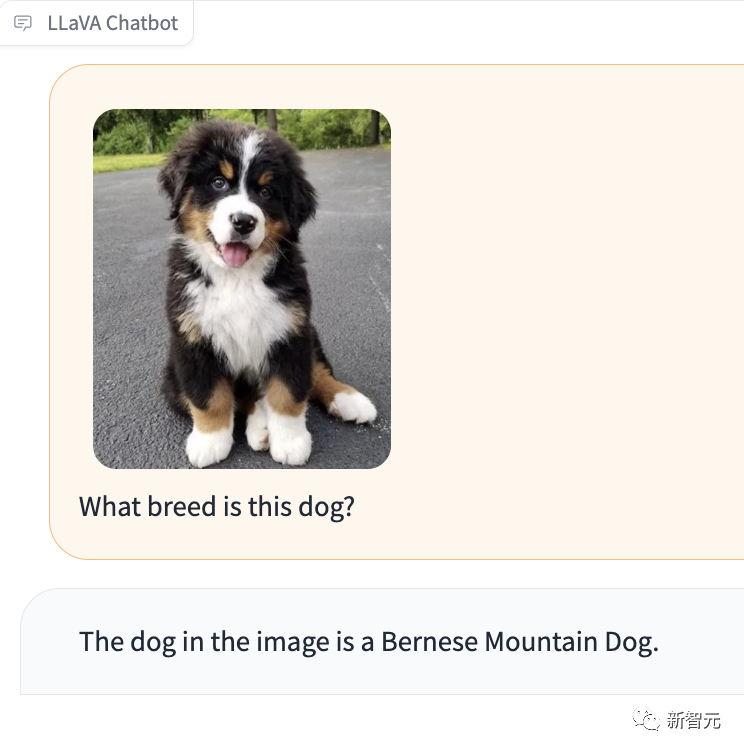 Picture
Picture
Some netizens used Bing to generate a picture of a man wearing a winter coat on a sunny summer beach and asked LLaVA 1.5 to point it out What are the problems in the picture? Its eye is very sharp -
This is a processed or Photoshopped photo, in which a man is wearing a jacket and standing on the beach. The man opened his coat and the sun shone down on him. The problem with this image is that it's not an actual beach scene. The man was not actually