
 Technology peripherals
AI
DetZero: Waymo ranks first on the 3D detection list, comparable to manual annotation!
Technology peripherals
AI
DetZero: Waymo ranks first on the 3D detection list, comparable to manual annotation!
DetZero: Waymo ranks first on the 3D detection list, comparable to manual annotation!


This article proposes a set of offline 3D object detection algorithm framework DetZero. Through comprehensive research and evaluation on Waymo’s public data set, DetZero can generate continuous and complete objects. Trajectory sequence, and make full use of long-term point cloud features to significantly improve the quality of perception results. At the same time, it ranked first in the WOD 3D object detection rankings with a performance of 85.15 mAPH (L2). In addition, DetZero can provide high-quality automatic labeling for online model training, and its results have reached or even exceeded the level of manual labeling.
This is the paper link: https://arxiv.org/abs/2306.06023
The content that needs to be rewritten is: Code link: https://github.com/PJLab-ADG/ DetZero
Please visit the homepage link: https://superkoma.github.io/detzero-page
1 Introduction
In order to improve the data annotation efficiency, we studied a new approach. This method is based on deep learning and unsupervised learning and can automatically generate annotated data. By using large amounts of unlabeled data, we can train an autonomous driving perception model to recognize and detect objects on the road. This method can not only reduce the cost of labeling data, but also improve the efficiency of post-processing. We used Waymo's offline 3D object detection method 3DAL[] as a baseline for comparison in our experiments, and the results show that our proposed method has significant improvements in accuracy and efficiency. We believe that this method will play an important role in future autonomous driving technology
- Object detection (Detection): input a small amount of continuous point cloud frame data and output each frame Bounding boxes and category information of 3D objects in ;
- Motion ClassificationMotion Classification): Based on the object trajectory characteristics, determine the object’s motion state (stationary or moving);
- Object-centered optimization (Object-centric Refining): Based on the motion state predicted by the previous module, the temporal point cloud features of stationary and moving objects are extracted respectively to predict accurate bounding boxes. Finally, the optimized 3D bounding box is transferred back to the coordinate system of each frame where the object is located through the pose matrix.
- However, many mainstream online 3D object detection methods have achieved better results than existing offline 3D detection methods by utilizing the temporal context features of point clouds. However, we realize that these methods fail to effectively utilize the characteristics of long sequence point clouds
- The quality of the object sequence will have a great impact on the downstream optimization model
The optimization model based on motion state classification does not fully utilize the timing of the object feature. For example, the size of a rigid object remains consistent over time, and more accurate size estimation can be achieved by capturing data from different angles; the motion trajectory of the object should follow certain kinematic constraints, which is reflected in the smoothness of the trajectory. As shown in Figure (a) below, for dynamic objects, the optimization mechanism based on sliding windows does not consider the consistency of the object geometry, and only updates the bounding box through the time-series point cloud information of several adjacent frames, resulting in the predicted geometric size. Deviation occurs. In the example of (b), by aggregating all the point clouds of the object, dense time-series point cloud features can be obtained, and the accurate geometric size of the bounding box can be predicted for each frame. 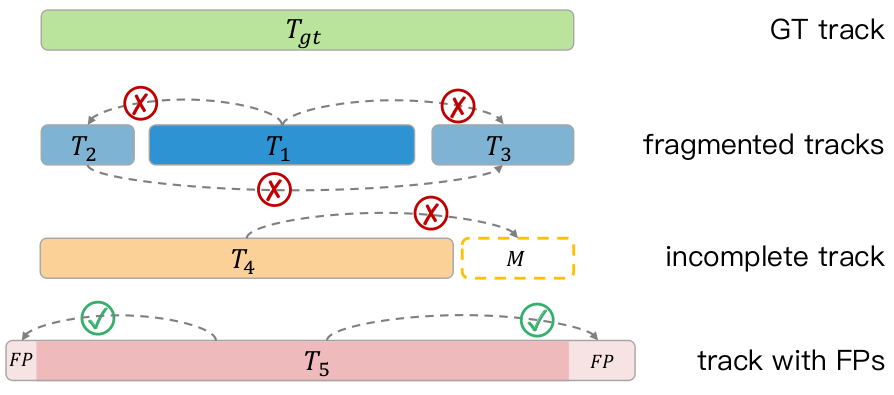
- The optimization model based on the motion state predicts the size of the object (a), and the geometric optimization model predicts the size of the object after aggregating all point clouds from different perspectives (b)
- Multi-view geometric interaction: by stitching multiple views Object point clouds can complete the appearance and shape of objects. First, local coordinate transformation is performed to align the object point cloud with local frames at different positions, and the projection distance of each point to the six surfaces of the bounding box is calculated to strengthen the information representation of the bounding box, and then directly merge all point clouds of different frames As the key and value of multi-view geometric features, t samples are randomly selected from the object sequence as queries for single-view geometric features. The geometric query will be sent to the self-attention layer to see the differences between each other, and then sent to the cross-attention layer to supplement the features of the required perspective and predict the accurate geometric size.
