
 Operation and Maintenance
Safety
Zuoyebang Nie An: How to transform operation and maintenance, listen to Zuoyebang's OPaS ideas
Operation and Maintenance
Safety
Zuoyebang Nie An: How to transform operation and maintenance, listen to Zuoyebang's OPaS ideas
Zuoyebang Nie An: How to transform operation and maintenance, listen to Zuoyebang's OPaS ideas


In the first issue, the boss of Yangqingjing expressed many interesting views. Some people left a message saying that it was about operation and maintenance. Guide to persuading people to quit, haha, the guests in this issue will have different opinions. Please keep an open mind, listen to the opinions of hundreds of schools of thought, and make your own career and life plans. As the saying goes, if you listen to both, you will be enlightened, but if you believe only, you will be dark. If you only listen to what suits your ears, there is a high probability that there will be no in-depth thinking and collision, which is a pity.
This is the second issue of the down-to-earth and high-level "Operation and Maintenance Forum", let's start!
Guest Introduction
In this issue we invite Nie An, the head of operation and maintenance of Zuoyebang. Nie An is a senior industry veteran who has worked for Alibaba, Xiaomi, Didi Di and Zuoyebang have more than 10 years of operation and maintenance/R&D/management experience.
Brief description of key points
- Traditional operation and maintenance is responsible for assembling industrial products into services, delivering them to users, and maintaining service operations; it is characterized by strong dependence on the business
- Domain crisis. In the cloud native era, public clouds are widely used, microservice architecture and DevOps are truly achieved, tool systems continue to prosper, and traditional operation and maintenance responsibilities are constantly being outsourced, transferred, and replaced. A domain crisis has emerged
- Organizational structure, the collaboration method has gradually upgraded from everyone's collaboration to platform self-service, and the main theme of operation and maintenance has changed from horizontal collaboration to service products and technology middle platform
- Operation and maintenance transformation, technically through the self-service platform , the external operation and maintenance service capability OPaS (OP as Service) is divided into two layers: objects and scenarios; the underlying objects are maintained isomorphically, forming a sustainable operation and maintenance architecture
- Business operation and maintenance, The core of service-oriented transformation is role recognition. Operations and maintenance personnel must adjust themselves from an operational role that is dependent on the business to an independent operation and maintenance service provider; from a hyper-service perspective, business operation and maintenance has great potential
- Component operation and maintenance, controlling the component itself, goes further than pure operation and maintenance management, following the onion model, that is, based on resource delivery, building a management platform, and then going deep into the professional field of the component itself
- Operation and maintenance development, stripped out Repeated platform iteration work focused on the public operation and maintenance center, specialized in technology and high leverage
Operation and maintenance stage
Internet operation and maintenance has experienced pure manual, There are several stages such as standardization, platformization, and digital intelligence, as shown in the figure below. Among them, DevOps is a technology-driven organizational change and a non-professional change.
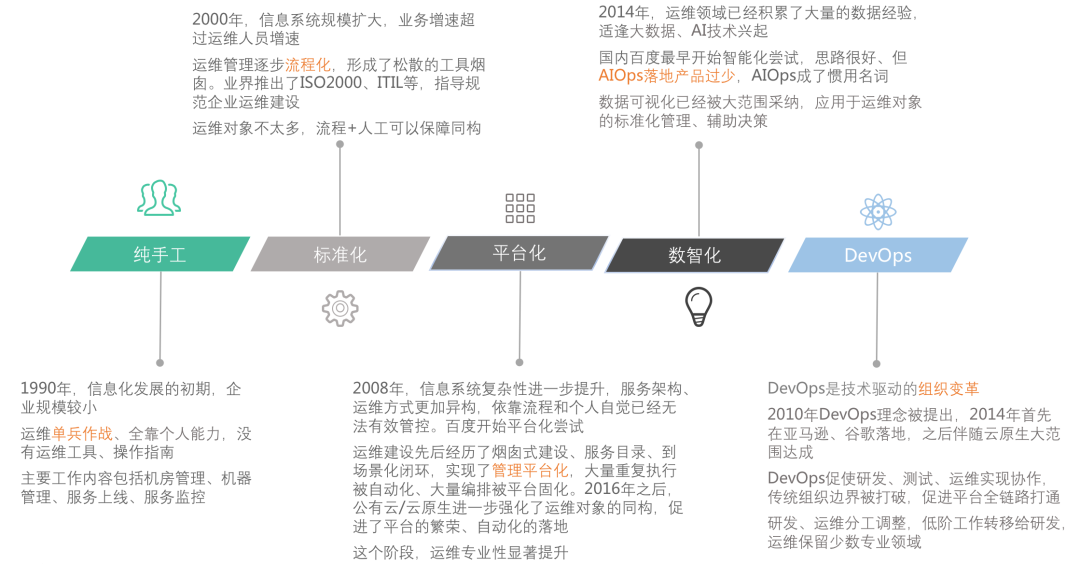
From the development history of operation and maintenance, we can see several characteristics:
- Inheritance. The new stage often inherits and carries forward the excellent experience of the old stage, and innovates in concepts, technologies, and organizations
- For example, platformization inherits and strengthens the results of the standardization stage, and data Intelligentization inherits the achievements of platformization and introduces big data technology
- Responsibility transfer. DevOps is a watershed in the operation and maintenance management model. Operations and maintenance after DevOps
- On the one hand, continue to advance in the direction of operation and maintenance specialization, and maintain the ability to manage isomorphic management of higher-level operation and maintenance objects.
- On the other hand, it emphasizes the integration of operation and maintenance, R&D, and the responsibilities of operation and maintenance are gradually transferred to business research and development
Learning the development history of a certain field allows us to learn from history and take advantage of the trend. .
Traditional Operation and Maintenance
In the traditional operation and maintenance model, service objects can basically be divided into three layers. The lowest layer is the hardware infrastructure IaaS, which is mainly composed of computing, network, and storage; the middle layer is the software infrastructure, including operating systems, virtualization technology, code frameworks, middleware, etc.; the top layer is the business layer, mainly application services .