standing on the beach and the sun was not shining on him. This image was photoshopped to create the illusion of a beach scene, but it does not truly represent the scene.
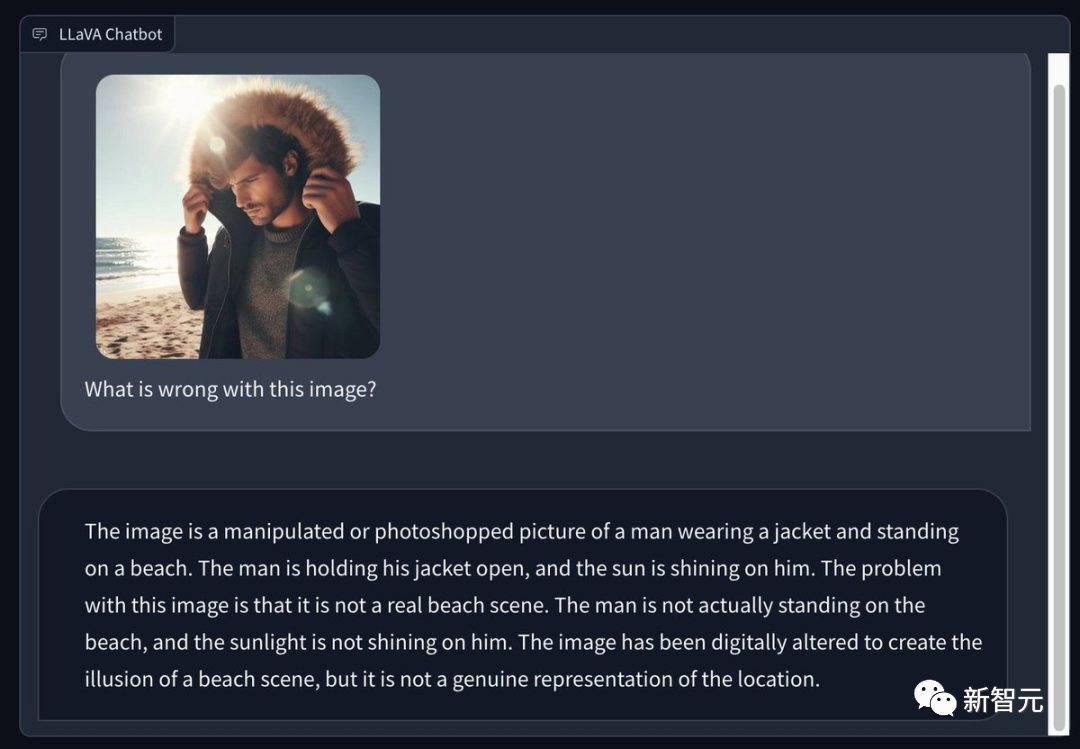 Picture
Picture
OCR recognition, LLaVA’s performance is also very powerful.
 Picture
Picture
 Picture
Picture
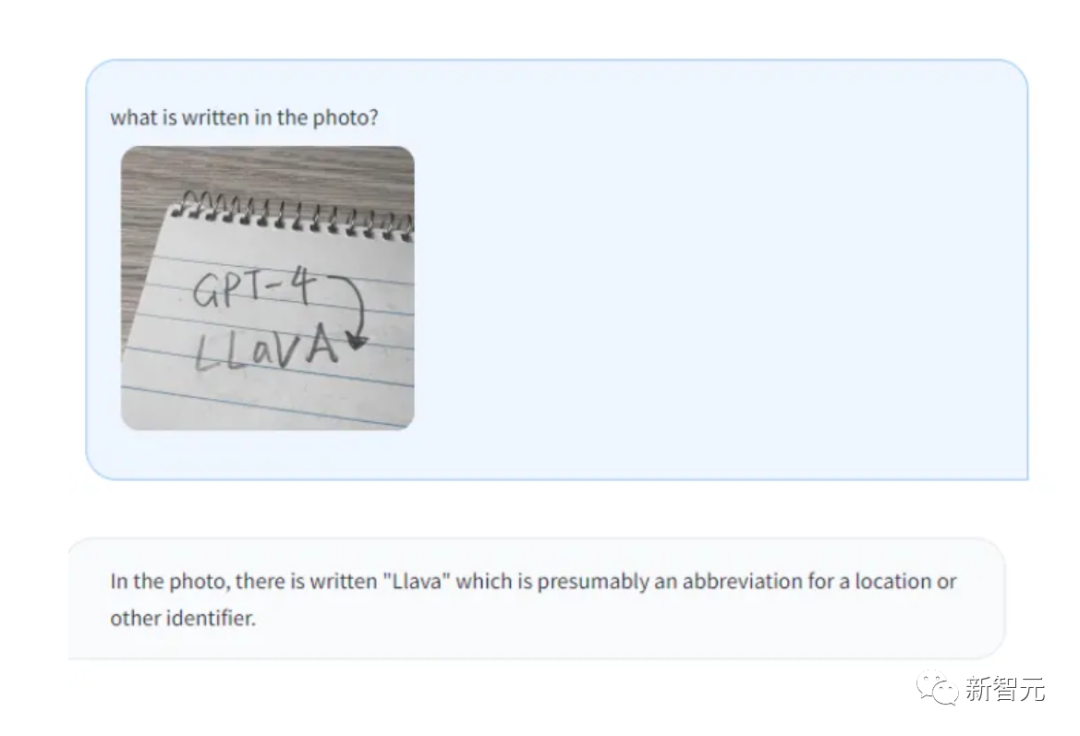 Picture
Picture
CogAgent
CogAgent is an open source visual language model improved on the basis of CogVLM, a researcher from Tsinghua University.