- Interaction between local and global positions: Randomly select any box in the object sequence as the origin, transfer all other boxes and corresponding object point clouds to this coordinate system, and calculate each point to its respective boundary The distance between the center point of the frame and the eight corner points serves as the key and value of the global position feature. Each sample in the object sequence will be used as a position query and sent to the self-attention layer to determine the relative distance between the current position and other positions. Then it is input to the cross-attention layer to simulate the context relationship from local to global positions and predict this coordinate system. The offset between each initial center point and the true center point, as well as the heading angle difference.
- Confidence Optimization: The classification branch is used to classify whether the object is TP or FP. The IoU regression branch predicts the IoU size between an object and the ground truth box after being optimized by the geometric model and position model. The final confidence score is the geometric mean of these two branches.
2 Method
This paper proposes a new offline 3D object detection algorithm framework called DetZero. This framework has the following characteristics: (1) Use multi-frame 3D detectors and offline trackers as upstream modules to provide accurate and complete object tracking, focusing on high recall of object sequences (track-level recall); (2) The downstream module includes an optimization model based on the attention mechanism, which uses long-term point cloud features to learn and predict different attributes of objects, including refined geometric dimensions, smooth motion trajectory positions, and updated confidence scores
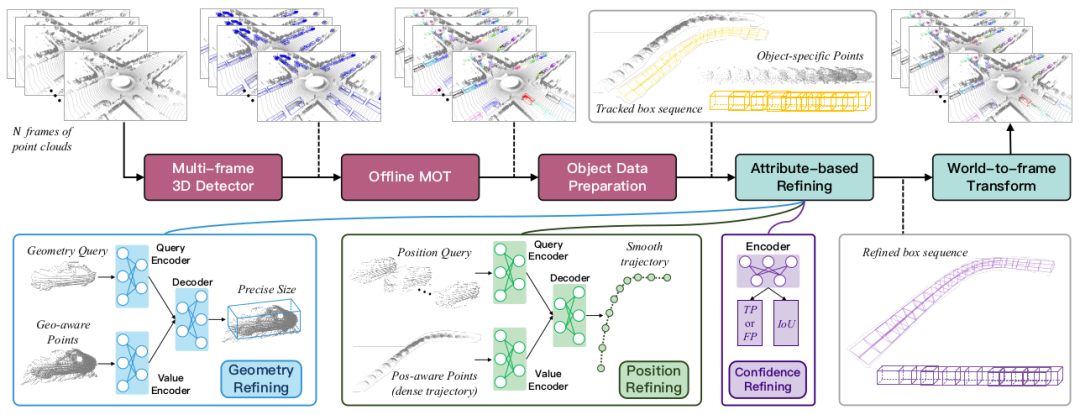
2.1 Generate a complete object sequence
We use the public CenterPoint[] as the basic detector. In order to provide more detection candidate frames, we proceed in three aspects Enhanced: (1) Use different frame point cloud combinations as input to maximize performance without reducing performance; (2) Use point cloud density information to fuse original point cloud features and voxel features into a two-stage module to optimize the first stage Boundary results; (3) Use inference stage data augmentation (TTA), multi-model result fusion (Ensemble) and other technologies to improve the model's adaptability to complex environments
A two-stage correlation strategy is introduced in the offline tracking module To reduce false matching, boxes are divided into high and low groups according to confidence, high groups are associated to update existing trajectories, and unupdated trajectories are associated with low groups. At the same time, the length of the object trajectory can last until the end of the sequence, avoiding ID switching problems. In addition, we will perform the tracking algorithm in reverse to generate another set of trajectories, associate them through position similarity, and finally use the WBF strategy to fuse the successfully matched trajectories to further improve the integrity of the beginning and end of the sequence. Finally, for the differentiated object sequence, the corresponding point cloud of each frame is extracted and saved; the unupdated redundant boxes and some shorter sequences will be directly merged into the final output without downstream optimization.