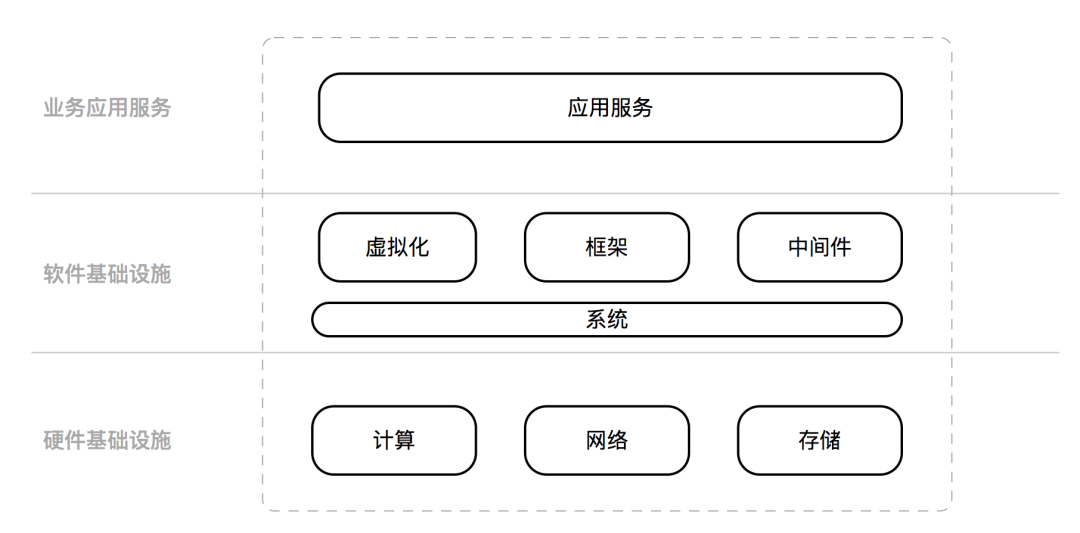
The traditional responsibility of operation and maintenance is to assemble industrial products into services through a series of processes, technologies, and methods. Deliver it to users and maintain service operation; it is usually required to achieve multiple-dimensional goals (operability) such as stability, cost, security, and efficiency. To a certain extent, traditional operation and maintenance needs to be attached to the business to generate value; many companies will regard whether they understand the business as one of the main assessments of operation and maintenance workers (dependence). With the popularization of cloud computing and cloud native technology, the traditional operation and maintenance model has encountered many challenges. for example,
- After enterprises use public cloud, IaaS/PaaS and even SaaS are basically service-oriented and can be obtained through API; a large amount of operation and maintenance construction work is completed with the help of cloud vendors, such as hardware, system, network, For databases, big data, etc., the original factory only needs to retain a small amount of professional selection and integration capabilities (outsourcing)
- After the popularization of cloud native technology, microservice architecture and DevOps were achieved on a large scale, which was previously completed by professional operation and maintenance personnel Operations are gradually handed over to business R&D for self-service completion, such as delivery, change, monitoring, capacity, etc. Operation and maintenance responsibilities are largely transferred to business R&D (transfer)
- The professional aggregation effect of public cloud and the cloud native The open source system provides continued improvement in tooling prospects. After tooling improves efficiency, the same position requires less labor; tooling accumulates professional capabilities and the technical threshold for operators is getting lower and lower; after tools evolve to automation and intelligence, machines can replace labor. The replacement of labor by platforms is still gradually deepening (replacement)
As mentioned above, after infrastructure is outsourced to public clouds and cloud native, operation and maintenance responsibilities are transferred to business research and development, and platforms replace labor professionals. sex. Faced with such trends and facts, operation and maintenance practitioners need to make some transformations.
Organizational Structure
First let’s talk about the organizational structure. In the long term, the organizational form of a company in the cloud native era will consist of the following parts:

The top end user is the enterprise’s Party A customer , are also potential profit-making groups. The business team is responsible for end users, and its roles include product, business, marketing, marketing, etc. Business research and development directly serves the business team, mainly providing SaaS applications/services. Platform research and development serves business research and development, provides various PaaS capabilities, and encapsulates cloud vendors. There will also be some cross-functional organizations, such as cost operation FinOps, efficiency operation EP, administrative team IT, etc.
In the new organizational structure, everyone’s ultimate goal is to do their own thing and serve end users well. The business team pays more attention to business value, and the R&D system focuses on service quality. With the advancement of information technology, the functions currently performed by cross-functional organizations will gradually be decomposed to the platform R&D team. The main method of organizational collaboration will be upgraded from everyone's collaboration to platform self-service. Operations and maintenance have new job goals, namely: The main theme of operation and maintenance is the management platform, resource & technology center, not horizontal collaboration. Operations and maintenance must use high technology leverage, empower business, and help enterprises improve operating efficiency. .

Technical Architecture
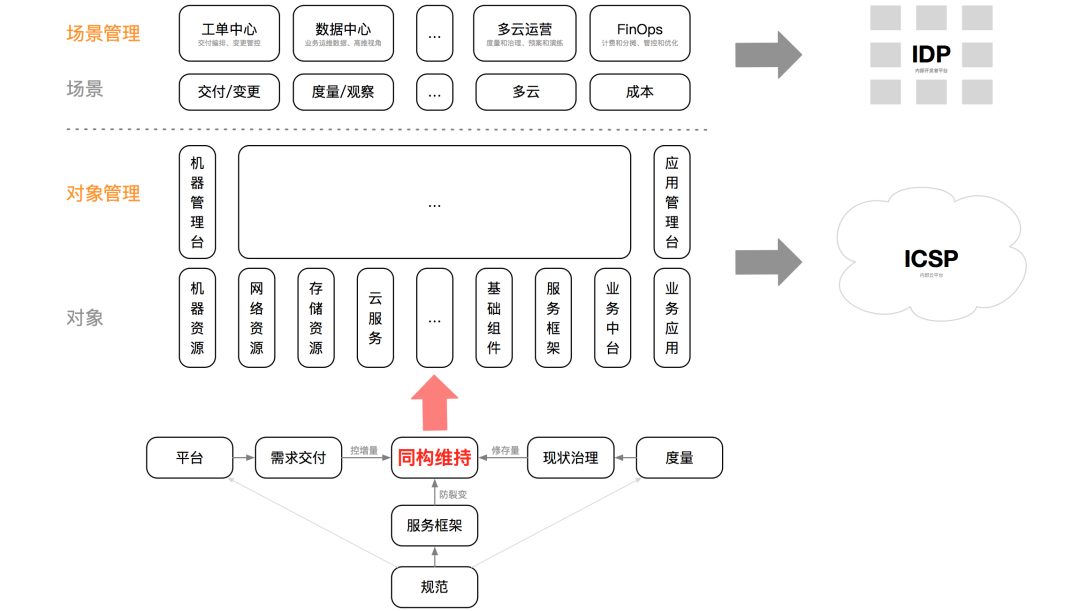
Operation and maintenance transformation, the goal is to provide operation and maintenance management to upper-level teams through a self-service platform Service; the essence is operation and maintenance service OPaS (OP as Service). According to content differences, operation and maintenance work can be divided into two categories: object management and scene management, as shown in the figure below.