CogAgent-18B has 11 billion visual parameters and 7 billion language parameters.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2312.08914.pdf
CogAgent-18B achieves state-of-the-art general performance on 9 classic cross-modal benchmarks (including VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet and POPE) .
It significantly outperforms existing models on graphical user interface manipulation datasets such as AITW and Mind2Web.
In addition to all the existing functions of CogVLM (visualized multi-turn dialogue, visual grounding), CogAgent.NET also provides more functions:
1. Support higher resolution visual input and dialogue answering questions. Supports ultra-high resolution image input of 1120x1120.
2. Have the ability to visualize the agent, and be able to return the plan, next action and specific operation with coordinates for any given task on any graphical user interface screenshot.
3. The GUI-related question answering function has been enhanced to enable it to handle issues related to screenshots of any GUI such as web pages, PC applications, mobile applications, etc.
4. By improving pre-training and fine-tuning, the capabilities of OCR-related tasks are enhanced.
Graphical User Interface Agent (GUI Agent)
Using CogAgent, it can help us find the best papers of CVPR23 step by step.
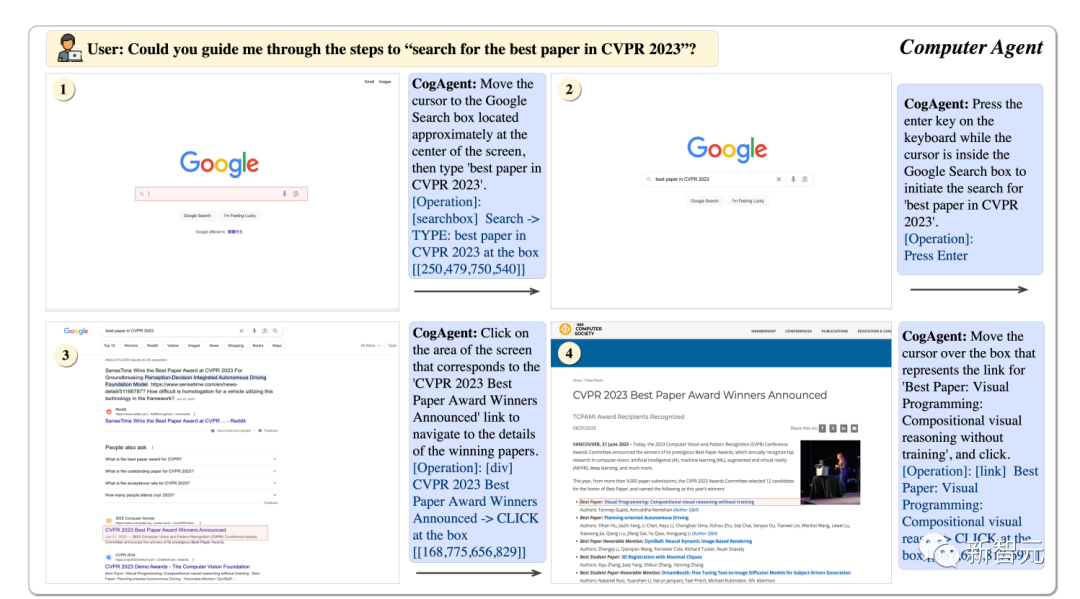 Picture
Picture
can help us adjust the phone display to bright mode.