2.2 Object optimization module based on attribute prediction
Previous object-centered optimization models ignored the correlation between objects in different motion states, such as Consistency of geometric shapes and consistency of object motion states at adjacent moments. Based on these observations, we decompose the traditional bounding box regression task into three modules: predicting the geometry, location and confidence attributes of objects respectively
3 Experiment
3.1 Main performance
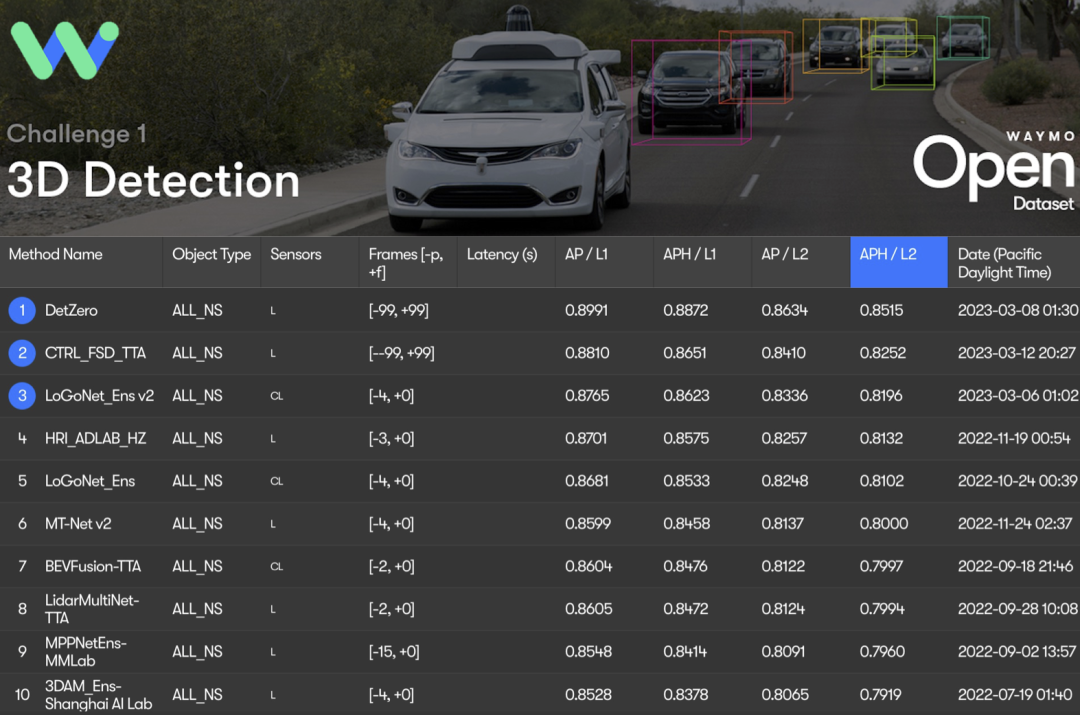
DetZero achieved 85.15 mAPH ( L2) achieved the best results, DetZero showed significant performance advantages whether compared with methods for processing long-term point clouds or compared with state-of-the-art multi-modal fusion 3D detectors
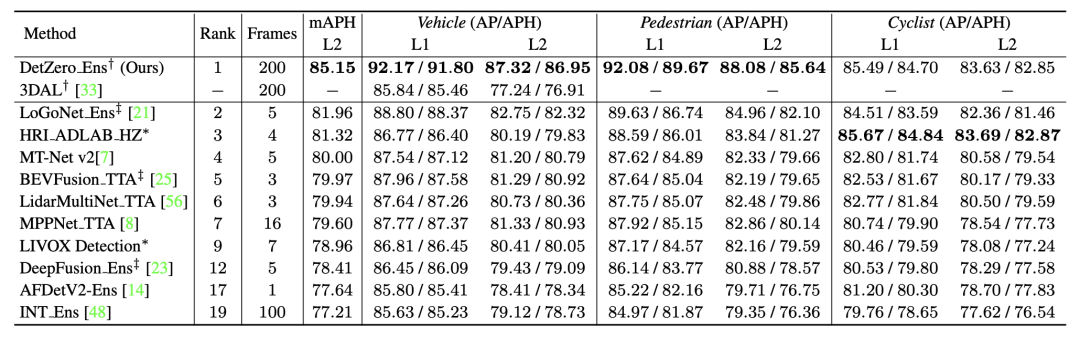 Waymo 3D detection ranking results, all results use TTA or ensemble technology, † refers to offline model, ‡ refers to point cloud image fusion model, * indicates anonymous submission results
Waymo 3D detection ranking results, all results use TTA or ensemble technology, † refers to offline model, ‡ refers to point cloud image fusion model, * indicates anonymous submission results
Similarly, thanks to the detection frame In terms of accuracy and completeness of object tracking sequences, we achieved first place in performance on the Waymo 3D tracking rankings with 75.05 MOTA (L2).
