How much does Google’s Gemini weigh? How does it compare to OpenAI’s GPT model? This CMU paper has clear measurement results
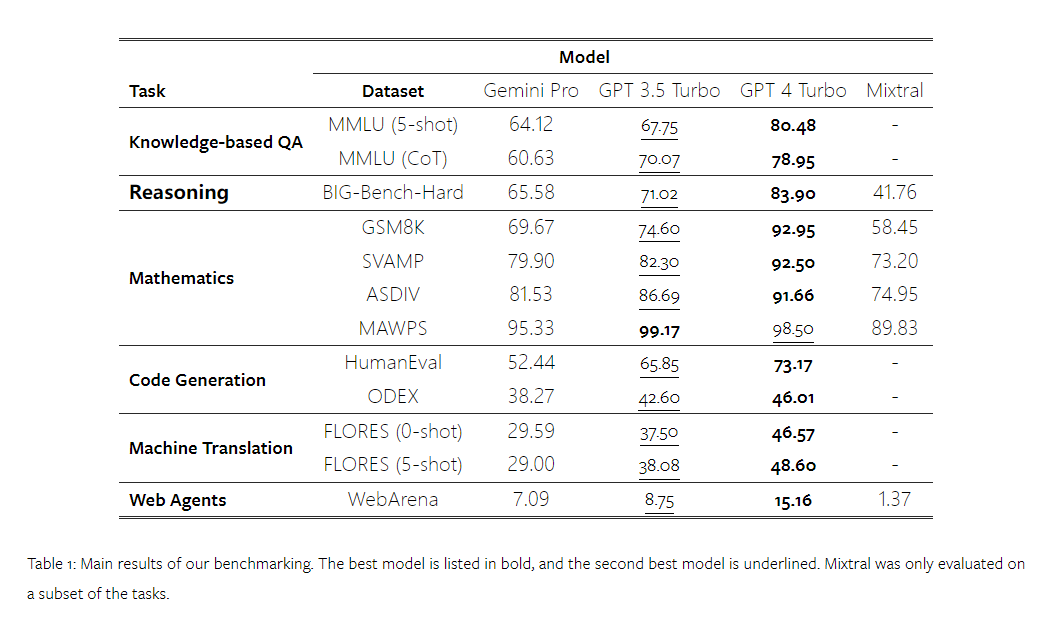
Some time ago, Google released a competing product to the OpenAI GPT model - Gemini. This big model comes in three versions – Ultra (the most capable), Pro and Nano. Test results published by the research team show that the Ultra version outperforms GPT4 in many tasks, while the Pro version is on par with GPT-3.5. Although these comparative results are of great significance to large-scale language model research, the exact evaluation details and model predictions have not yet been made public, which limits the replication and reproducibility of the test results. detection, it is difficult to further analyze its hidden details. In order to understand the true strength of Gemini, researchers from Carnegie Mellon University and BerriAI conducted an in-depth exploration of the model’s language understanding and generation capabilities. They tested the text understanding and generation capabilities of Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral on ten data sets. Specifically, they tested the model's ability to answer knowledge-based questions on MMLU, the model's reasoning ability on BigBenchHard, the model's ability to answer mathematical questions in data sets such as GSM8K, and the model's ability to answer mathematical questions in data sets such as FLORES. The translation ability of the model; the code generation ability of the model was tested in data sets such as HumanEval; the model's ability as an agent that follows instructions was tested in WebArena. Table 1 below shows the main results of the comparison. Overall, as of the publication date of the paper, Gemini Pro is close to OpenAI GPT 3.5 Turbo in accuracy across all tasks, but still slightly inferior. In addition, they also found that Gemini and GPT performed better than the open source competing model Mixtral. In the paper, the author provides an in-depth description and analysis of each task. All results and reproducible code can be found at: https://github.com/neulab/gemini-benchmarkPaper link: https://arxiv.org/ pdf/2312.11444.pdf##The author chose Gemini Pro, GPT Four models, 3.5 Turbo, GPT 4 Turbo, and Mixtral, were used as test objects.
Due to differences in experimental settings during evaluation in previous studies, in order to ensure a fair test, the author re-ran the experiment using exactly the same prompt words and evaluation protocol. In most assessments, they used prompt words and rubrics from a standard repository. These test resources come from the data set that comes with the model release and the evaluation tool Eleuther and so on. Among them, prompt words usually include query, input, a small number of examples, thinking chain reasoning, etc. In some special assessments, the authors found that minor adjustments to standard practices were necessary. Adjusting the bias has been performed in the corresponding code repository, please refer to the original paper.
The goals of this research are as follows:
#1. Through reproducible code and fully transparent results , providing a third-party objective comparison of the capabilities of OpenAI GPT and Google Gemini models.
2. Study the evaluation results in depth and analyze in which fields the two models perform more prominently.
The author obtained the data from MMLU A centralized selection of 57 knowledge-based multiple-choice question and answer tasks covering various topics such as STEM, humanities and social sciences. MMLU has a total of 14,042 test samples and has been widely used to provide an overall assessment of the knowledge capabilities of large language models.
The author compared and analyzed the overall performance of the four test subjects on MMLU (as shown in the figure below), sub-task performance, and the impact of output length on performance.
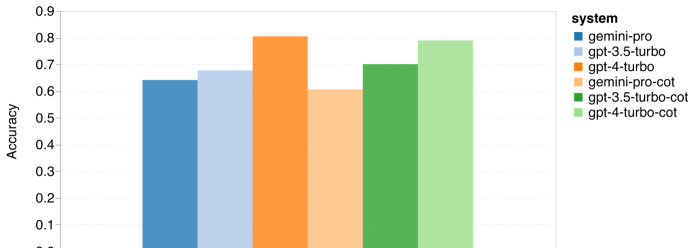
Figure 1: Overall accuracy of each model on MMLU using 5 sample prompts and thought chain prompts. As you can see from the figure, the accuracy of Gemini Pro is lower than GPT 3.5 Turbo, and much lower than GPT 4 Turbo.When using the thought chain prompt, there is little difference in the performance of each model. The authors speculate that this is due to the fact that MMLU primarily captures knowledge-based question and answer tasks, which may not benefit significantly from stronger reasoning-oriented prompts.
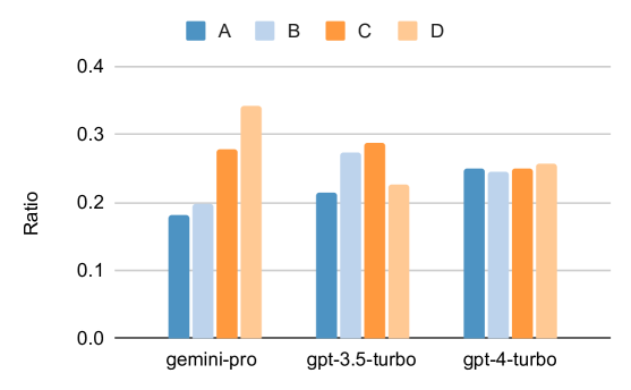
It is worth noting that all questions in MMLU are multiple choice questions with four potential answers A to D arranged in order. The graph below shows the proportion of each answer option selected by each model. You can see from the figure that Gemini's answer distribution is very skewed towards choosing the last option D. This contrasts with the more balanced results given by versions of GPT. This may indicate that Gemini did not receive the extensive instruction adjustments associated with multiple-choice questions, resulting in a bias in the model's answer ranking. Figure 2: Proportion of answers to multiple-choice questions predicted by the tested model.