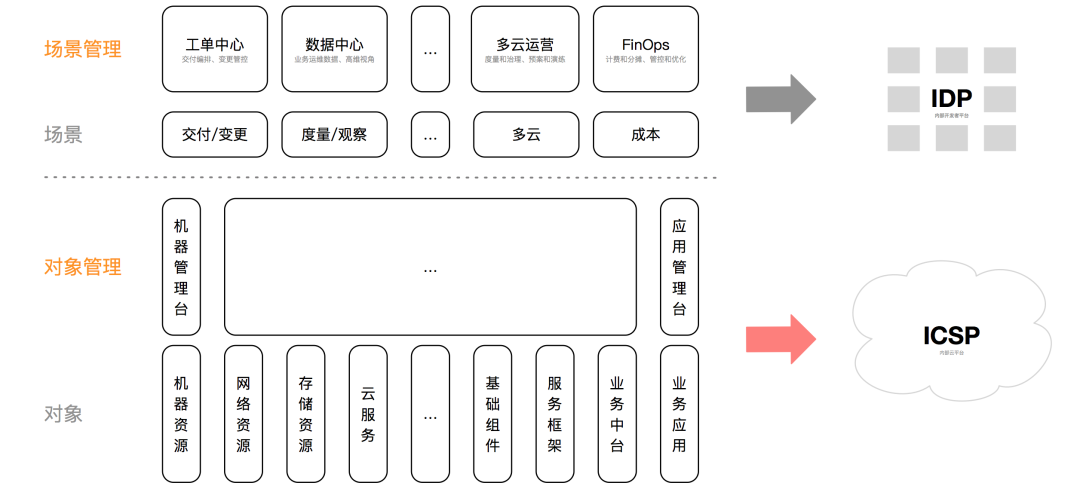
Object management is a vertical model that revolves around operating and maintaining objects and building a life cycle management platform. Operation and maintenance objects can be classified according to IaaS resources (machine, network, storage, cloud services), PaaS components (database, cache, MQ, gateway), SaaS applications (business middle platform, business applications), service framework (runtime, Code framework, name service) and other dimensions, the classification granularity of different companies is different. Each type of object has an independent management platform (chimney). The functions of the management platform should cover the complete life cycle of the operation and maintenance object. The key stages include modeling (metadata), delivery/change, monitoring/measurement, offline, etc., which is different from the public Cloud management functions are similar. The goal of object management is to produce vertically complete cloud products and build an internal cloud platform ICSP.
Scenario management is a horizontal mode that manages the life cycle stages of various operation and maintenance objects according to operation and maintenance scenarios. The classification of operation and maintenance scenarios, including delivery/change, monitoring/measurement, multi-cloud, cost, etc., is very close to the working habits of business research and development, covers a few high-frequency scenarios, and is similar in different companies. Each type of operation and maintenance scenario has an independent scenario management platform, such as work order center, data center, FinOps platform, etc. Scenario management is based on object management. The scenario management platform manages operation and maintenance objects by unifying models, aggregating data, orchestrating management and control APIs, etc. The goal of scene management is to provide self-service business management capabilities and build an internal developer platform IDP.
Common ways to generate operation and maintenance objects include self-research, open source construction, external procurement (public cloud), etc. Each operation and maintenance object can be further subdivided into different categories, clusters, instances, etc., with unprecedented scale and complexity. Only by maintaining the isomorphism of the management characteristics of operation and maintenance objects can we build and maintain operation and maintenance services on a large scale and at low cost, thereby realizing large-scale operation and maintenance (technical leverage effect). Therefore, the isomorphism of operation and maintenance objects is the basis of the entire operation and maintenance architecture. premise.
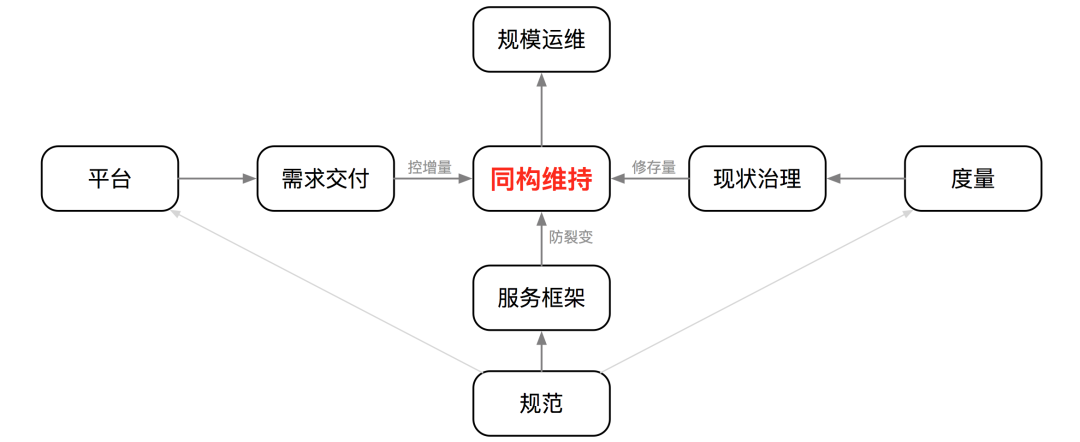
Isomorphic maintenance
Isomorphic maintenance is aimed at the management characteristics of operation and maintenance objects, not all characteristics. The method of maintaining isomorphism is: controlling increment, repairing inventory, and preventing fission. As shown in the figure below, the platform is used to deliver demand and control increments, to drive governance through measurement to repair inventory, and to prevent large-scale fission of the technical system through standardized service frameworks; platforms and metrics strictly follow specifications, and specifications also require metrics or platforms. input of questions to improve, the three complement each other. Specifications are divided into service specifications (corresponding to service governance), management specifications (corresponding to operation and maintenance control) and other types.