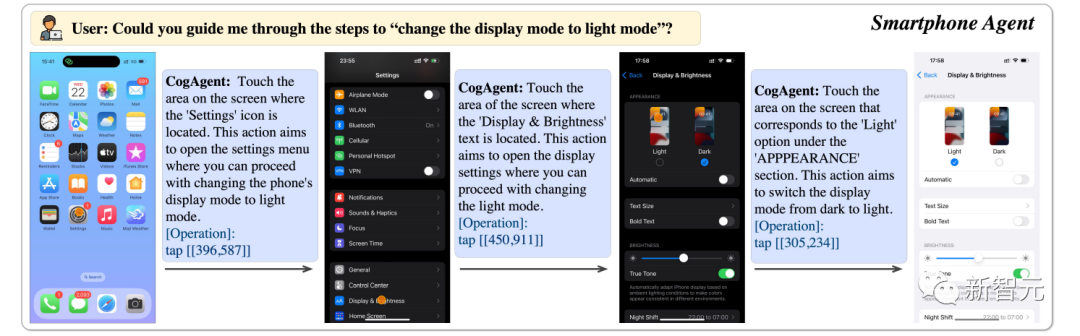 Picture
Picture
CogAgent can analyze how many likes this tweet has and why it is so popular, and even reply with a "Brilliant" , it can all operate.
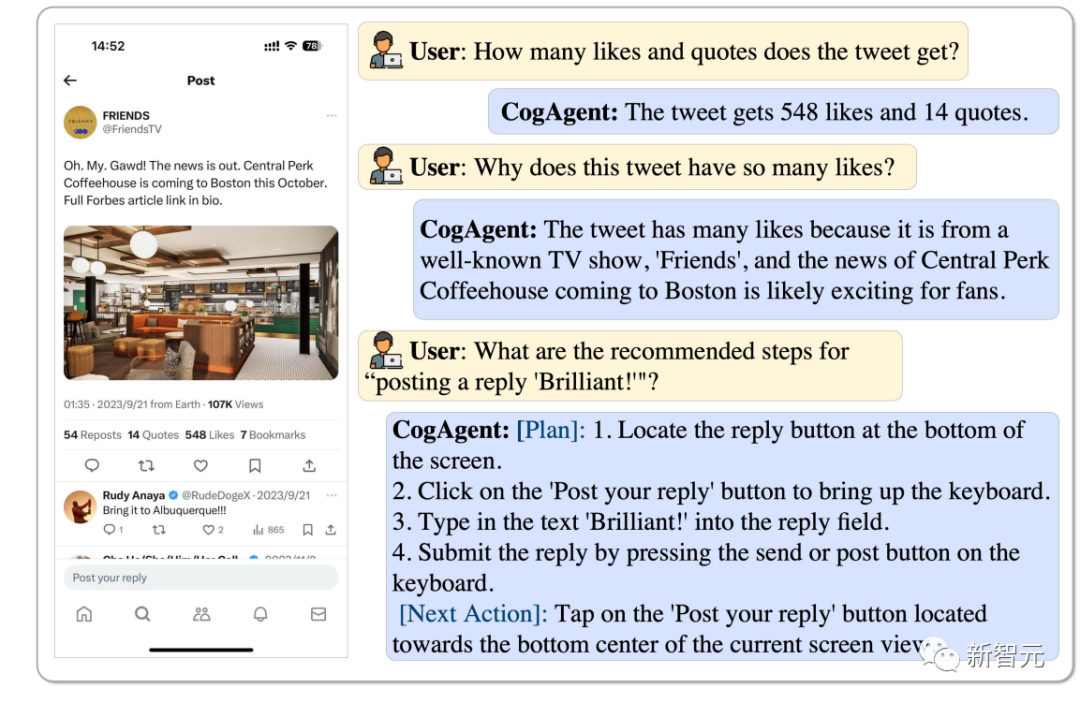 Picture
Picture
How to choose the fastest route from the University of Florida to Hollywood? If you start at 8am, how do you estimate how long it will take? CogAgent can answer all.