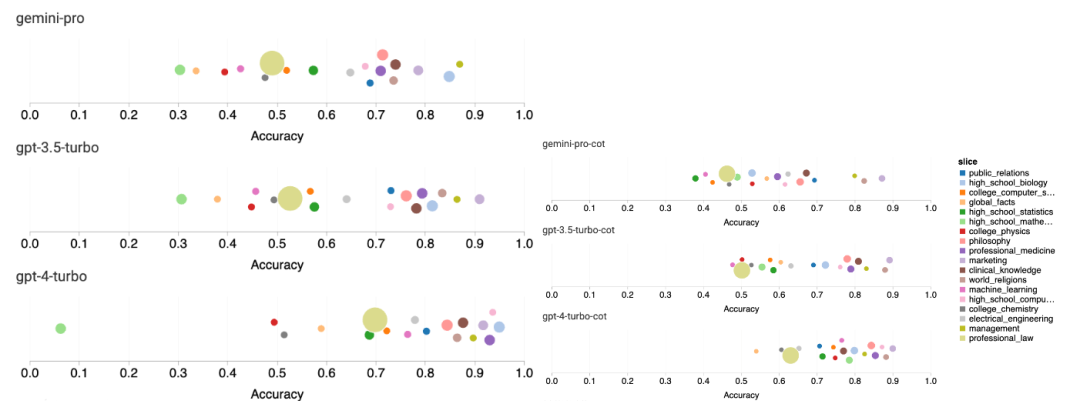
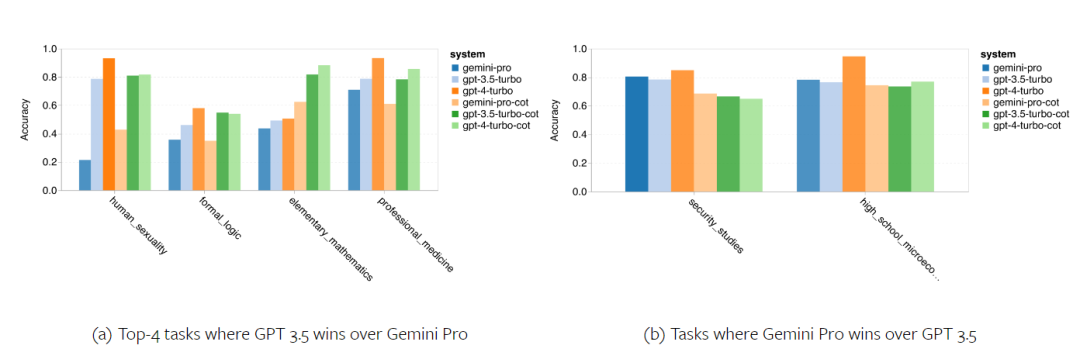
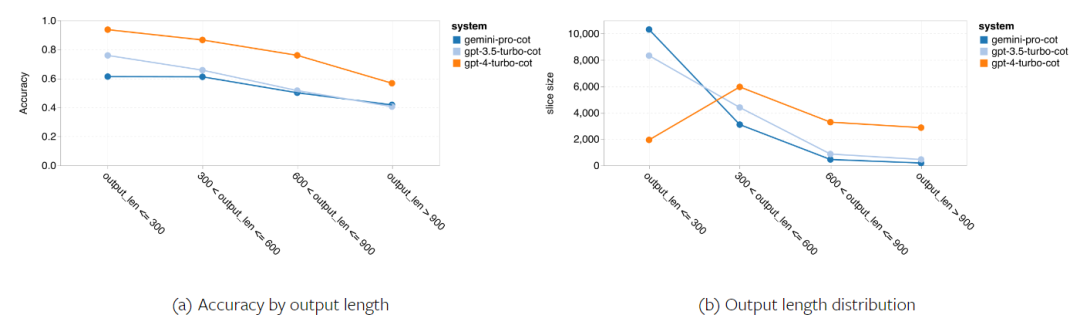
The following figure shows the performance of the tested model on the sub-tasks of the MMLU test set. Gemini Pro performs poorly on most tasks compared to GPT 3.5. Thought chain prompts reduce variance between subtasks. Figure 3: Accuracy of the tested model on each subtask. The author takes a deep dive into the strengths and weaknesses of Gemini Pro. As can be observed in Figure 4, Gemini Pro lags behind GPT 3.5 in the Human Gender (Social Sciences), Formal Logic (Humanities), Elementary Mathematics (STEM), and Professional Medicine (Professional Fields) tasks. The lead is also slim in the two tasks the Gemini Pro is better at. Figure 4: Advantages of Gemini Pro and GPT 3.5 on MMLU tasks. The Gemini Pro's poor performance on specific tasks can be attributed to two reasons. First, there are situations where Gemini cannot return an answer. In most MMLU subtasks, the API response rate exceeds 95%, but the corresponding rates are significantly lower in the two tasks of morality (response rate 85%) and human gender (response rate 28%). This suggests that Gemini's lower performance on some tasks may be due to input content filters. Second, the Gemini Pro performs slightly worse at the basic mathematical reasoning required to solve formal logic and basic math tasks. The author also analyzed how the output length in the thought chain prompt affects model performance, as shown in Figure 5. In general, more powerful models tend to perform more complex reasoning and therefore output longer answers. The Gemini Pro has a noteworthy advantage over its "opponents": its accuracy is less affected by output length. Gemini Pro even outperforms GPT 3.5 when the output length exceeds 900. However, compared to GPT 4 Turbo, Gemini Pro and GPT 3.5 Turbo rarely output long inference chains. Figure 5: Output length analysis of the tested model on MMLU.
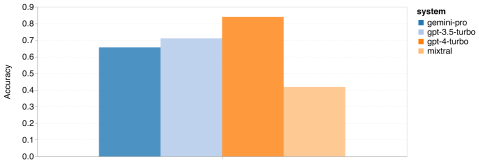
General-purpose Reasoning In the BIG-Bench Hard test set, the author evaluates the general reasoning ability of the subjects. BIG-Bench Hard contains 27 different reasoning tasks such as arithmetic, symbolic and multilingual reasoning, factual knowledge understanding, and more. Most tasks consist of 250 question-answer pairs, with a few tasks having slightly fewer questions. Figure 6 shows the overall accuracy of the tested model. It can be seen that the accuracy of Gemini Pro is slightly lower than GPT 3.5 Turbo and much lower than GPT 4 Turbo. In comparison, the accuracy of the Mixtral model is much lower. Figure 6: Overall accuracy of the tested model on BIG-Bench-Hard.
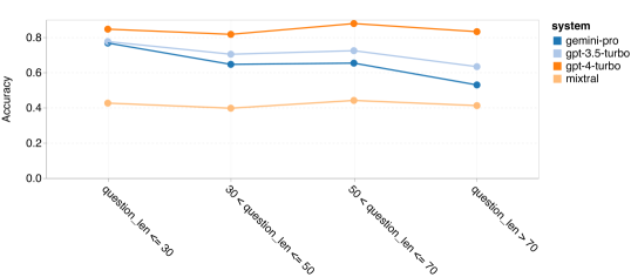
The author goes into more depth about why Gemini general reasoning performs poorly overall. First, they examined accuracy by question length. As shown in Figure 7, Gemini Pro performs poorly on longer, more complex problems. And the GPT model, especially GPT 4 Turbo, even in very long problems, the regression of GPT 4 Turbo is very small. This shows that it is robust and capable of understanding longer and more complex questions and queries. The robustness of GPT 3.5 Turbo is average. Mixtral performed stably in terms of question length, but had lower overall accuracy. Figure 7: Accuracy of the tested model on BIG-Bench-Hard by question length.
