
 Technology peripherals
AI
Reverse thinking: MetaMath new mathematical reasoning language model trains large models
Technology peripherals
AI
Reverse thinking: MetaMath new mathematical reasoning language model trains large models
Reverse thinking: MetaMath new mathematical reasoning language model trains large models

Complex mathematical reasoning is an important indicator for evaluating the reasoning ability of large language models. Currently, the commonly used mathematical reasoning data sets have limited sample sizes and insufficient problem diversity, resulting in the phenomenon of "reversal curse" in large language models, that is, a A language model trained on "A is B" cannot be generalized to "B is A" [1]. The specific form of this phenomenon in mathematical reasoning tasks is: given a mathematical problem, the language model is good at using forward reasoning to solve the problem but lacks the ability to solve the problem with reverse reasoning. Reverse reasoning is very common in mathematical problems, as shown in the following 2 examples.
1. Classic problem - chickens and rabbits in the same cage
- Forward reasoning: There are 23 chickens and 12 rabbits in the cage , ask how many heads and how many feet are there in the cage?
- Reverse reasoning: There are several chickens and rabbits in the same cage. Counting from the top, there are 35 heads, and counting from the bottom, there are 94 legs. How many chickens and rabbits are there in the cage?
2. GSM8K Question
- Forward reasoning: James buys 5 packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay?
- Converse reasoning: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. . How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
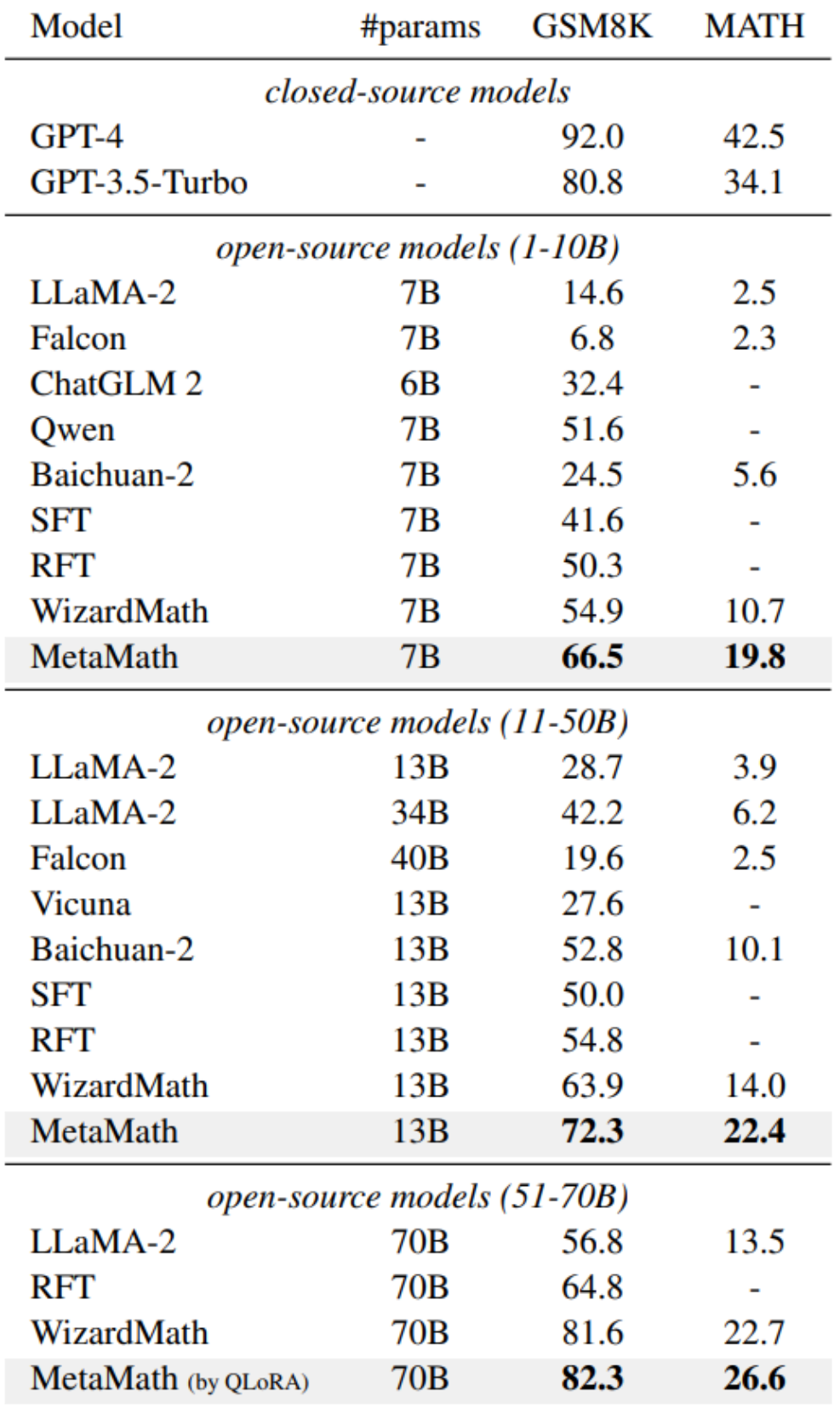
In order to improve the forward sum of the model For reverse reasoning capabilities, researchers from Cambridge, Hong Kong University of Science and Technology, and Huawei proposed the MetaMathQA data set based on two commonly used mathematical data sets (GSM8K and MATH): a mathematical reasoning data set with wide coverage and high quality. MetaMathQA consists of 395K forward-inverse mathematical question-answer pairs generated by a large language model. They fine-tuned LLaMA-2 on the MetaMathQA data set to obtain MetaMath, a large language model focusing on mathematical reasoning (forward and inverse), which reached SOTA on the mathematical reasoning data set. The MetaMathQA dataset and MetaMath models at different scales have been open sourced for use by researchers.