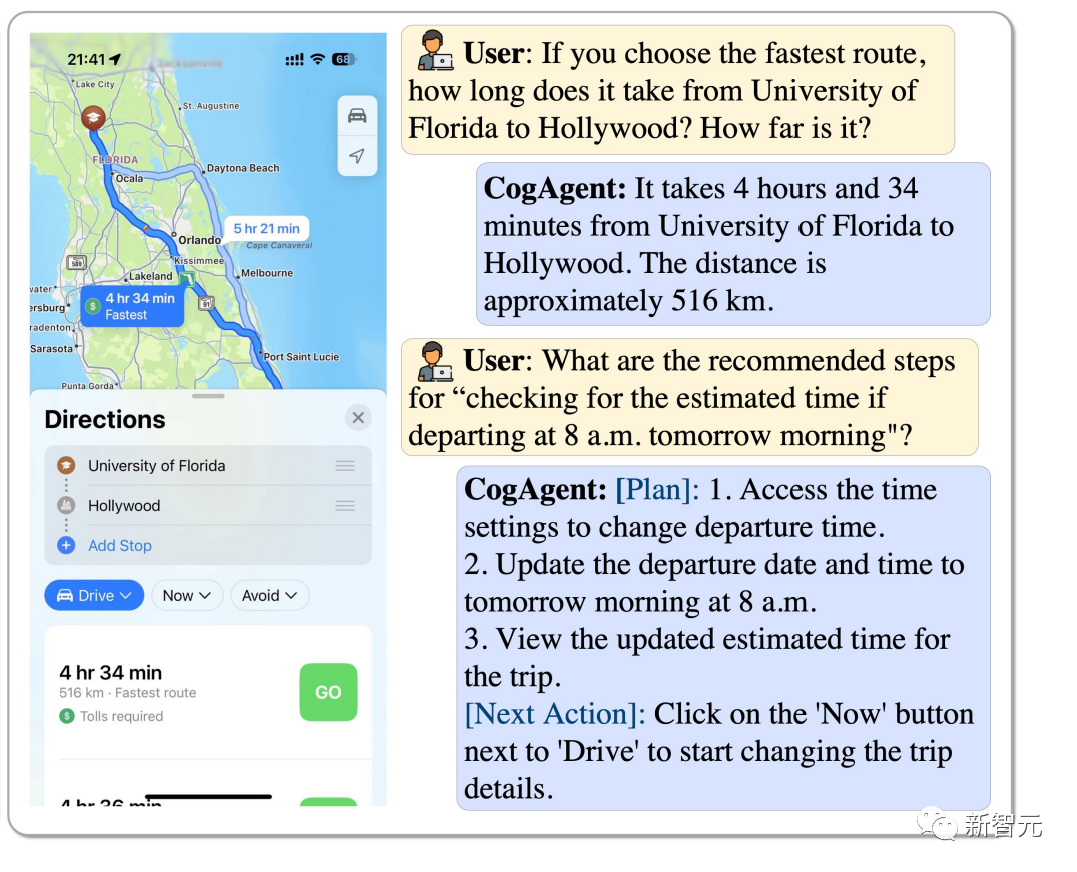 Picture
Picture
You can set a specific subject and let CogAgent send emails to the specified mailbox.