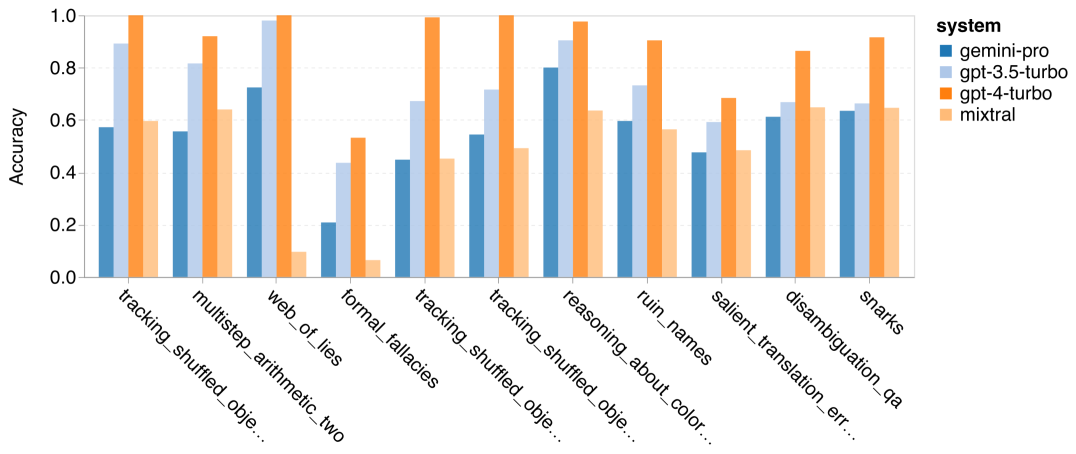
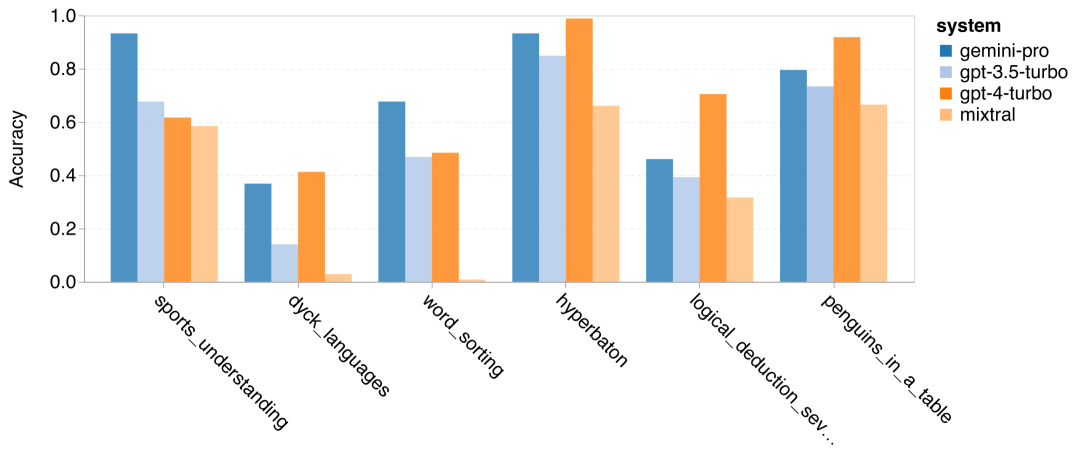
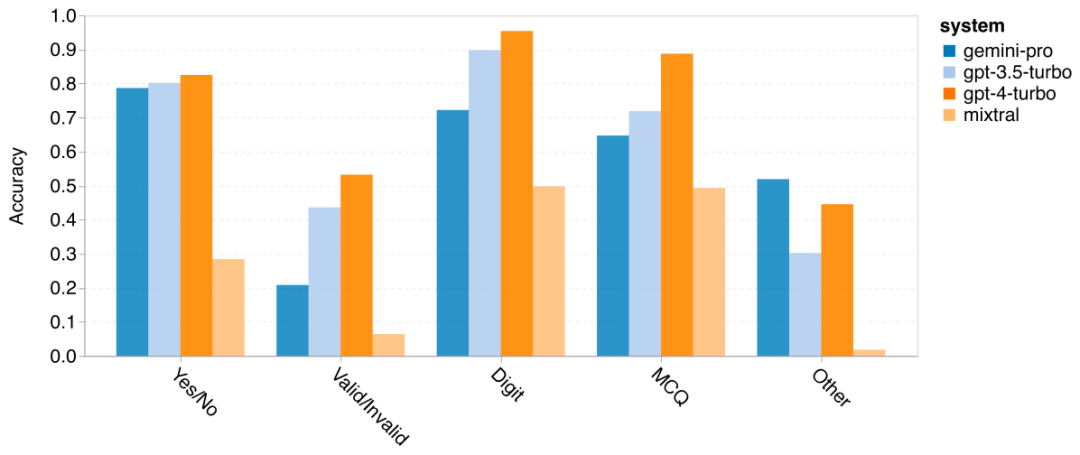
The author analyzed whether there are differences in accuracy of the tested models in specific BIG-Bench-Hard tasks. Figure 8 shows which tasks GPT 3.5 Turbo performs better than Gemini Pro. In the task of "tracking the position of transformed objects", Gemini Pro performed particularly poorly. These tasks involve people exchanging items and tracking who owns something, but Gemini Pro often struggled to keep the order right. Figure 8: GPT 3.5 Turbo outperforms Gemini Pro’s BIG-Bench-Hard subtask. Gemini Pro is inferior to Mixtral in tasks such as arithmetic problems that require multi-step solutions and finding errors in translations. There are also tasks where Gemini Pro is better than GPT 3.5 Turbo. Figure 9 shows the six tasks where Gemini Pro leads GPT 3.5 Turbo by the largest margin. The tasks are heterogeneous and include those requiring world knowledge (sports_understanding), manipulating symbol stacks (dyck_languages), sorting words alphabetically (word_sorting), and parsing tables (penguins_in_a_table). Figure 9: Gemini Pro outperforms GPT 3.5 on the BIG-Bench-Hard subtask. The author further analyzed the robustness of the tested model in different answer types, as shown in Figure 10. Gemini Pro performed worst in the "Valid/Invalid" answer type, which belongs to the task formal_fallacies. Interestingly, 68.4% of the questions in this task had no response. However, in other answer types (consisting of word_sorting and dyck_language tasks), Gemini Pro outperforms all GPT models and Mixtral. That is, Gemini Pro is particularly good at rearranging words and generating symbols in the correct order. Additionally, for MCQ answers, 4.39% of the questions were blocked from responding by Gemini Pro. The GPT models excel in this area, and the Gemini Pro struggles to compete with them. Figure 10: Accuracy of tested models by answer type on BIG-Bench-Hard.
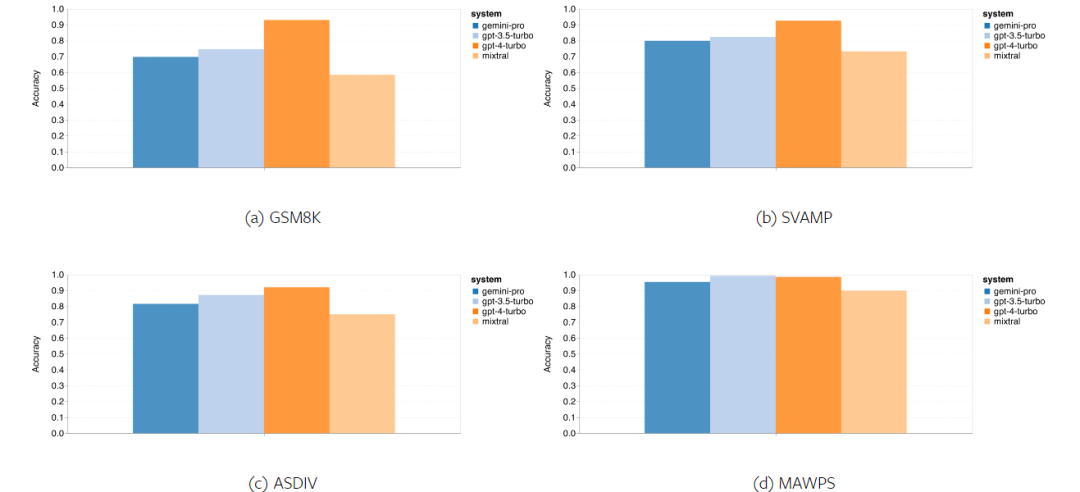
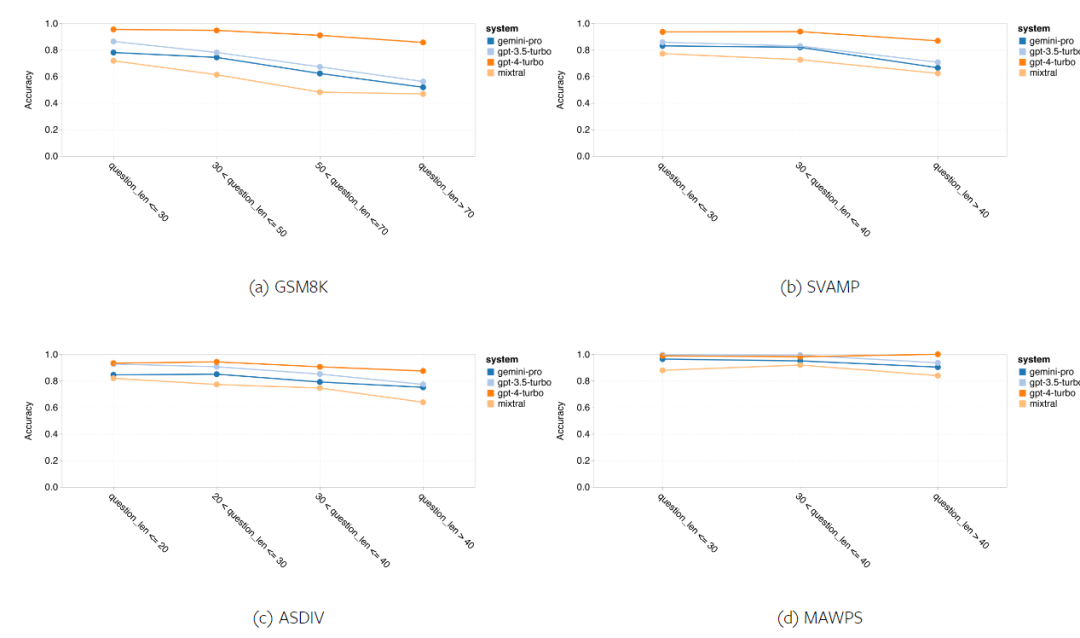
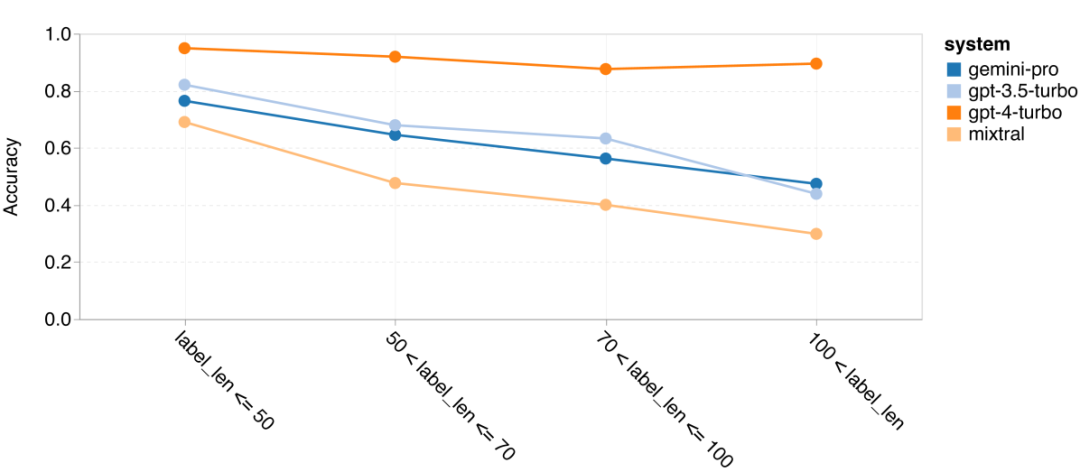
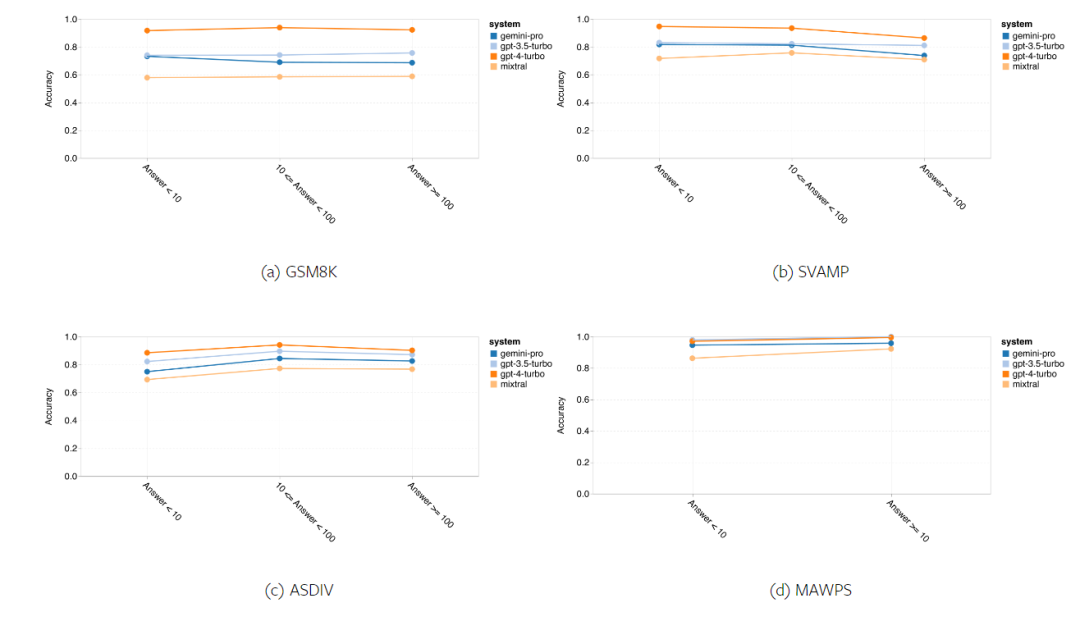
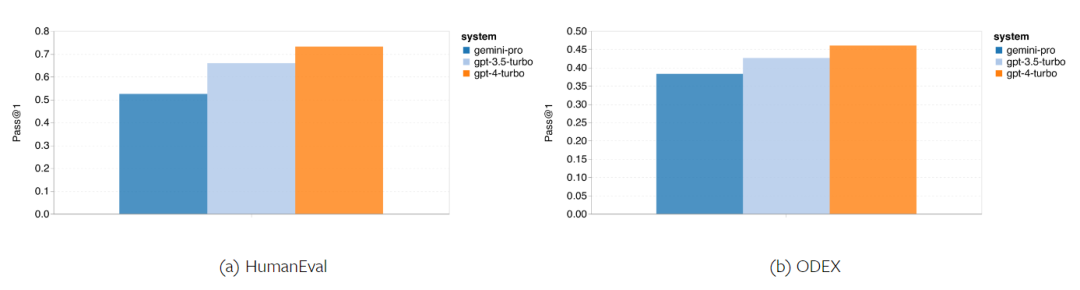
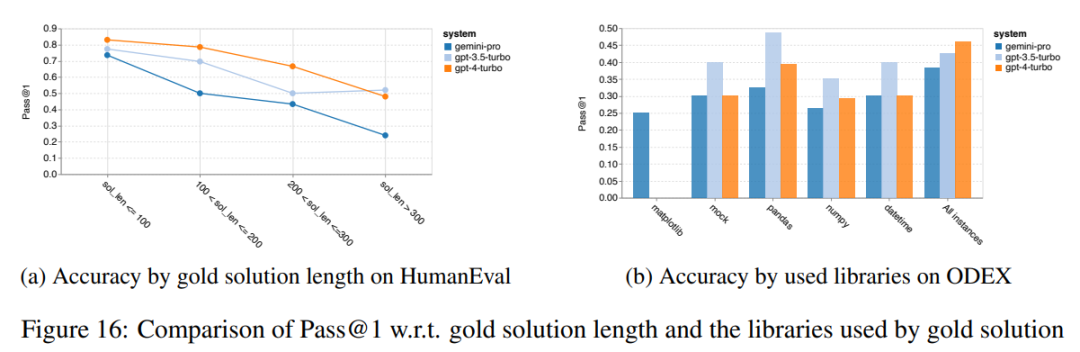
In short, no model seems to be leading the way on a specific task. Therefore, when performing general-purpose inference tasks, it is worth trying both Gemini and GPT models before deciding which model to use. In order to evaluate the mathematical reasoning ability of the tested model, the author chooses Four math problem benchmarks were created: (1) GSM8K: Primary school math benchmark; (2) SVAMP: Generated by changing word order questions to check robust reasoning skills; (3) ASDIV: with different language modes and question types; (4) MAWPS: Contains arithmetic and algebraic word problems. The author compared the accuracy of Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo and Mixtral on four mathematical problem test sets, examining their overall performance, differences