
 Technology peripherals
AI
NVIDIA RTX graphics card speeds up AI inference by 5 times! RTX PC easily handles large models locally
Technology peripherals
AI
NVIDIA RTX graphics card speeds up AI inference by 5 times! RTX PC easily handles large models locally
NVIDIA RTX graphics card speeds up AI inference by 5 times! RTX PC easily handles large models locally

At the Microsoft Iginte Global Technology Conference, Microsoft released a series of new AI-related optimization models and development tool resources, aiming to help developers make full use of hardware performance and expand AI application fields
Especially for NVIDIA, which currently occupies an absolute dominant position in the AI field, Microsoft has sent a big gift package this time, Whether it is the TensorRT-LLM packaging interface for OpenAI Chat API, or RTX-driven Performance improvements DirectML for Llama 2, as well as other popular large language models (LLM), can be better accelerated and applied on NVIDIA hardware.
Among them, TensorRT-LLM is a library used to accelerate LLM inference, which can greatly improve AI inference performance. It is constantly being updated to support more and more language models, and it is also open source.
NVIDIA released TensorRT-LLM for Windows platforms in October. For desktops and laptops equipped with RTX 30/40 series GPU graphics cards, as long as the graphics memory reaches 8GB or more, demanding AI workloads can be completed more easily
Now, Tensor RT-LLM for Windows can be compatible with OpenAI’s popular chat API through a new encapsulation interface, so various related applications can be run directly locally without the need to connect to the cloud, which is beneficial Keep private and proprietary data on your PC to prevent privacy leaks.
As long as it is a large language model optimized by TensorRT-LLM, it can be used with this packaging interface, including Llama 2, Mistral, NV LLM, etc.
For developers, there is no need for tedious code rewriting and porting. Just modify one or two lines of code, and the AI application can be executed quickly locally.

↑↑↑Microsoft Visual Studio code plug-in based on TensorRT-LLM - Continue.dev coding assistant
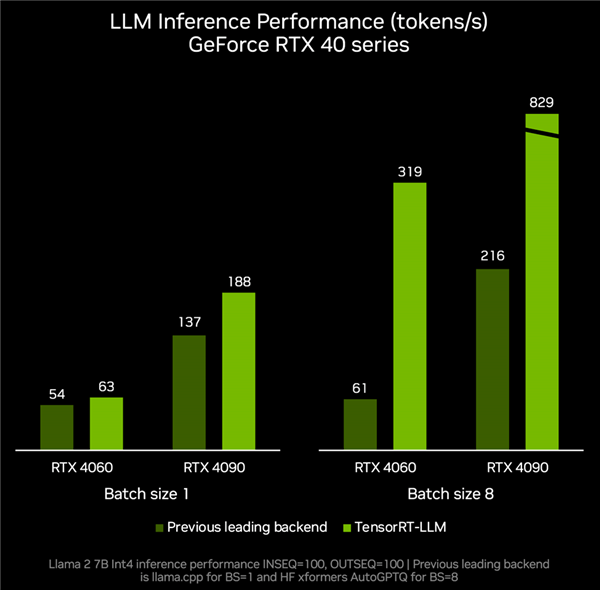
TensorRT-LLM v0.6.0 will be updated at the end of this month, which will bring up to 5 times improvement in inference performance on RTX GPU, and support more popular LLMs, including new The 7 billion parameter Mistral and 8 billion parameter Nemotron-3 allow desktops and laptops to run LLM locally at any time, quickly and accurately.
According to actual measurement data, RTX 4060 graphics card paired with TenroRT-LLM, the inference performance can reach 319 tokens per second, which is a full 4.2 times faster than the 61 tokens per second of other backends.
RTX 4090 can accelerate from tokens per second to 829 tokens per second, an increase of 2.8 times.
With its powerful hardware performance, rich development ecosystem and wide range of application scenarios, NVIDIA RTX is becoming an indispensable and powerful assistant for local AI. At the same time, with the continuous enrichment of optimization, models and resources, the popularity of AI functions on hundreds of millions of RTX PCs is also accelerating
Currently, more than 400 partners have released AI applications and games that support RTX GPU acceleration. As the ease of use of models continues to improve, I believe that more and more AIGC functions will appear on the Windows PC platform. .
The above is the detailed content of NVIDIA RTX graphics card speeds up AI inference by 5 times! RTX PC easily handles large models locally. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
 Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
2024 witnessed a shift from simply using LLMs for content generation to understanding their inner workings. This exploration led to the discovery of AI Agents – autonomous systems handling tasks and decisions with minimal human intervention. Buildin
 Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
The article reviews top AI voice generators like Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, and Descript, focusing on their features, voice quality, and suitability for different needs.
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