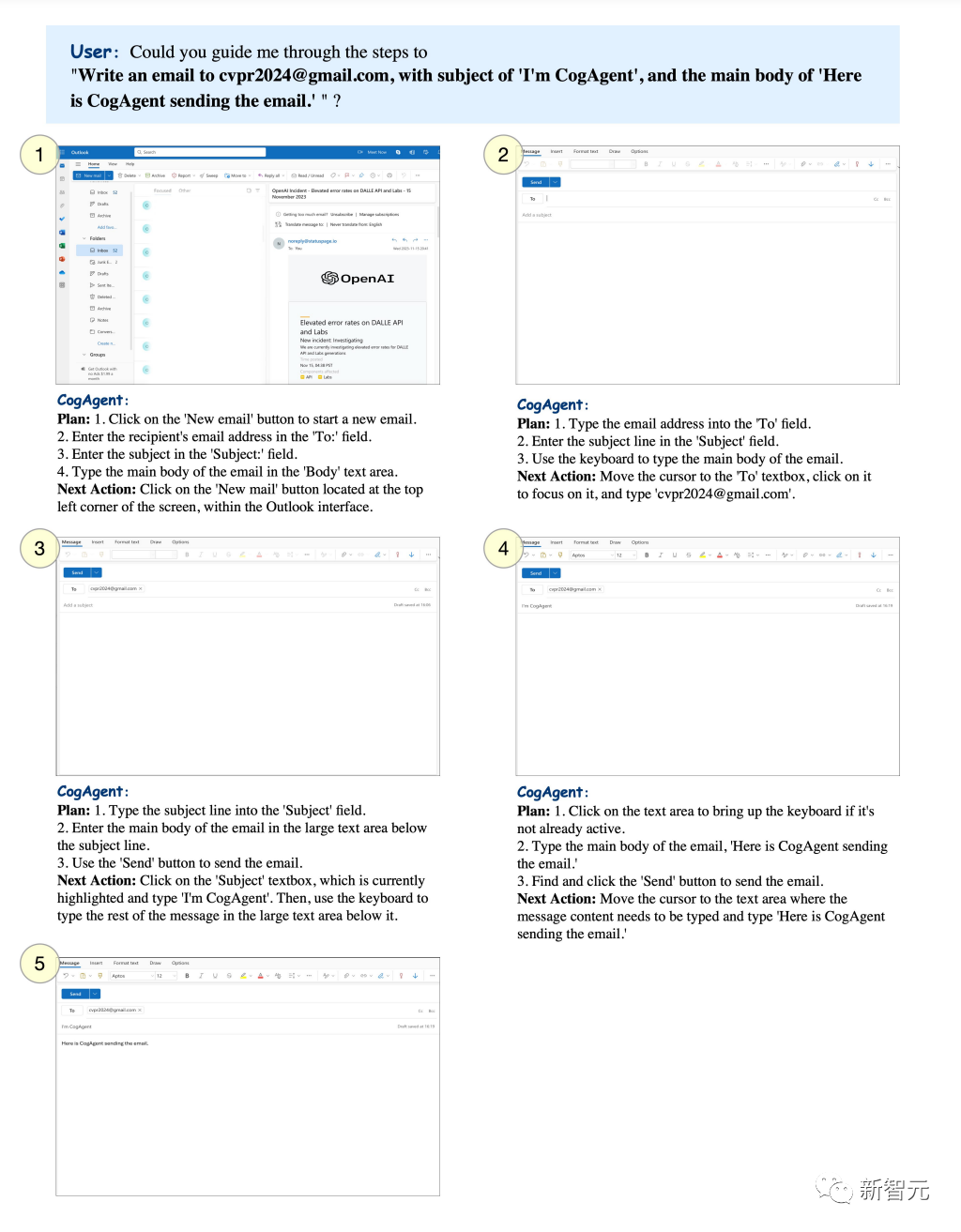 Picture
Picture
If you want to listen to the song "You raise me up", CogAgent can list the steps step by step.