Performance under problem complexity and performance under different depths of thinking chains. Figure 11 presents the overall results. In tasks including GSM8K, SVAMP and ASDIV with different language modes, the accuracy of Gemini Pro is slightly lower than that of GPT 3.5 Turbo and much lower. on GPT 4 Turbo. For the tasks in MAWPS, Gemini Pro is still slightly inferior to the GPT model, although all tested models achieve over 90% accuracy. In this task, GPT 3.5 Turbo narrowly outperforms GPT 4 Turbo. In comparison, the accuracy of the Mixtral model is much lower than the other models. Figure 11: Overall accuracy of the tested model in four mathematical reasoning test set tasks. The robustness of each model to problem length is demonstrated in Figure 12. Similar to the inference tasks in BIG-Bench Hard, the model under test showed reduced accuracy when answering longer questions.GPT 3.5 Turbo performs better than Gemini Pro on shorter questions, but regresses faster, and Gemini Pro is similar to GPT 3.5 Turbo in accuracy on longer questions, but still lags slightly behind. # Figure 12: The accuracy of the tested model in generating answers for different question lengths in four mathematical reasoning test set tasks. Additionally, the authors observed differences in the accuracy of the tested models when the answer required a longer chain of thought. As shown in Figure 13, GPT 4 Turbo is very robust even when using long inference chains, while GPT 3.5 Turbo, Gemini Pro, and Mixtral show limitations when the COT length increases. Through analysis, the authors also found that Gemini Pro outperformed GPT 3.5 Turbo in complex examples with COT lengths over 100, but performed poorly in shorter examples. Figure 13: Accuracy of each model on GSM8K under different thinking chain lengths. Figure 14 shows the accuracy of the tested model in generating answers for different numbers of digits. The authors created three "buckets" based on whether the answer contained 1, 2, or 3 or more digits (except for the MAWPS task, which had no answers with more than two digits). As shown in the figure, GPT 3.5 Turbo appears to be more robust to multi-digit math problems, while Gemini Pro degrades on problems with higher numbers. Figure 14: Accuracy of each model in four mathematical reasoning test set tasks when the number of answer digits is different. In this section, the author uses Two code generation datasets—HumanEval and ODEX—were used to examine the coding capabilities of the model. The former tests a model's basic code understanding of a limited set of functions in the Python standard library, and the latter tests a model's ability to use a broader set of libraries across the Python ecosystem. The input for both problems is task instructions written in English (usually with test cases). These questions are used to evaluate the model's language understanding, algorithm understanding, and elementary mathematics ability. In total, HumanEval has 164 test samples and ODEX has 439 test samples. First of all, from the