Isomorphism is maintained and relies on an organizational division of labor with clear responsibilities. For example, operation and maintenance focuses on management, stripping off business tools and returning them to business R&D, such as status quo governance, alarm response, and CD; business R&D focuses on business implementation, stripping off the non-business logic of the service framework and handing it over to the infrastructure. Implementation, such as service discovery and traffic control; the infrastructure focuses on middle-end capabilities such as service framework, stripping away management functions and handing them over to operation and maintenance, such as demand delivery, change control, etc. The influence of culture cannot be ignored. Operations and architecture will output concepts and cultivate user habits through communication and guidance, such as not providing SLA commitments for personalized needs and providing out-of-the-box observation capabilities for standard applications.
Based on the isomorphic maintenance of operation and maintenance objects, and upward support for the operation and maintenance service-oriented technology system, a sustainable operation and maintenance architecture is formed, as shown in the figure below. Under the current technical level, operation and maintenance services based on self-service platforms can solve 70% of the needs, and the remaining 30% still require manual labor, such as demand communication, problem troubleshooting, result acceptance, policy compliance, etc. With the advancement of technology and concepts, it is believed that the proportion of operation and maintenance services will further increase.
Note: The service framework in this article includes not only the code framework and code library N years ago, but also the current popular microservice governance. Transition stage, naming is urgent.
Transformation Practice
Operation and Maintenance as a Service OPaS
Business operation and maintenance, also called application operation and maintenance, is the closest to cloud native and has been hardest hit. In addition to traditional cross-team responsibilities such as specification formulation, process construction, and global management, business operations and maintenance must be transformed in a service-oriented direction. The path is as follows:
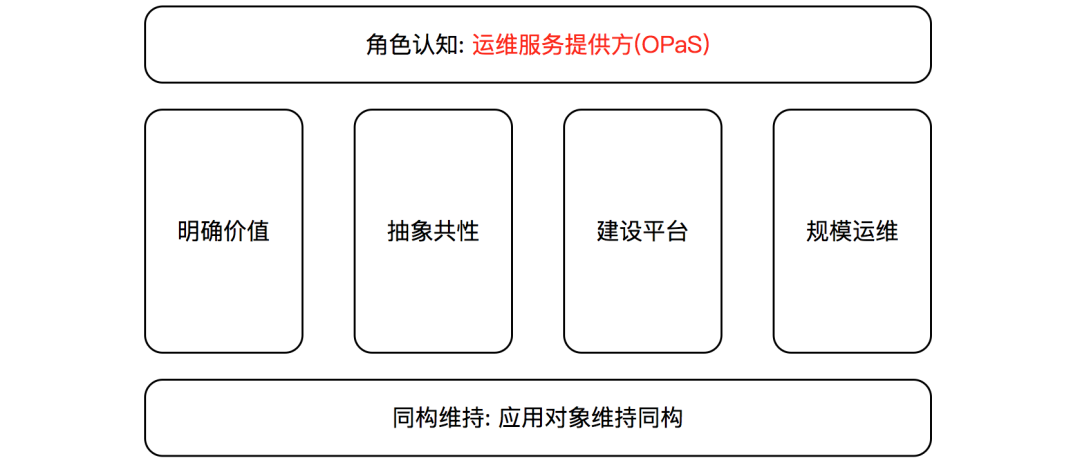
- First, role perception needs to change. Adjust yourself from an operational role that relies on business to generate value to an operation and maintenance service provider with independent value. Role change is the key
- In the organization, re-dividing the main responsibilities. Business R&D is the main party responsible for the application, and operation and maintenance is not the main responsible party for the application, nor is it a plug-in nanny, but the provider of management capabilities for the application. Business R&D uses operation and maintenance services and completes the operation work by itself
- mechanism , reconstruct the evaluation system. The performance of business operation and maintenance positions is no longer strongly tied to business teams and business research and development, but more focused on service-oriented operation and maintenance, with less emphasis on subjective evaluation and more emphasis on technical evaluation.
- Second , four steps for operation and maintenance transformation. Clarify the object--> Abstract commonality--> Build the platform--> Achieve large-scale operation and maintenance
- The object of business operation and maintenance is first the application (also called service), and then the expansion scenario of the application (Such as business perspective, company global perspective)
- Abstract commonality is the difficulty and the key point. There are a large number of applications, complex technology stacks, and many personalized features. It is necessary to abstract the common management characteristics of applications to avoid falling into personalized cases. Strictly speaking, the common characteristics of applications are the objects of operation and maintenance management
- The construction platform refers to the application management platform, and large-scale operation and maintenance is a sustainable final state
- Third, application Objects remain isomorphic. In addition to building service-oriented capabilities, the main energy of operation and maintenance personnel should be invested in isomorphic maintenance
Operation and maintenance as service OPaS (OP as Service) is our mid-term transformation, from the perspective of business operation and maintenance The proposed goals pointed out the general direction, but lacked the path and was relatively abstract; after that, OPaS was gradually refined into the operation and maintenance architecture of ICSP IDP, and its scope of application was extended to the entire operation and maintenance team, so that there was a clear path and starting point.