- ##Project address: https://meta-math.github.io/
- Paper address: https://arxiv.org/abs/2309.12284
- Data address: https://huggingface.co/datasets/meta-math/MetaMathQA
- Model address: https://huggingface.co/meta-math
- Code address: https://github.com/meta-math/MetaMath
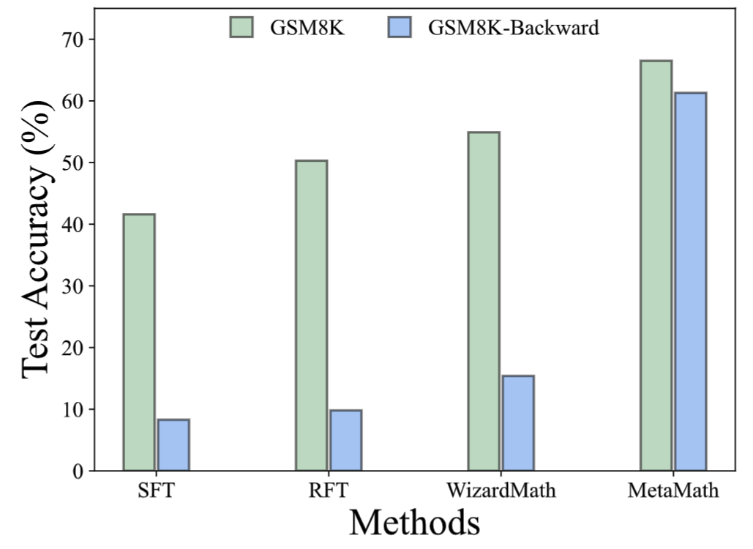
In the GSM8K-Backward data set, we constructed a reverse inference experiment. Experimental results show that compared with methods such as SFT, RFT, and WizardMath, the current method performs poorly on inverse inference problems. In contrast, MetaMath models achieve excellent performance in both forward and backward inference
Method
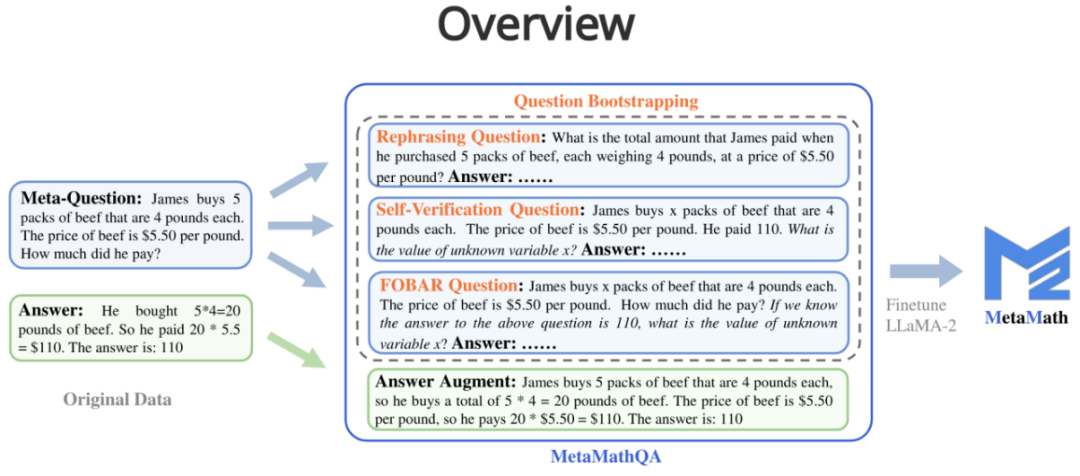
MetaMathQA contains four data augmentation methods:
1. Answer Augmentation (answer Enhancement): Given a problem, a thinking chain that can get the correct result is generated through a large language model as data augmentation.