overall results shown in Figure 15, we can see that Gemini Pro’s Pass@1 scores on both tasks are lower than GPT 3.5 Turbo, also Much lower than GPT 4 Turbo. These results indicate that Gemini's code generation capabilities leave room for improvement. Figure 15: Overall accuracy of each model in the code generation task. Secondly, the author analyzes the relationship between the gold solution length and model performance in Figure 16 (a). The length of the solution can, to a certain extent, indicate the difficulty of the corresponding code generation task. The authors find that Gemini Pro achieves Pass@1 scores comparable to GPT 3.5 when the solution length is below 100 (as in the easier case), but it lags behind significantly when the solution length gets longer. This is an interesting contrast to the results of the previous sections, where the authors found that Gemini Pro was generally robust to longer inputs and outputs in English tasks.  The authors also analyzed the impact of the libraries required for each solution on model performance in Figure 16(b). In most library use cases, such as mocks, pandas, numpy, and datetime, Gemini Pro performs worse than GPT 3.5. However, in matplotlib's use case, it outperforms GPT 3.5 and GPT 4, indicating its greater ability to perform plot visualizations through code. Finally, the author shows several specific failure cases where Gemini Pro performed worse than GPT 3.5 in terms of code generation. First, they noticed that Gemini was slightly inferior at correctly selecting functions and parameters in the Python API.For example, given the following prompt:
The authors also analyzed the impact of the libraries required for each solution on model performance in Figure 16(b). In most library use cases, such as mocks, pandas, numpy, and datetime, Gemini Pro performs worse than GPT 3.5. However, in matplotlib's use case, it outperforms GPT 3.5 and GPT 4, indicating its greater ability to perform plot visualizations through code. Finally, the author shows several specific failure cases where Gemini Pro performed worse than GPT 3.5 in terms of code generation. First, they noticed that Gemini was slightly inferior at correctly selecting functions and parameters in the Python API.For example, given the following prompt: ##Gemini Pro generated the following code, resulting in a type mismatch error:
In contrast, GPT 3.5 Turbo uses the following code, which achieves the desired effect:
In addition, Gemini Pro has a higher error ratio, in this case , the code executed is syntactically correct, but does not correctly match the more complex intent. For example, regarding the following tip:
Gemini Pro has created an implementation that only extracts unique numbers without removing those that appear multiple times.
This set of experiments was evaluated using the FLORES-200 machine translation benchmark. The multilingual capabilities of the model, especially the ability to translate between various language pairs. The authors focus on a different subset of the 20 languages used in Robinson et al.'s (2023) analysis, covering varying levels of resource availability and translation difficulty. The authors evaluated 1012 sentences in the test set for all selected language pairs.