 Waymo 3D tracking rankings, * indicates anonymous submission of results
Waymo 3D tracking rankings, * indicates anonymous submission of results
3.2 Ablation experiment
In order to better verify the role of each module we proposed, we conducted an ablation experiment on the Waymo verification set and adopted a more stringent IoU Threshold as a measurement standard
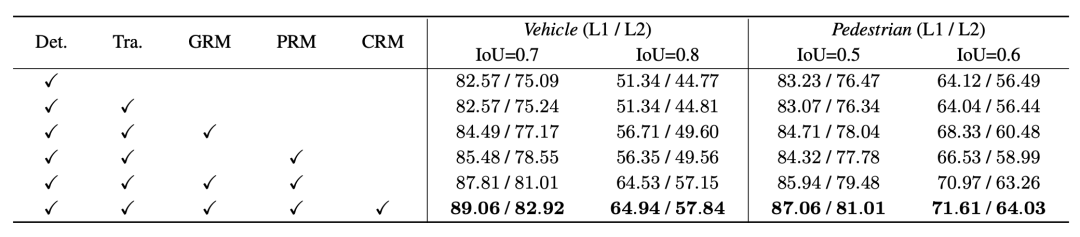 Conducted on Vehicle and Pedestrian on the Waymo verification set, the IoU threshold selected standard value (0.7 & 0.5) and strict value (0.8 & 0.6) respectively
Conducted on Vehicle and Pedestrian on the Waymo verification set, the IoU threshold selected standard value (0.7 & 0.5) and strict value (0.8 & 0.6) respectively
At the same time , for the same set of detection results, we selected the tracker and optimization model in 3DAL and DetZero for cross-combination verification. The results further proved that DetZero’s tracker and optimizer perform better, and the two are more effective when combined. The advantages.
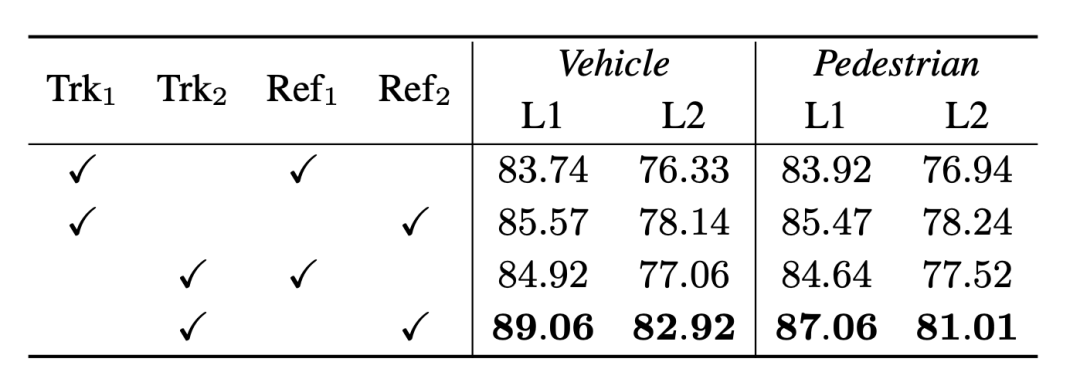 Cross-validation experiments of different upstream and downstream module combinations, the subscripts 1 and 2 represent 3DAL and DetZero respectively, and the indicator is 3D APH
Cross-validation experiments of different upstream and downstream module combinations, the subscripts 1 and 2 represent 3DAL and DetZero respectively, and the indicator is 3D APH