Hyperservice Perspective (Business Operation and Maintenance)
In addition to servitization, business operation and maintenance can also lead the construction of the hyperservice perspective (now renamed as scenario). The DevOps technology puzzle under cloud native is not complete. It has only completed the application computing part, and there are gaps in capabilities in other directions, especially the upward business perspective, department perspective, company perspective, etc., let’s call it Super Service Perspective. From a hyper-service perspective, business R&D personnel usually do not have the ability or motivation to take the lead; department heads or architects can take care of their own departments, but are limited by job responsibilities and find it difficult to expand to the overall situation. On the other hand, the hyper-service perspective is the old battlefield of traditional business operation and maintenance, with unparalleled experience, understanding and cognitive advantages. Business operation and maintenance leads the construction of a hyper-service perspective, which can not only fill the gap in the cloud native field, but also give full play to the professional advantages of business operation and maintenance, and take advantage of the opportunity for transformation. It will be a win-win choice, as shown below.
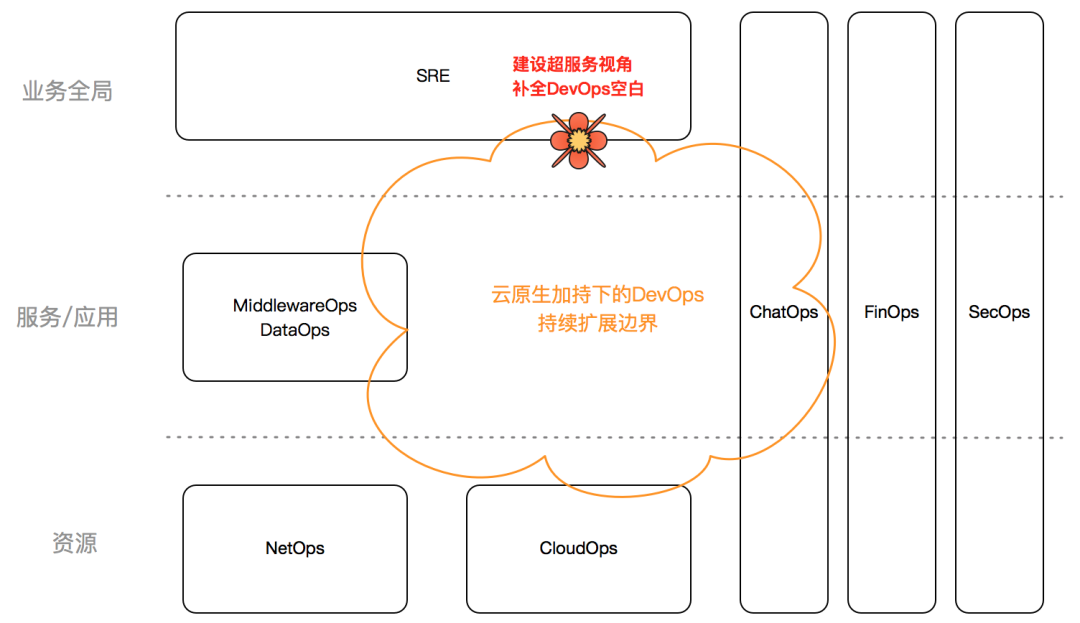
Super service perspective, including but not limited to:
- Demand delivery: work order center, orchestration engine, execution Engine
- Change control: five catch-all rules, centralized management and control, arrangement approval, execution approval, service inspection, change measurement
- Observation measurement: aggregate and display observation and measurement data from the business perspective, support drill-down Down to the application granularity
- Multi-cloud architecture: measurement, governance, planning, and drills throughout the entire technical system
- Cost control: billing, apportionment, management, control, and optimization of all the company's IT resources, independently for FinOps Direction
- Standard formulation: Formulation of operation and maintenance specifications from a company-wide perspective, supervision of process implementation, to avoid chimney-like repetitive construction of small teams
- etc.
under cloud native Looking down at the DevOps technology puzzle, there are gaps in capabilities. For example, the support for basic services such as CDN, object storage, MQ, and EMR is not perfect, and it is still in the exploratory period in 2022; from the perspective of operation and maintenance management, as long as it is covered by the service framework (Authentication, discovery, communication, perception, flow control) is radiated, even if it is managed by Cloud Native.
Onion model (cloud services, middleware, big data operation and maintenance)
Cloud services, middleware, big data and other operation and maintenance objects, the technology stack is converged and professionally focused. When implementing transformation, operation and maintenance personnel can follow the onion model.
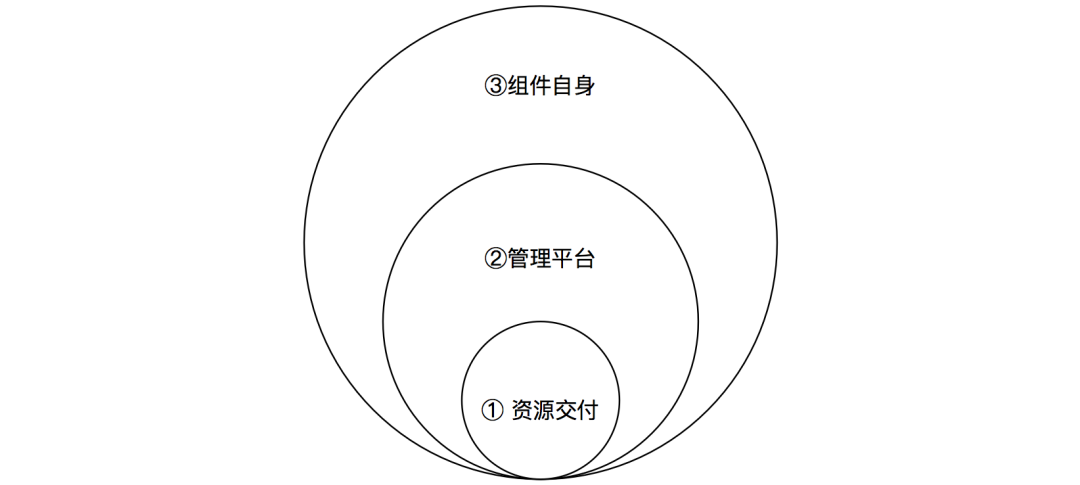
- The first stage is based on resource delivery, transforming the original operation and maintenance objects into resource entities, and ensuring delivery to the upstream service functions and establish the bottom line of job value
- In the second stage, invest a lot of energy in building a management platform to manage the life cycle of resource entities and liberate yourself. The platform must be able to self-service ToC and achieve decoupling
- The third stage is to go deep into the professional field of the component itself and improve professionalism from all aspects such as architecture, code, performance, operation and maintenance. When this step is achieved, operation and maintenance has become a service expert in this field, not just an administrator.