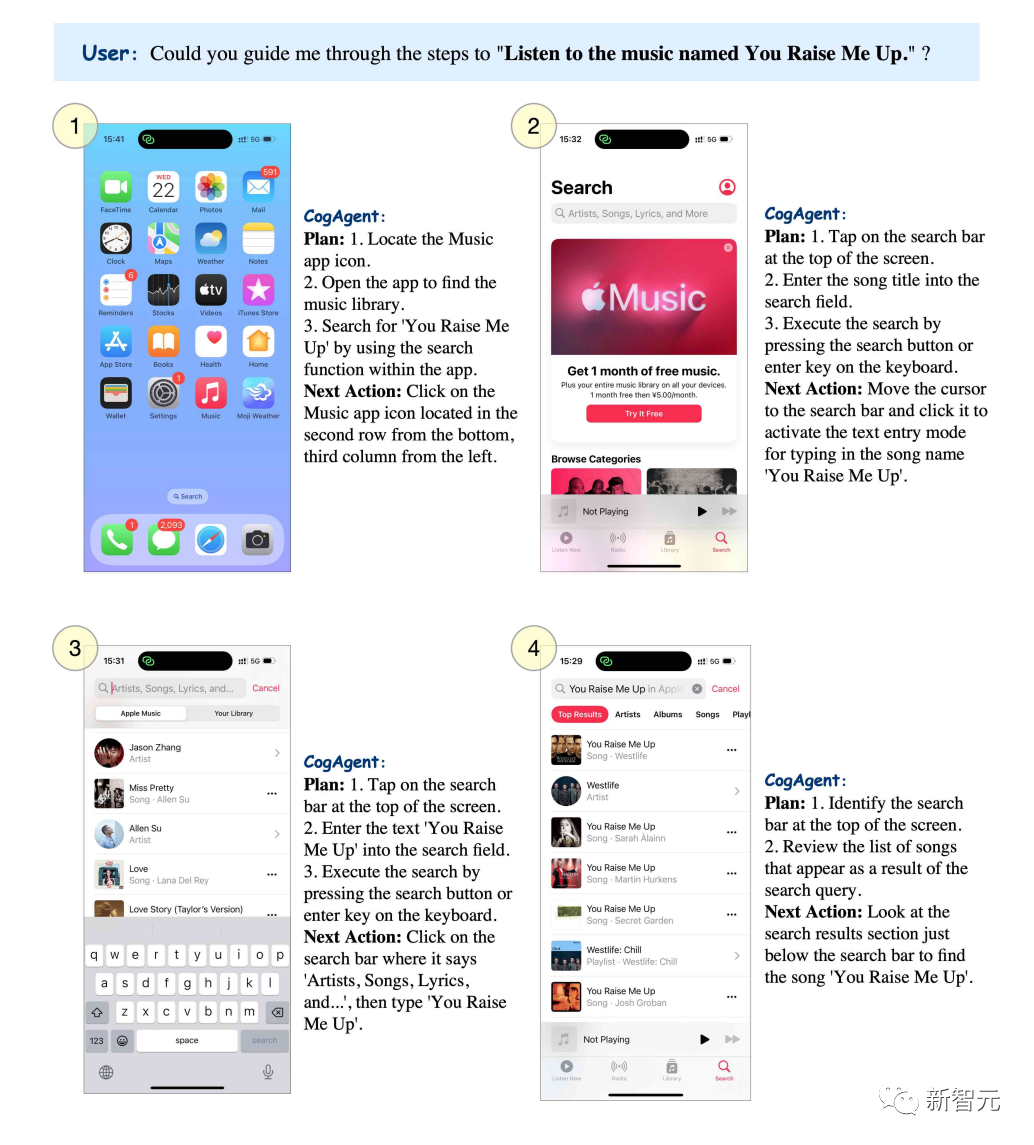 Picture
Picture
CogAgent can accurately describe the scenes in "Genshin Impact" and can also guide you on how to get to the teleportation point.