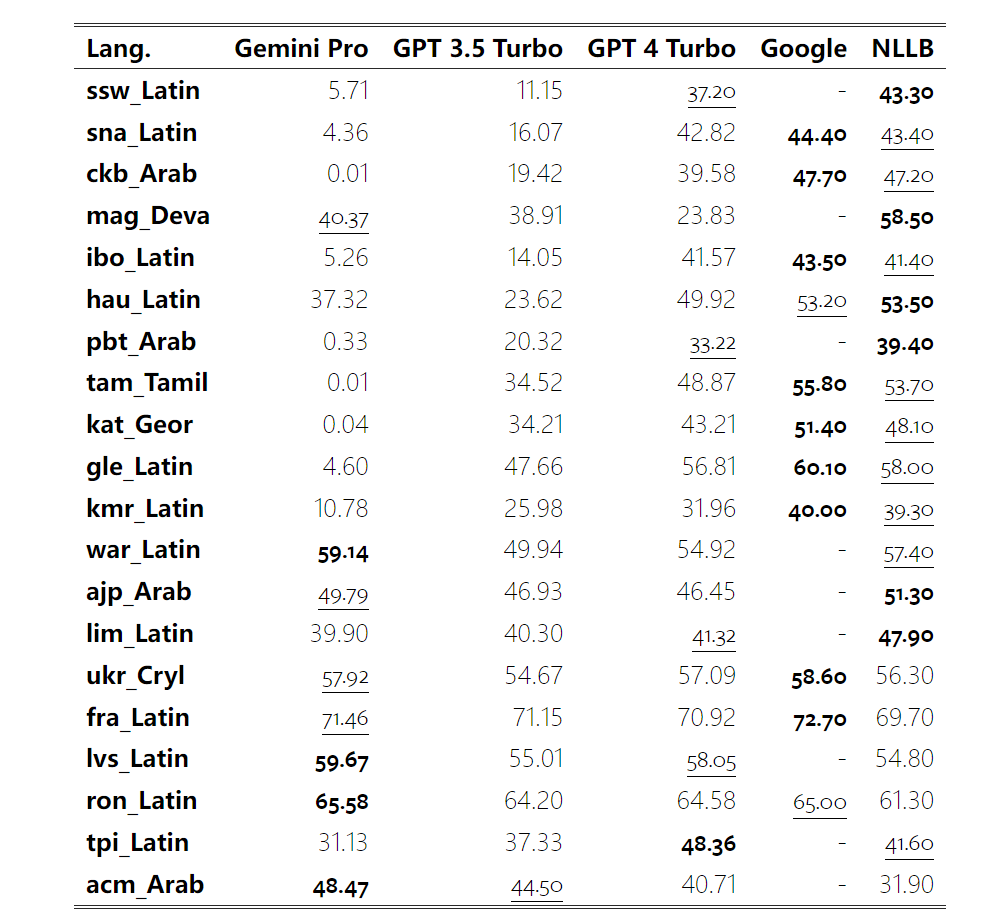
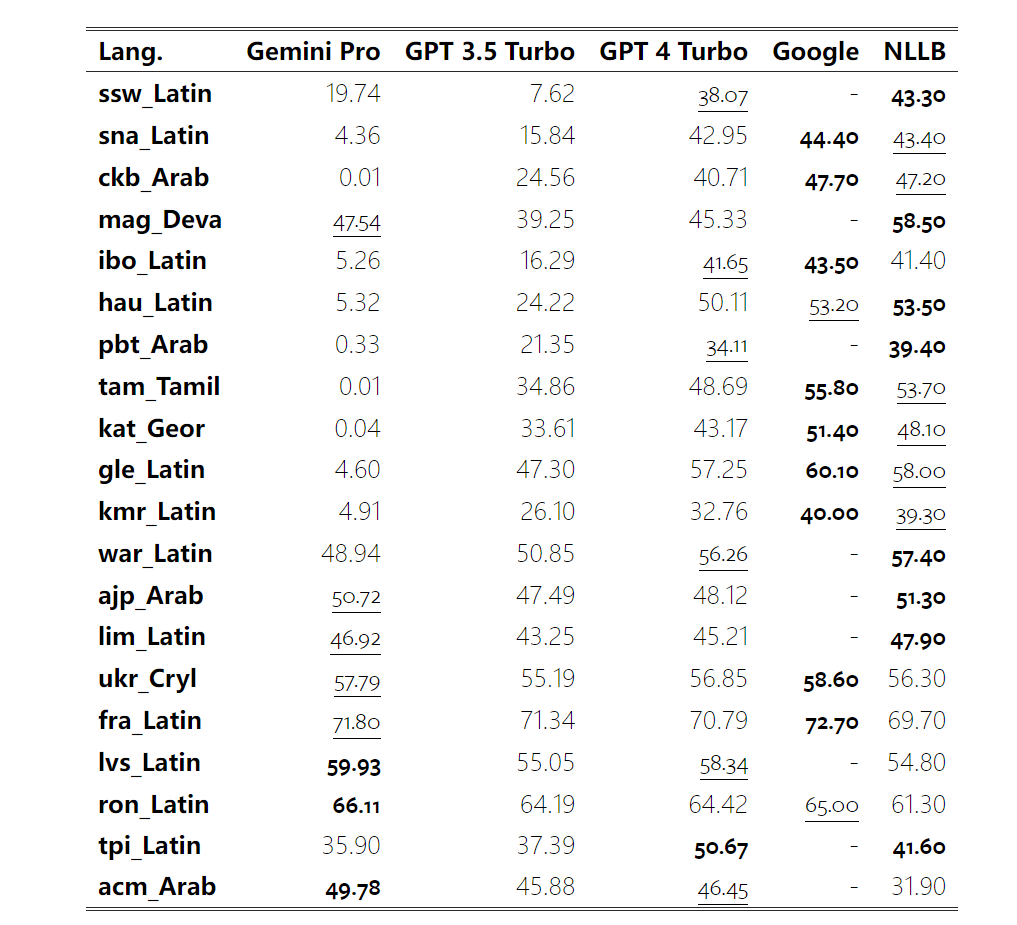
In Tables 4 and 5, the author conducts a comparative analysis of Gemini Pro, GPT 3.5 Turbo, and GPT 4 Turbo with mature systems such as Google Translate. Additionally, they benchmarked NLLB-MoE, a leading open source machine translation model known for its broad language coverage. The results show that Google Translate outperforms the other models overall, performing well on 9 languages, followed by NLLB, which performs well on 6/8 languages under the 0/5-shot setting. General-purpose language models have shown competitive performance but have not yet surpassed specialized machine translation systems in translation into non-English languages.
Table 4: Performance (chRF (%) score) of each model for machine translation across all languages using 0-shot hints. The best score is shown in bold and the next best score is underlined.
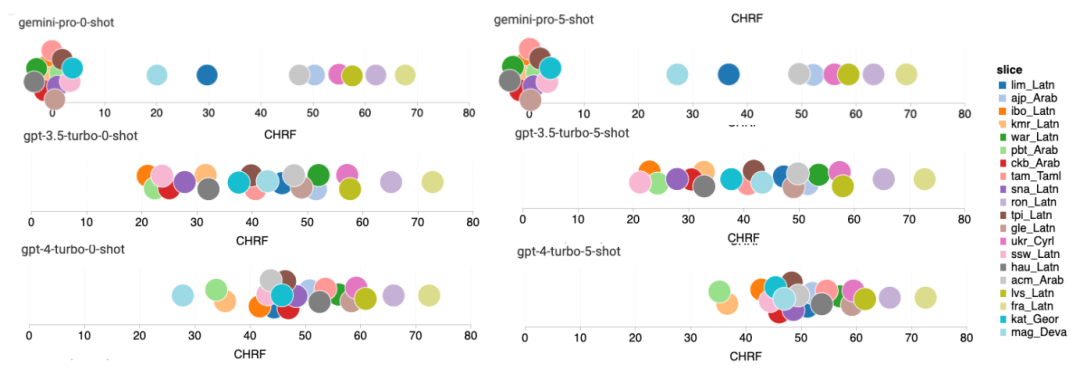
Table 5: Performance of each model in machine translation for all languages using 5-shot prompts (chRF (%) Fraction). The best score is shown in bold and the next best score is underlined. Figure 17 shows the performance comparison of the general language model across different language pairs. GPT 4 Turbo exhibits consistent performance bias with NLLB compared to GPT 3.5 Turbo and Gemini Pro. GPT 4 Turbo also has larger improvements in low-resource languages, while in high-resource languages, the performance of both LLMs is similar. In comparison, Gemini Pro outperformed GPT 3.5 Turbo and GPT 4 Turbo on 8 out of 20 languages, and achieved top performance on 4 languages. However, Gemini Pro showed a strong tendency to block responses in about 10 language pairs.
Figure 17: Machine translation performance (chRF (%) score) by language pair. Figure 18 shows that Gemini Pro has lower performance in these languages because it tends to perform in lower confidence scenarios Block response. If Gemini Pro generates a "Blocked Response" error in a 0-shot or 5-shot configuration, the response is considered "blocked."
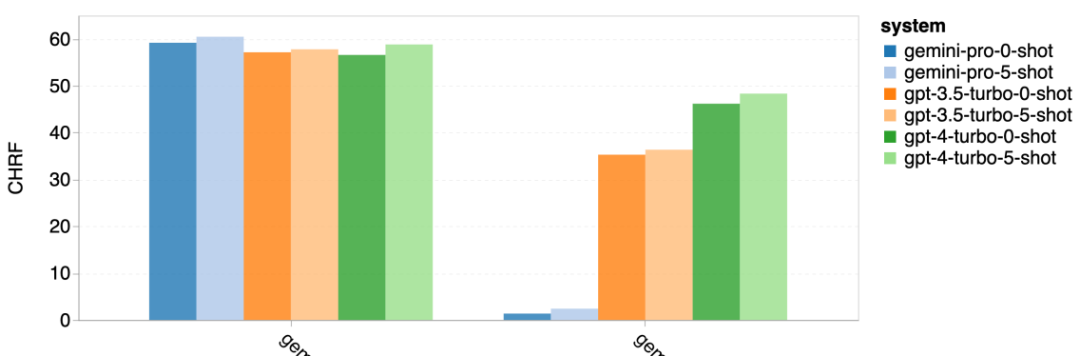
Figure 18: Number of samples blocked by Gemini Pro. #If you look closely at Figure 19, you can see that Gemini Pro is slightly better than GPT 3.5 Turbo and GPT 4 Turbo in the unshielded samples with higher confidence. .Specifically, it outperforms GPT 4 Turbo by 1.6 chrf and 2.6 chrf at 5-shot and 0-shot settings respectively, and outperforms GPT 3.5 Turbo by 2.7 chrf and 2 chrf. However, the authors' preliminary analysis of the performance of GPT 4 Turbo and GPT 3.5 Turbo on these samples shows that translation of these samples is generally more challenging. Gemini Pro performs poorly on these particular samples, notably as the Gemini Pro 0-shot masks responses while the 5-shot does not, and vice versa.