The onion model was first verified in database, big data, middleware and other positions, and later It was taken over and used in cloud services, and it was also successful. For example, our company's cloud service operation and maintenance CloudOps team implements transformation according to the onion model. The details are as follows.
- The objects of this team are various cloud services, distributed in Tencent, Alibaba, Baidu and other cloud vendors
- Two years ago, we provided machines, storage and other resources through various manual methods to support the rapid development of the business (resource delivery)
- After that, we Start building a multi-cloud management platform to manage the life cycle of cloud services such as machines, bandwidth, object storage, and CDN. In this process, the CloudOps management platform was successfully transformed into the company's internal secondary cloud service provider ICSP (platform capability)
- Next, we will continue to strengthen our learning, awareness, and understanding of public cloud products. Selection, evolution promotion, etc., and strive to establish more professionalism in this field (component itself)
Operation and maintenance middle platform (operation and maintenance development)
As the business operation Roles such as maintenance, component operation and maintenance, and system operation and maintenance (resource network cloud services) began to participate in development work. The space left for the operation and maintenance development DevOps team gradually became less and less, and the division of labor was unclear during the transformation process. With reference to the prediction of the upgrade of the organizational structure and technical architecture, we have re-adjusted the positioning of OpDev: OpDev should not be a development outsourcing or vassal of operation and maintenance personnel, but should have its own independent services. As a result, the original operation and maintenance platform was split into two parts. One part focused on functional iteration and could not be reused, and was left to the original users to maintain themselves, such as IDP resource console, ICSP scenario management tools, etc.; the other part was public functions. , abstracted as the operation and maintenance middle platform is responsible for OpDev, such as unified account IAM, work order orchestration engine, monitoring indicator collector, etc., as shown below.
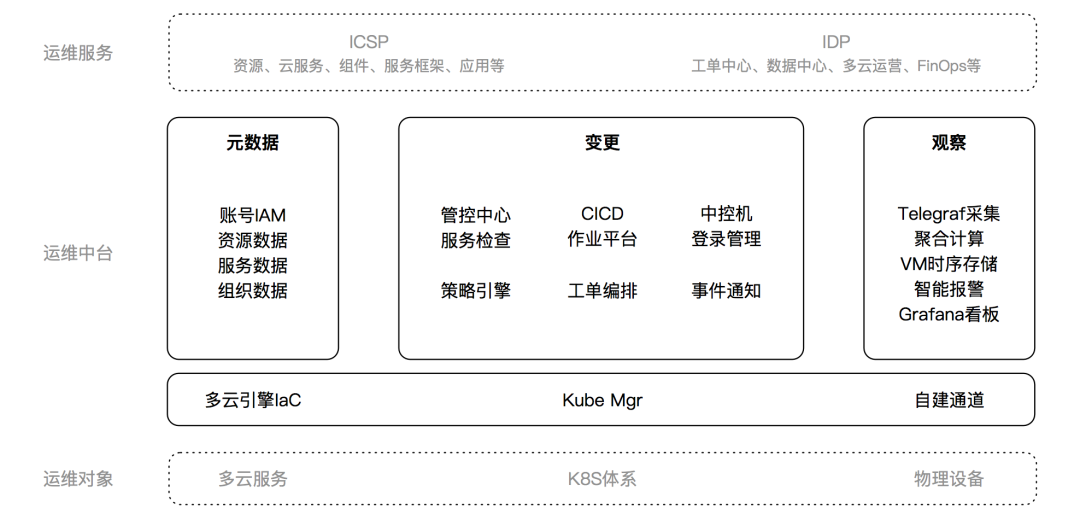
The operation and maintenance center is a subset of the original operation and maintenance platform. It does not need to rebuild domain knowledge. It needs to re-do domain abstract modeling and has relatively high requirements for code quality (same as basic components). This is exactly what OpDev is for children. ’s strengths. As responsibilities are centralized and reduced, OpDev must simultaneously slim down and achieve higher leverage.
Some lessons
Briefly share some of our company’s transformation lessons, including
- There is a compromise between transformation and conservatism. The transformation from traditional operation and maintenance to a service provider will not happen overnight, nor will all employees migrate. There will always be someone who stays behind (the current technical level is about 73%). After resources are concentrated, the back-end personnel will receive more value returns
- Gradient of R&D capability differentiation. The capabilities of children's shoes in the transformation from operation and maintenance to development are uneven. It must start from the iteration of business needs, strictly control the design and acceptance to ensure quality, consciously complement the engineering theory, and be equipped with excellent operation and maintenance middle-end capabilities to ensure A clean underlying
- platform is not the only option. Platform is the most powerful way to undertake service capabilities, but it is definitely not the only way. Organization, culture, norms, processes, and platforms are all indispensable (but the transfer cost may be slightly higher)
- Clear the objects of operation and maintenance management. Operation and maintenance, especially application operation and maintenance, the management object is not the application itself, but the common characteristics of the application; the more common characteristics of the application, the greater the value of application operation and maintenance (leverage)
- Organizational guarantee cannot be ignored . The organizational structure is the primary productive force. The CTO must make a difference, have clear goals, and have a clear division of labor, such as clarifying main responsibilities, setting up independent acceptance agencies, measurement and governance cycles, etc. This is the organizational guarantee for operation and maintenance transformation
- vigilance Pure project thinking. Operations and maintenance still need to participate in some projects to explode value and gain a sense of accomplishment in the short term, but it is also easy for people to lose their temper and the value to zero; it requires conscious design goals and accumulation of service capabilities during the project process
- Prevention is more effective than emergency response. Stability issues need to be solved in the architectural field, and prevention is more effective than emergency response. Prioritize extending MTBF, followed by shortening MTTR
The following is additional content, not the core of this article.