- Question: James buys 5 packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay?
- Answer: James buys 5 packs of beef that are 4 pounds each, so he buys a total of 5 * 4 = 20 pounds of beef. The price of beef is $5.50 per pound, so he pays 20 * $5.50 = $110. The answer is: 110.
2. Rephrasing Question (question rewriting enhancement): Given meta-question , rewrite the problem through a large language model and generate a thought chain that gets the correct result as data augmentation.
- Question: What is the total amount that James paid when he purchased 5 packs of beef, each weighing 4 pounds, at a price of $5.50 per pound?
- Answer: Each pack of beef weighs 4 pounds, so 5 packs weigh 4 * 5 = 20 pounds in total. The price per pound of beef is $5.50, so the total cost for 20 pounds is 20 * $5.50 = $110. Therefore, James paid a total of $110. The answer is: 110.
##3. FOBAR Question (FOBAR reverse question enhancement):Given the meta-question, the number in the mask condition is Example: "If we know the answer to the above question is 110, what is the value of unknown variable x?").
- Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
- Answer: James buys x packs of beef that are 4 pounds each, so he buys a total of 4x pounds of beef. The price of beef is $5.50 per pound, so the total cost of the beef is 5.50 * 4x = 22x. We are given that the total cost is $110, so we can write: 22x = 110. Dividing both sides by 22, we get: x = 5. The value of x is 5.
4. Self-Verification Question (Self-Verification reverse question enhancement): Based on FOBAR, data augmentation is performed by rewriting the inverse problem part into statements using a large language model (rewritten example: "How much did he pay?" (with the answer 110) was rewritten into "He paid 110").
- Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. He paid 110. What is the value of unknown variable x ?
- Answer: To solve this problem, we need to determine the value of x, which represents the number of packs of beef that James bought. Each pack of beef weighs 4 pounds and costs $5.50 per pound. The total amount James paid is $110. We can set up the equation as follows: Number of packs of beef * Weight per pack * Price per pound = Total amount paid; x * 4 * $5.50 = $110; Let's simplify and solve for x: 4x * $5.50 = $110; 22x = $110; To isolate x, we divide both sides of the equation by 22: 22x / 22 = $110 / 22; x = $5; The value of x is 5.
Experimental results
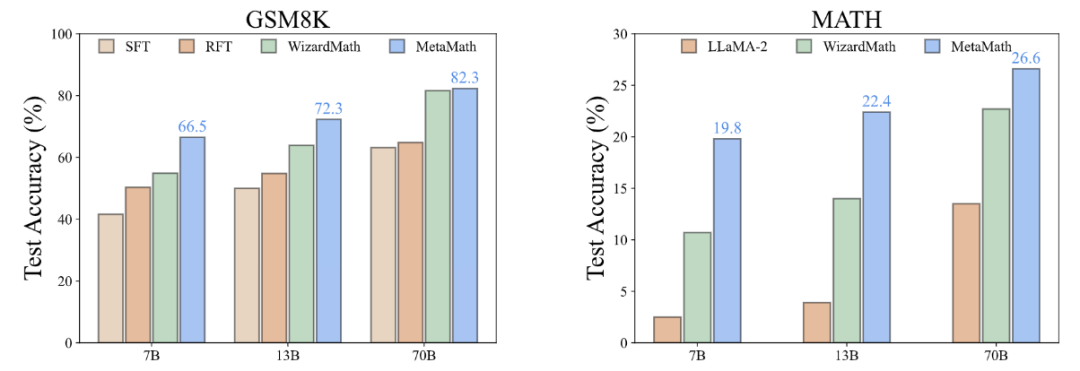
According to the "Surface Alignment Assumption" [2], The power of large language models comes from pre-training, and data from downstream tasks activates the inherent capabilities of the language model learned during pre-training. Therefore, this raises two important questions: (i) which type of data activates latent knowledge most effectively, and (ii) why is one dataset better at such activation than another?