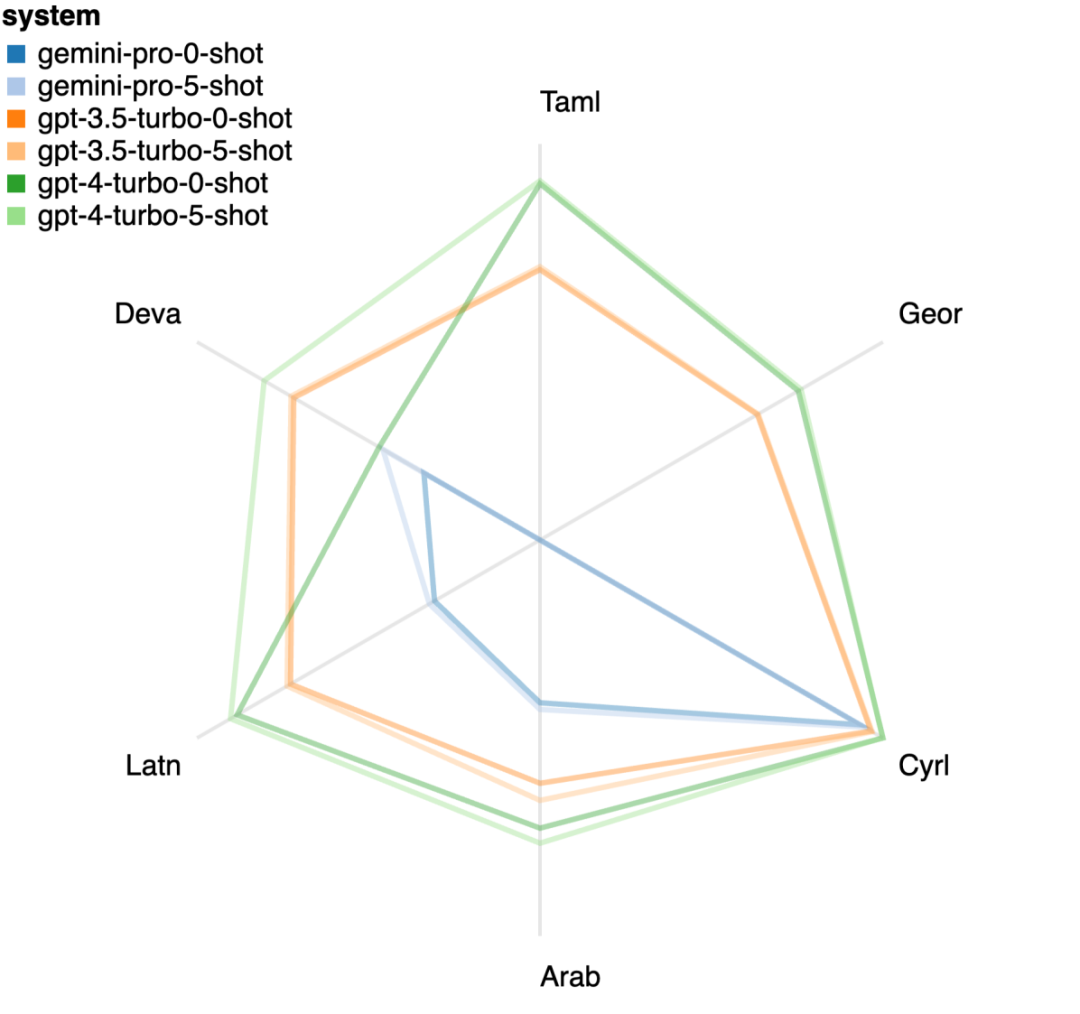
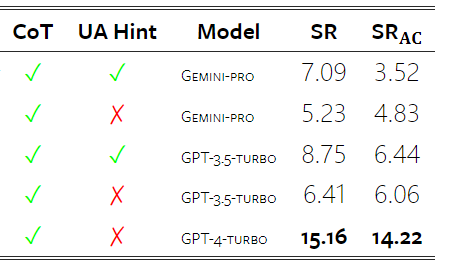
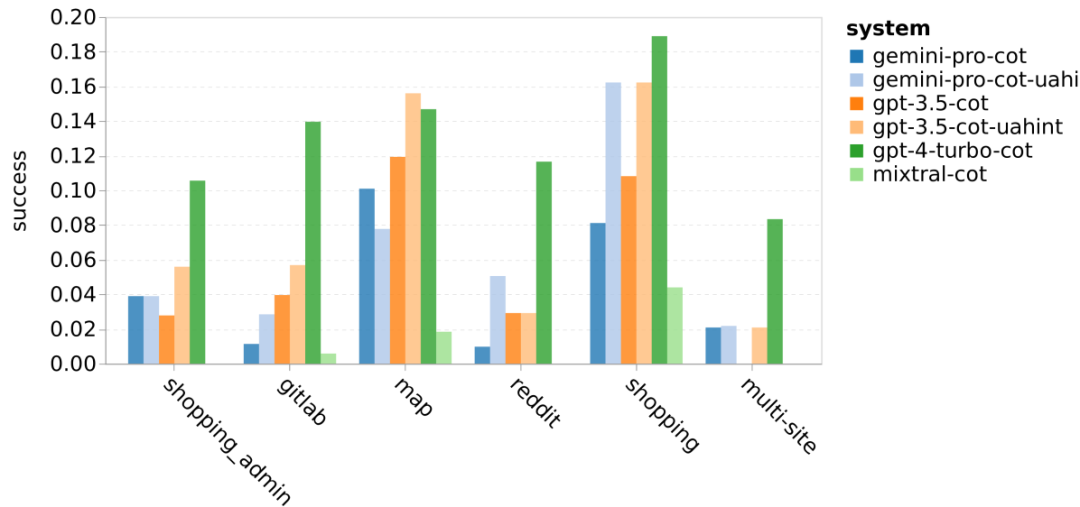
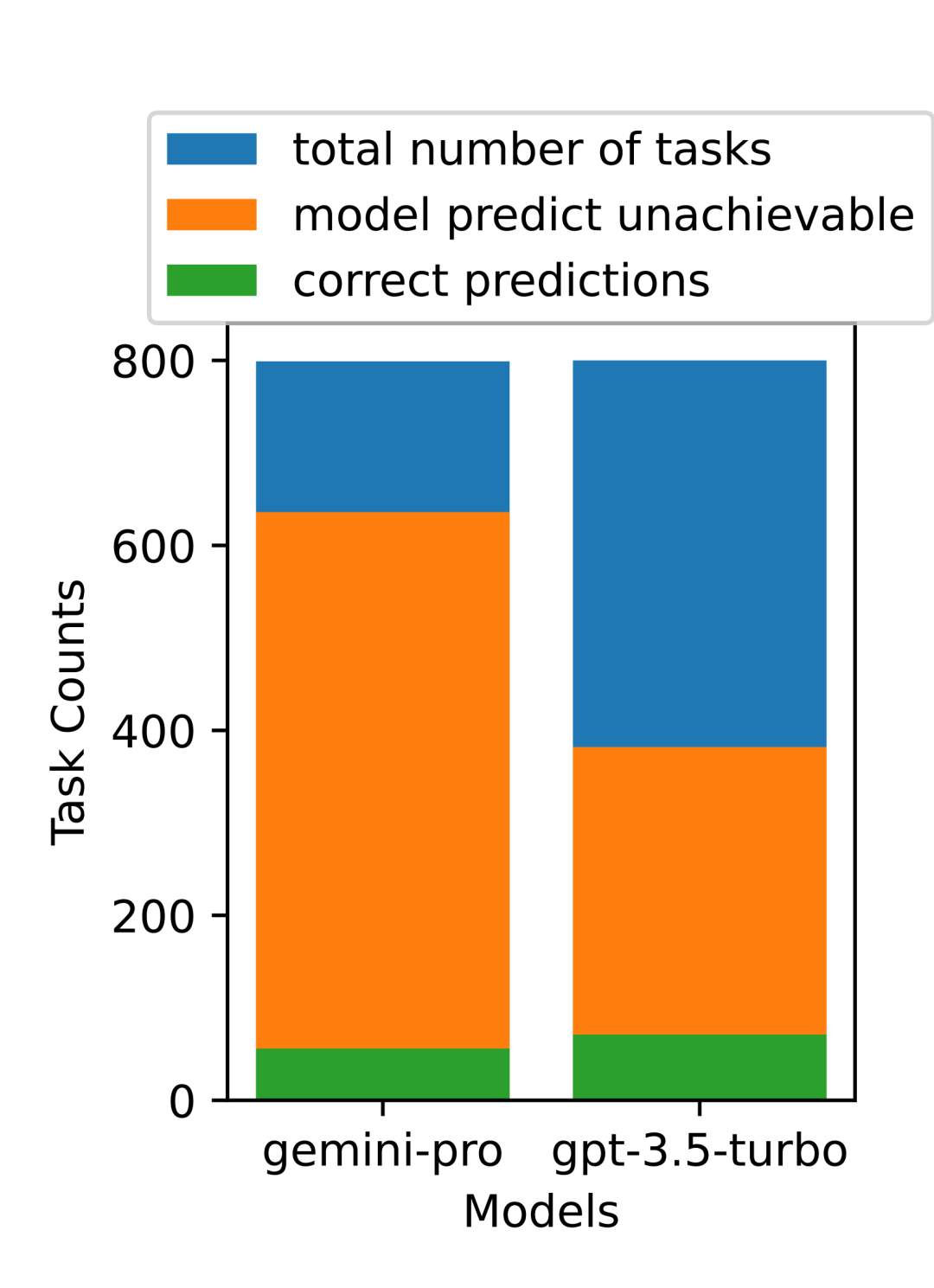
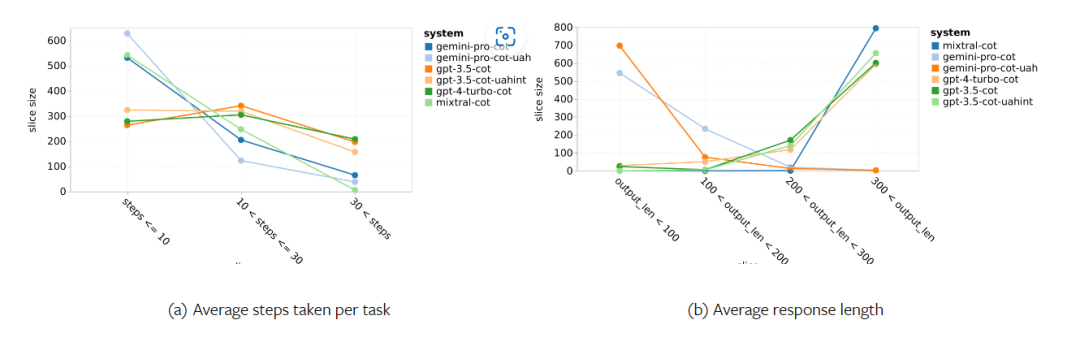
Figure 19: chrf performance (%) for masked and unmasked samples. Throughout the analysis of the model, the author observed that few-shot hints generally modestly improve average performance, with their variance pattern in order Incremental: GPT 4 Turbo #Figure 20 shows clear trends by language family or script. An important observation is that the Gemini Pro performs competitively with other models on Cyrillic script, but not as well on other scripts. GPT-4 performs outstandingly on various scripts, outperforming other models, among which few-shot hints are particularly effective. This effect is particularly evident in languages using Sanskrit. Figure 20: Performance of each model on different scripts (chrf (%)). Finally, the author examined The ability of each model to act as a network-navigating agent, a task that requires long-term planning and complex data understanding. They used a simulation environment, WebArena, where success was measured by execution results. Tasks assigned to the agent include information search, website navigation, and content and configuration manipulation. Tasks span a variety of websites, including e-commerce platforms, social forums, collaborative software development platforms (such as gitlab), content management systems, and online maps. The authors tested Gemini-Pro's overall success rate, success rate on different tasks, response length, trajectory steps, and tendency to predict task failure. Table 6 lists the overall performance. The performance of Gemini-Pro is close to, but slightly inferior to,GPT-3.5-Turbo. Similar to GPT-3.5-Turbo, Gemini-Pro performs better when the hint mentions that the task may not be completed (UA hint). With UA hint, Gemini-Pro has an overall success rate of 7.09%. Table 6: Performance of each model on WebArena. If you break it down by website type, as shown in Figure 21, you can see that Gemini-Pro performs worse than GPT on gitlab and map -3.5-Turbo, while the performance on shopping management, reddit and shopping websites is close to GPT-3.5-Turbo. Gemini-Pro outperforms GPT-3.5-Turbo on multi-site tasks, which is consistent with previous results showing that Gemini performs slightly better on more complex subtasks across various benchmarks. Figure 21: Web agent success rate of the model on different types of websites. As shown in Figure 22, in general, Gemini-Pro predicts more tasks as impossible to complete, especially when given a In the case of UA hint. Gemini-Pro predicted that more than 80.6% of the tasks could not be completed given the UA