The evolution of demand delivery
Whether it is a public cloud or an internal K8S platform, there are a large number of demand delivery operations. This type of ToM (ToManager) delivery platform often lacks necessary constraints and can only be open to experienced people.
In order to optimize the division of labor and improve efficiency, the operation and maintenance management plane ToC (ToRD) can be implemented through "work order arrangement and approval"; the workflow/work order itself will be heavily integrated into the best practices of operation and maintenance management. , can be safely opened to research and development. This is an important direction for the servitization of operation and maintenance capabilities. The evolution path of self-service delivery is as follows:
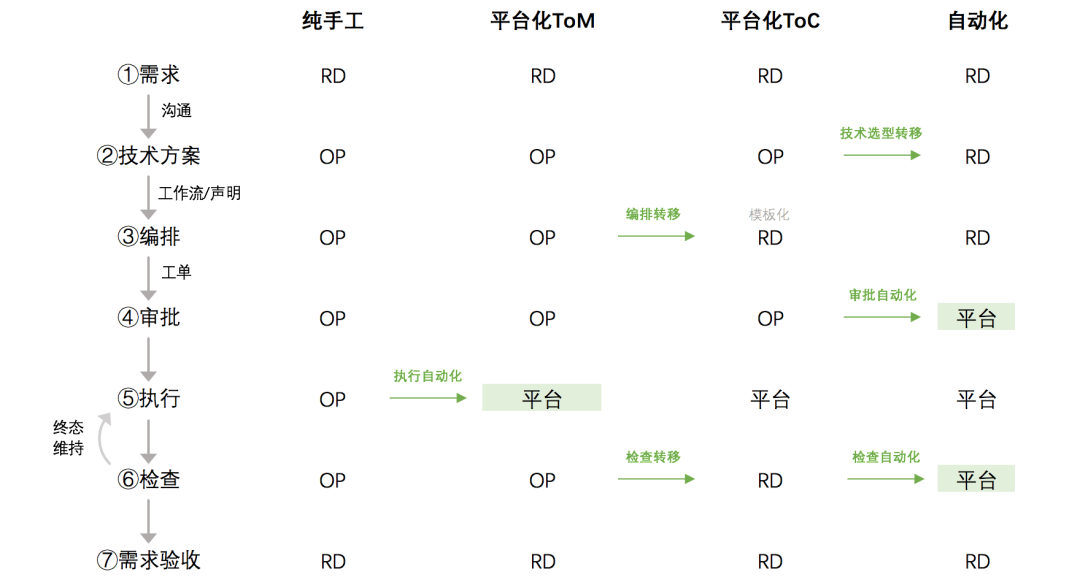
Currently, the communication link from requirements to technical solutions is relatively difficult to self-service or automate. More attempts are needed in the future.
Marginal Point of Scale Operation and Maintenance
The essence of economics of scale operation and maintenance is marginal cost, which is the interaction of "diminishing marginal cost of operation and maintenance management vs. increasing marginal cost of isomorphic maintenance". As shown in the figure below, when the number of operation and maintenance objects is small, the cost of operation and maintenance management accounts for the majority, such as building platforms and manual operations; when the number of operation and maintenance objects increases, isomorphic maintenance constitutes the main cost; the marginal turning point will be affected by technology and concepts and other environmental factors.
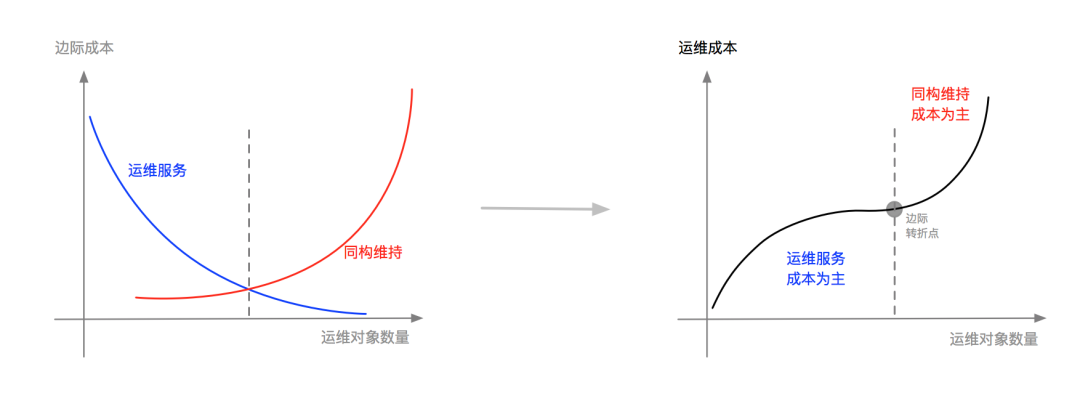
Cloud native technology reduces the difficulty of maintaining isomorphism (promoting the isomorphism maintenance curve to shift to the right) and improves operation and maintenance service capabilities (promoting the The operation and maintenance management curve shifts downward), allowing operation and maintenance personnel to manage more operation and maintenance objects at a lower cost, thus significantly improving production efficiency.
The above is the detailed content of Zuoyebang Nie An: How to transform operation and maintenance, listen to Zuoyebang's OPaS ideas. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Having worked in operation and maintenance for more than ten years, there have been countless moments when I felt like I was still a novice...
Jun 09, 2023 pm 09:53 PM
Having worked in operation and maintenance for more than ten years, there have been countless moments when I felt like I was still a novice...