Our offline tracker pays more attention to the object sequence Completeness, although the MOTA performance difference between the two is very small, the performance of Recall@track is one of the reasons for the huge difference in final optimization performance
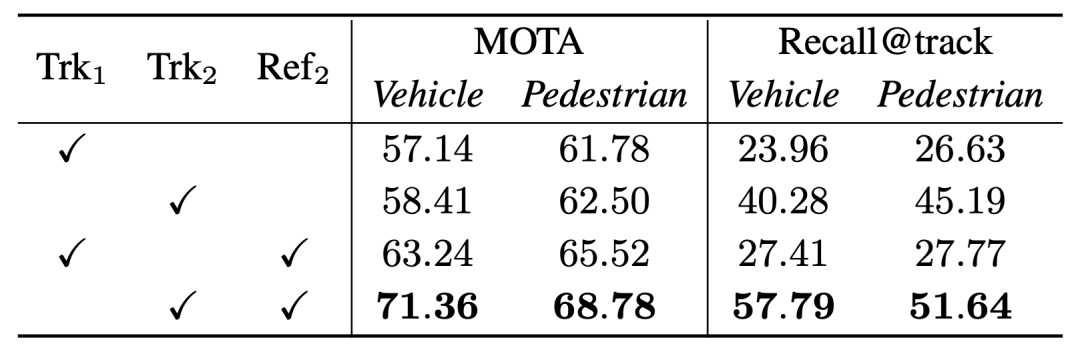 Offline tracker (Trk2) and 3DAL tracker (Trk1) performance comparison of MOTA and Recall@track
Offline tracker (Trk2) and 3DAL tracker (Trk1) performance comparison of MOTA and Recall@track
Furthermore, comparison with other state-of-the-art trackers also proves the point
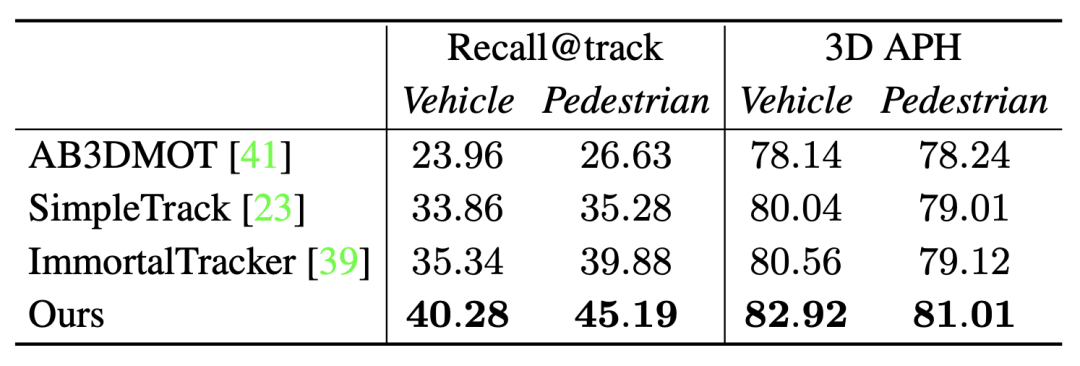 Recall@track is Sequence recall after processing by the tracking algorithm, 3D APH is the final performance after processing by the same optimization model
Recall@track is Sequence recall after processing by the tracking algorithm, 3D APH is the final performance after processing by the same optimization model
3.3 Generalization performance
In order to verify our optimization model Whether it is possible to fix the fit to a specific set of upstream results, we selected upstream detection tracking results with different performances as input. The results show that we have achieved significant performance improvements, further proving that as long as the upstream module can recall more and more complete object sequences, our optimizer can effectively utilize the characteristics of its time series point cloud for optimization
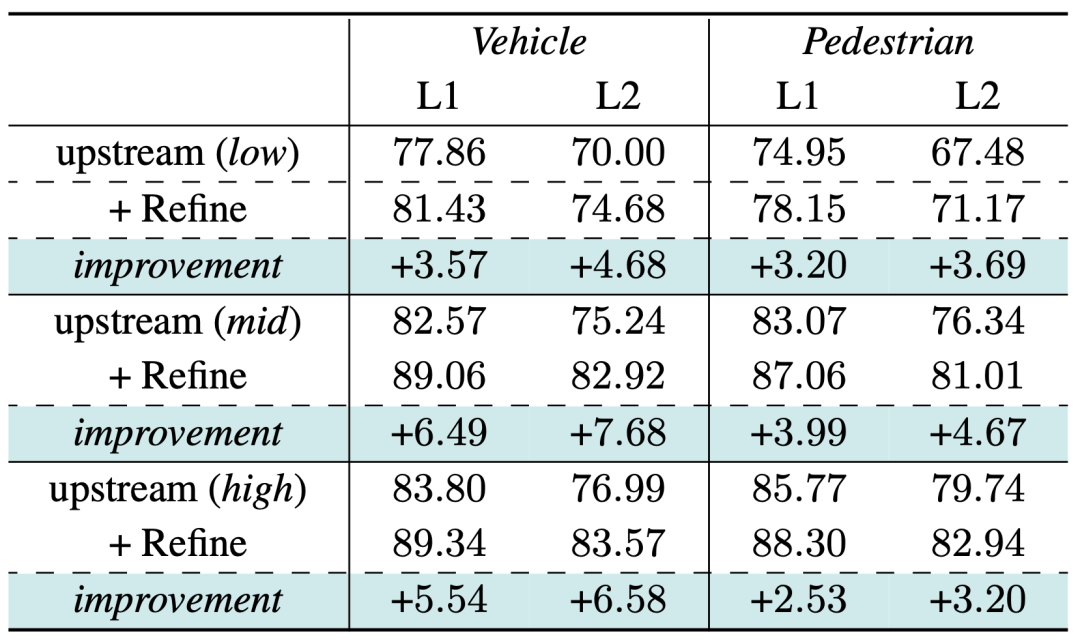 Generalization performance verification on the Waymo validation set, the indicator is 3D APH