hint, while GPT-3.5-Turbo only predicted 47.7%. It is important to note that only 4.4% of the tasks in the dataset are actually unachievable, so both vastly overestimate the actual number of unachievable tasks. Figure 22: UA forecast quantity. At the same time, the authors observed that Gemini Pro was more likely to respond with shorter phrases, taking fewer steps before reaching a conclusion. step. As shown in Figure 23(a), Gemini Pro has more than half of its trajectories with less than 10 steps, while most trajectories of GPT 3.5 Turbo and GPT 4 Turbo are between 10 and 30 steps.Likewise, most of Gemini's replies are less than 100 characters long, while most of GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral's replies are more than 300 characters long (Figure 23(b)). Gemini tends to predict actions directly, while other models reason first and then give action predictions. Figure 23: Model behavior on WebArena. Please refer to the original paper for more details. The above is the detailed content of Full review of Gemini: From CMU to GPT 3.5 Turbo, Gemini Pro loses. For more information, please follow other related articles on the PHP Chinese website!




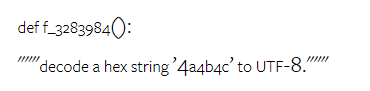

















 Official website entrance of major digital currency trading platforms 2025
Mar 31, 2025 pm 05:33 PM
Official website entrance of major digital currency trading platforms 2025
Mar 31, 2025 pm 05:33 PM
 On which platform is web3 transaction?
Mar 31, 2025 pm 07:54 PM
On which platform is web3 transaction?
Mar 31, 2025 pm 07:54 PM
 Top 10 of the formal Web3 trading platform APP rankings (authoritatively released in 2025)
Mar 31, 2025 pm 08:09 PM
Top 10 of the formal Web3 trading platform APP rankings (authoritatively released in 2025)
Mar 31, 2025 pm 08:09 PM
 What is blockchain privacy currency? What are the transactions?
Apr 20, 2025 pm 07:09 PM
What is blockchain privacy currency? What are the transactions?
Apr 20, 2025 pm 07:09 PM
 Which 2025 currency exchanges are more secure?
Apr 20, 2025 pm 06:09 PM
Which 2025 currency exchanges are more secure?
Apr 20, 2025 pm 06:09 PM
 What are the digital currency trading apps suitable for beginners? Learn about the coin circle in one article
Apr 22, 2025 am 08:45 AM
What are the digital currency trading apps suitable for beginners? Learn about the coin circle in one article
Apr 22, 2025 am 08:45 AM
 Recommend several apps to buy mainstream coins in 2025 latest release
Apr 21, 2025 pm 11:54 PM
Recommend several apps to buy mainstream coins in 2025 latest release
Apr 21, 2025 pm 11:54 PM
 Ranking of legal platform apps for virtual currency trading
Apr 21, 2025 am 09:27 AM
Ranking of legal platform apps for virtual currency trading
Apr 21, 2025 am 09:27 AM