Why is MetaMathQA useful? Improved the quality of thought chain data (Perplexity)
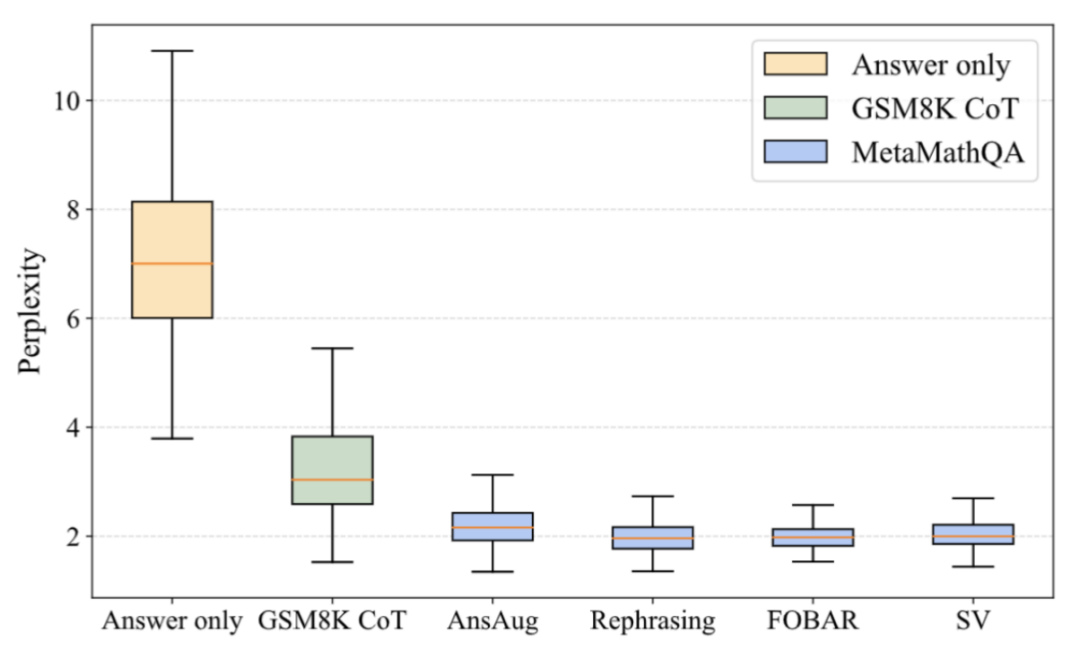 ##As shown in the figure above, the researchers calculated Perplexity of the LLaMA-2-7B model on answer-only data, GSM8K CoT, and various parts of the MetaMathQA dataset. The perplexity of the MetaMathQA dataset is significantly lower than the other two datasets, indicating that it has higher learnability and may be more helpful in revealing the latent knowledge of the model
##As shown in the figure above, the researchers calculated Perplexity of the LLaMA-2-7B model on answer-only data, GSM8K CoT, and various parts of the MetaMathQA dataset. The perplexity of the MetaMathQA dataset is significantly lower than the other two datasets, indicating that it has higher learnability and may be more helpful in revealing the latent knowledge of the model
Why is MetaMathQA useful? Increased the diversity of thought chain data (Diversity)
By comparing the diversity gain of the data and the accuracy gain of the model, the researchers found that the introduction of the same amount of augmented data by reformulation, FOBAR and SV all brought A significant diversity gain was achieved and the accuracy of the model was significantly improved. In contrast, using answer augmentation alone resulted in significant saturation of accuracy. After the accuracy reaches saturation, adding AnsAug data will only bring limited performance improvement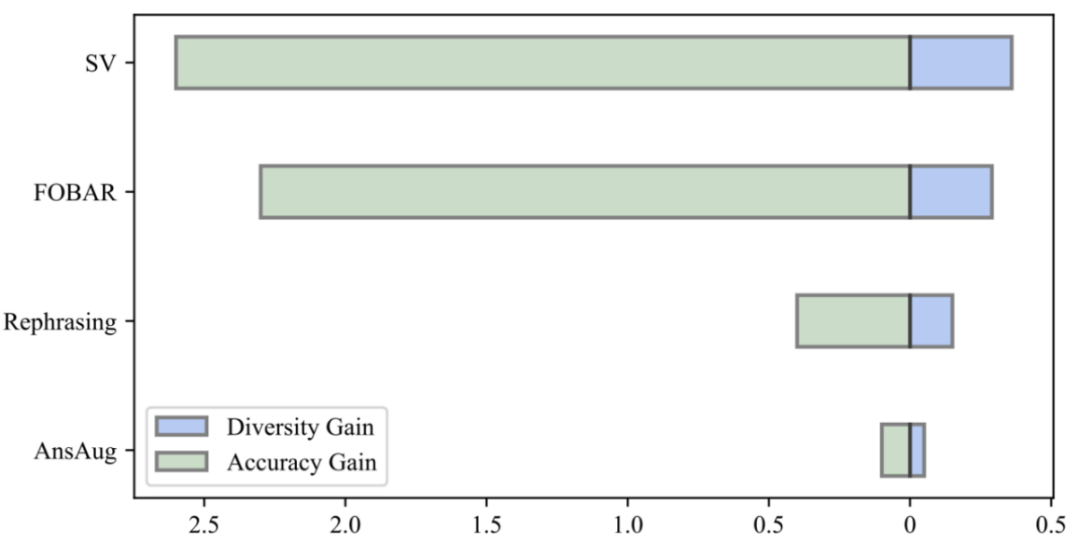
The above is the detailed content of Reverse thinking: MetaMath new mathematical reasoning language model trains large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