Generalization performance verification on the Waymo validation set, the indicator is 3D APH
3.4 Comparison with human labeling ability
We will use the experimental settings of 3DAL to compare Report the AP performance of DetZero on 5 specified sequences, measuring human performance by comparing the consistency of single-frame-based re-annotation results with the original ground-truth annotation results. Compared with 3DAL and humans, DetZero has shown advantages in different performance indicators
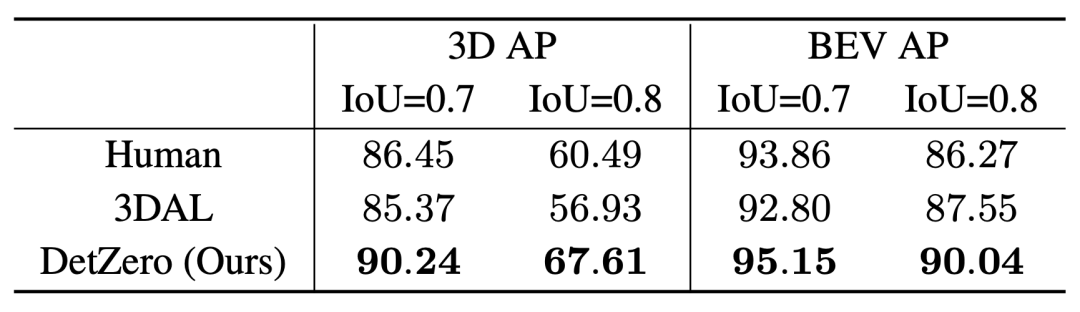 Performance comparison of 3D AP and BEV AP under different IoU thresholds for the Vehicle category
Performance comparison of 3D AP and BEV AP under different IoU thresholds for the Vehicle category
For To verify whether high-quality automatic annotation results can replace manual annotation results for online model training, we conducted semi-supervised learning verification on the Waymo verification set. We randomly selected 10% of the training data as the training data for the teacher model (DetZero), and performed inference on the remaining 90% of the data to obtain automatic annotation results, which will be used as labels for the student model. We chose single-frame CenterPoint as the student model. On the vehicle category, the results of training using 90% automatic labels and 10% true labels are close to the results of training using 100% true labels, while on the pedestrian category, the results of the model trained with automatic labels are already better than the original ones. The result, which shows that automatic labeling can be used for online model training