Jun 09, 2023 pm 09:53 PM
Once upon a time, when I was a fresh graduate majoring in computer science, I browsed many job postings on recruitment websites. I was confused by the dazzling technical positions: R&D engineer, operation and maintenance engineer, test engineer... During college, my professional courses were so-so, not to mention having any technical vision, and I had no clear ideas about which technical direction to pursue. Until a senior student said to me: "Do operation and maintenance. You don't have to write code every day to do operation and maintenance. You just need to be able to play Liunx! It's much easier than doing development!" I chose to believe... I have been in the industry for more than ten years , I have suffered a lot, shouldered a lot of blame, killed servers, and experienced department layoffs. If someone tells me now that operation and maintenance is easier than development, then I will
 Spring Boot Actuator Endpoint Revealed: Easily Monitor Your Application
Jun 09, 2023 pm 10:56 PM
Spring Boot Actuator Endpoint Revealed: Easily Monitor Your Application
Jun 09, 2023 pm 10:56 PM
1. Introduction to SpringBootActuator endpoint 1.1 What is Actuator endpoint SpringBootActuator is a sub-project used to monitor and manage SpringBoot applications. It provides a series of built-in endpoints (Endpoints) that can be used to view the status, operation status and operation indicators of the application. Actuator endpoints can be exposed to external systems in HTTP, JMX or other forms to facilitate operation and maintenance personnel to monitor, diagnose and manage applications. 1.2 The role and function of the endpoint The Actuator endpoint is mainly used to implement the following functions: providing health check of the application, including database connection, caching,
 Spring Cloud microservice architecture deployment and operation
Jun 23, 2023 am 08:19 AM
Spring Cloud microservice architecture deployment and operation
Jun 23, 2023 am 08:19 AM
With the rapid development of the Internet, the complexity of enterprise-level applications is increasing day by day. In response to this situation, the microservice architecture came into being. With its modularity, independent deployment, and high scalability, it has become the first choice for enterprise-level application development today. As an excellent microservice architecture, Spring Cloud has shown great advantages in practical applications. This article will introduce the deployment and operation and maintenance of SpringCloud microservice architecture. 1. Deploy SpringCloud microservice architecture SpringCloud
 What capabilities should PG database operation and maintenance tools cover?
Jun 08, 2023 pm 06:56 PM
What capabilities should PG database operation and maintenance tools cover?
Jun 08, 2023 pm 06:56 PM
Before the holidays, I collaborated with the PG China community to conduct an online live broadcast on how to use D-SMART to operate and maintain the PG database. It happened that one of my clients in the financial industry listened to my introduction and called over to chat. They are selecting database Xinchuang and have tried several domestic databases. Finally, they are going to choose TDSQL. I felt a little surprised at the time. They had been selecting domestic databases since 2020, but it seemed that the initial experience after using TDSQL was not very good. Later, after communication, I learned that they had just started using TDSQL's distributed database and found that the research and development requirements were too high, so they all chose TDSQL's centralized MYSQL instance. After using it, they found that it was very easy to use. The entire database cloud
 What is observability? Everything a beginner needs to know
Jun 08, 2023 pm 02:42 PM
What is observability? Everything a beginner needs to know
Jun 08, 2023 pm 02:42 PM
The term observability originates from the engineering field and has become increasingly popular in the software development field in recent years. Simply put, observability is the ability to understand the internal state of a system based on external outputs. IBM defines observability as: Generally, observability refers to the degree to which the internal state or condition of a complex system can be understood based on knowledge of its external output. The more observable the system is, the faster and more accurate the process of locating the root cause of a performance issue can be without the need for additional testing or coding. In cloud computing, observability also refers to software tools and practices that aggregate, correlate, and analyze data from distributed application systems and the infrastructure that supports their operation in order to more effectively monitor, troubleshoot, and debug application systems. , thereby achieving customer experience optimization and service level agreement
 Tuyou Zou Yi: How to operate and maintain small and medium-sized companies?
Jun 09, 2023 pm 01:56 PM
Tuyou Zou Yi: How to operate and maintain small and medium-sized companies?
Jun 09, 2023 pm 01:56 PM
Through interviews and submissions, veterans in the field of operation and maintenance are invited to provide profound insights and collide together, with a view to forming some advanced consensus and promoting the industry to move forward better. In this issue, we invite Zou Yi, the operation and maintenance director of Tuyou Games. Mr. Zou often jokingly calls himself the operation and maintenance representative of the world's top 5 million companies. It can be seen that in his heart, he feels that the operation and maintenance construction ideas of small and medium-sized companies are different from those of large enterprises. There are differences. Today we have a few questions and ask Mr. Zou to share his journey of integrating research and operations for small and medium-sized companies. This is the 6th issue of the down-to-earth and high-level "Operation and Maintenance Forum", starting now! Question Preview Tuyou is a game company. What do you think are the unique features of game operation and maintenance? What are the biggest operational challenges you face? How did you solve these challenges? Game operation and maintenance people
 Do you need to learn golang for operation and maintenance?
Jul 17, 2023 pm 01:27 PM
Do you need to learn golang for operation and maintenance?
Jul 17, 2023 pm 01:27 PM
Don’t learn golang for operation and maintenance. The reasons are: 1. Golang is mainly used to develop applications with high performance and concurrent performance requirements; 2. The tools and scripting languages commonly used by operation and maintenance engineers can already meet most management and Maintenance requirements; 3. Learning golang requires a certain programming foundation and experience; 4. The main goal of the operation and maintenance engineer is to ensure the stability and high availability of the system, not to develop applications.
 Du Xiaoman and Chen Cunli: 20-year-old 'commander' talks about operation and maintenance, performance and growth
Jun 09, 2023 am 09:56 AM
Du Xiaoman and Chen Cunli: 20-year-old 'commander' talks about operation and maintenance, performance and growth
Jun 09, 2023 am 09:56 AM
Through interviews and submissions, veterans in the field of operation and maintenance are invited to provide profound insights and collide together, with a view to forming some advanced consensus and promoting the industry to move forward better. In this issue, we invite Chen Cunli, general manager of Du Xiaoman System Operation and Maintenance Department. He has spent most of his 20-year career in the Internet field. During his time in the Baidu Operations and Maintenance Department, his team members called him "Commander Chen" due to his excellent leadership style. Today we invite "Commander Chen" to talk about his views. This is the 5th issue of the down-to-earth and high-level "Operation and Maintenance Forum", starting now! Question preview: You joined Baidu very early and later became independent with Du Xiaoman. We understand that many employees around you have been following you for a long time and have experienced many business operation and maintenance tests. I believe everyone is very interested.