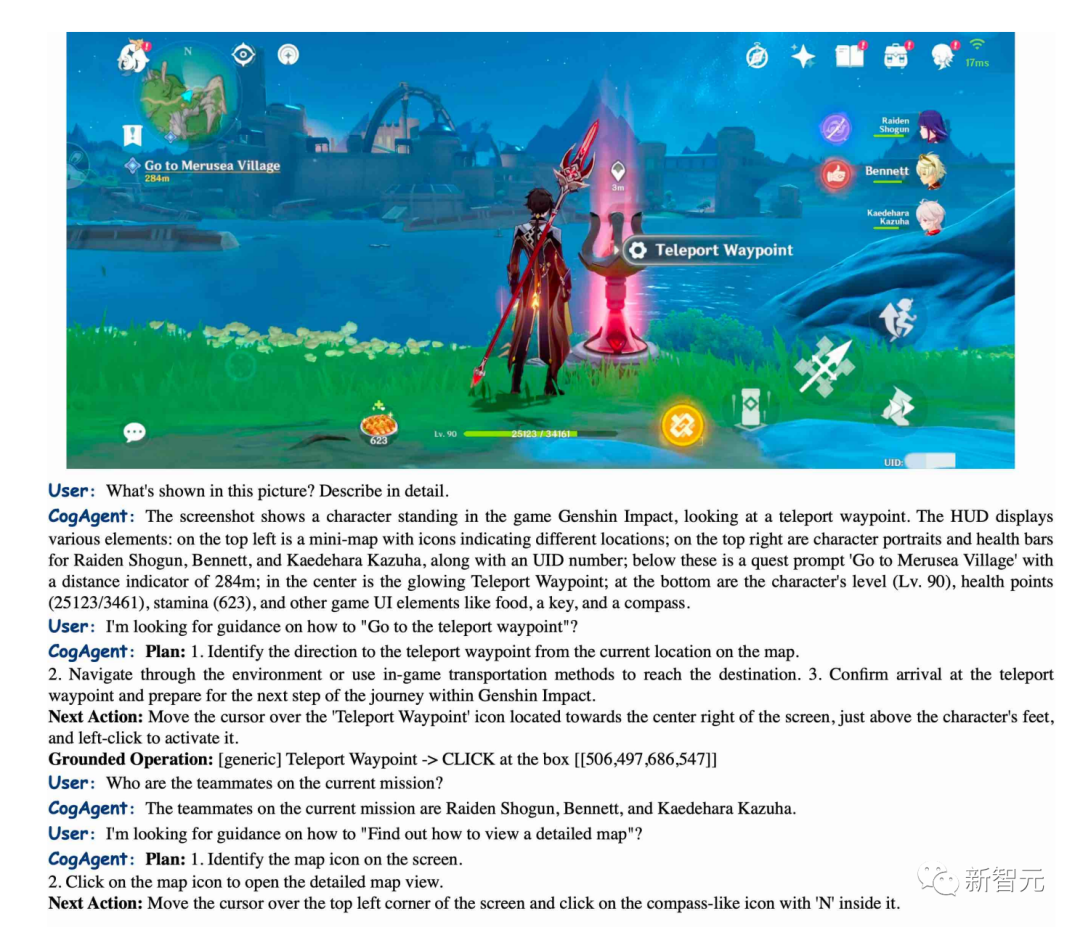 Picture
Picture
BakLLaVA
BakLLaVA1 is a Mistral 7B base model enhanced with LLaVA 1.5 architecture.
In the first release, the Mistral 7B base model outperformed the Llama 2 13B in multiple benchmarks.
In their repo, you can run BakLLaVA-1. The page is constantly being updated to facilitate fine-tuning and reasoning. (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1 is completely open source, but was trained on some data, including LLaVA’s corpus, and is therefore not allowed for commercial use.
BakLLaVA 2 uses a larger data set and an updated architecture, surpassing the current LLaVa method. BakLLaVA gets rid of the limitations of BakLLaVA-1 and can be commercially used.
Reference:
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
The above is the detailed content of Tsinghua University and Zhejiang University lead the explosion of open source visual models, and GPT-4V, LLaVA, CogAgent and other platforms bring revolutionary changes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
Audiences familiar with "Westworld" know that this show is set in a huge high-tech adult theme park in the future world. The robots have similar behavioral capabilities to humans, and can remember what they see and hear, and repeat the core storyline. Every day, these robots will be reset and returned to their initial state. After the release of the Stanford paper "Generative Agents: Interactive Simulacra of Human Behavior", this scenario is no longer limited to movies and TV series. AI has successfully reproduced this scene in Smallville's "Virtual Town" 》Overview map paper address: https://arxiv.org/pdf/2304.03442v1.pdf
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