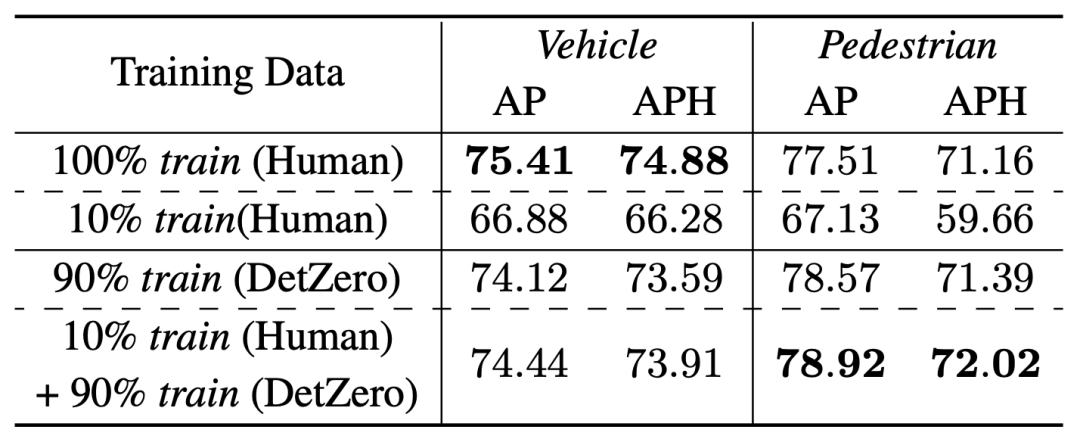 Semi-supervised experimental results on the Waymo validation set
Semi-supervised experimental results on the Waymo validation set
3.5 Visualization results
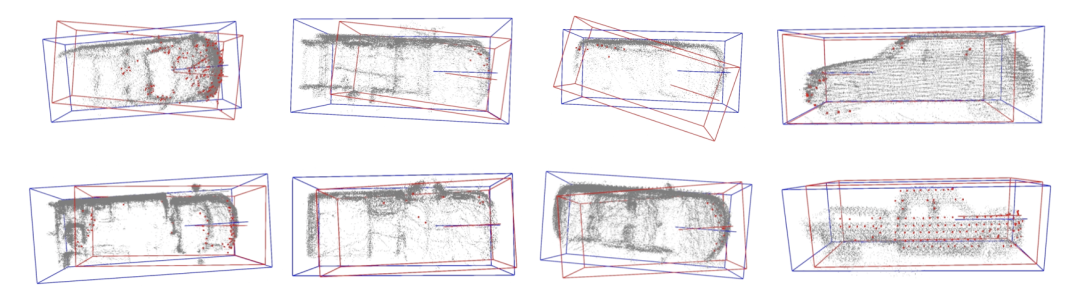 The red box represents the input result of the upstream, and the blue box represents the output result of the optimization model
The red box represents the input result of the upstream, and the blue box represents the output result of the optimization model 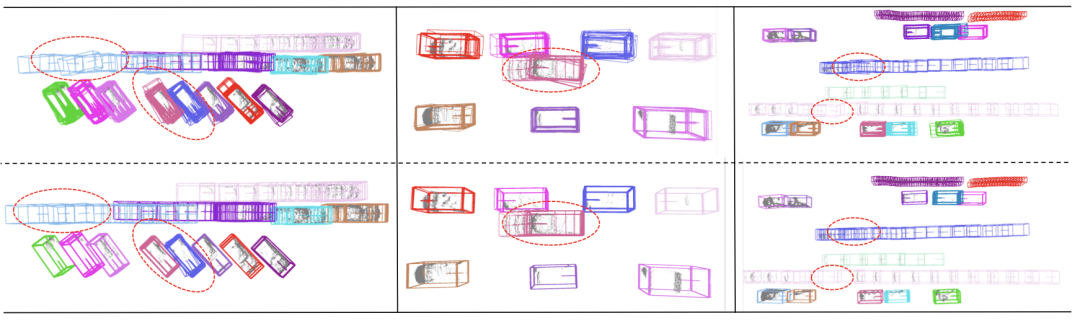 The first line represents the input result of the upstream, the second line represents the output result of the optimization model, and the objects within the dotted line represent Positions with obvious differences before and after optimization
The first line represents the input result of the upstream, the second line represents the output result of the optimization model, and the objects within the dotted line represent Positions with obvious differences before and after optimization

Original link: https://mp.weixin.qq.com/s/HklBecJfMOUCC8gclo-t7Q
The above is the detailed content of DetZero: Waymo ranks first on the 3D detection list, comparable to manual annotation!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
