

Redis cluster instance analysis

1. Why K8s
1. Resource isolation
The current Redis Cluster is deployed on a physical machine cluster. In order to To improve resource utilization and save costs, Redis clusters of multiple business lines are mixed. Because there is no CPU resource isolation, it often happens that the CPU usage of a Redis node is too high, causing other Redis cluster nodes to compete for CPU resources, causing delay jitter. Because different clusters are mixed, such problems are difficult to locate quickly and affect operation and maintenance efficiency. K8s containerized deployment can specify CPU request and CPU limit, which improves resource utilization while avoiding resource contention.
2. Automated deployment
The current deployment process of Redis Cluster on physical machines is very cumbersome. It is necessary to check the meta-information database to find machines with free resources, and many manual modifications are required. The configuration file is then deployed one by one, and finally the redis_trib tool is used to create a cluster. The initialization of a new cluster often takes an hour or two.
K8s deploys Redis clusters through StatefulSet and uses configmap to manage configuration files. It only takes a few minutes to deploy a new cluster, which greatly improves operation and maintenance efficiency.
2. How K8s
The client is unified through the VIP of LVS and forwards the service request to the Redis Cluster cluster through Redis Proxy. Here we introduce Redis Proxy to forward requests.
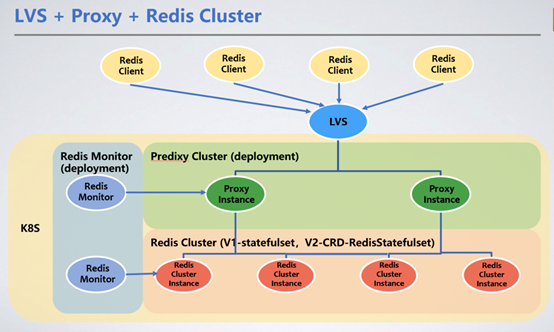
1. Redis Cluster deployment method
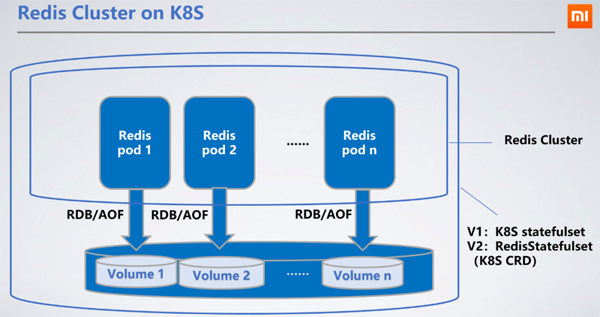
Redis is deployed as StatefulSet. As a stateful service, it is most reasonable to choose StatefulSet. Persist the node's RDB/AOF to distributed storage. When the node restarts and drifts to other machines, the original RDB/AOF can be obtained through the mounted PVC (PersistentVolumeClaim) to synchronize data.
Ceph block service is the persistent storage PV (PersistentVolume) we chose. Ceph's read and write performance is worse than that of local hard disks, which will increase read and write delays by 100 to 200 milliseconds. The read and write latency of distributed storage does not affect the service because Redis's RDB/AOF writing is asynchronous.
#2. Proxy selection
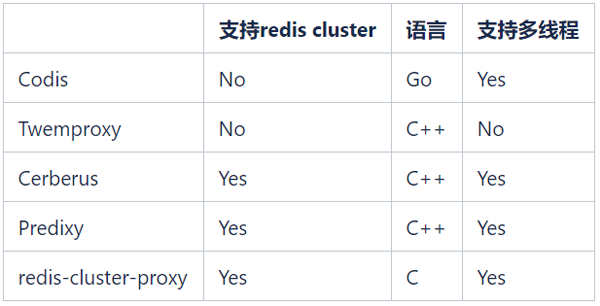
There are many open source Redis Proxy. The common open source Redis Proxy is as follows:
We hope to continue to use Redis Cluster to manage Redis clusters, so Codis and Twemproxy are no longer considered. redis-cluster-proxy is a Proxy officially launched by Redis in version 6.0 that supports the Redis Cluster protocol. However, there is currently no stable version and it cannot be applied on a large scale for the time being.
The only alternatives are Cerberus and Predixy. The following are the performance test results of Cerberus and Predixy we conducted in the K8s environment:
Test environment
Test tool: redis-benchmark
Proxy CPU: 2 core
Client CPU: 2 core
Redis Cluster: 3 master nodes, 1 CPU per node
Test results
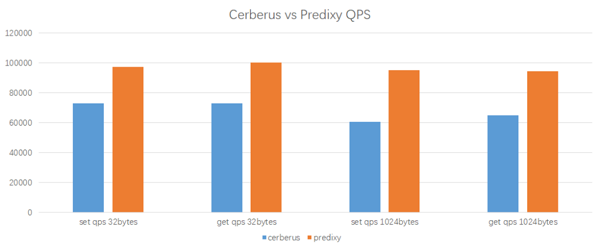
Predixy can achieve higher QPS under the same workload and configuration, and its latency is also quite close to Cerberus. Overall, Predixy has 33% to 60% higher performance than Cerberus, and the larger the key/value of the data, the more obvious the advantage of Predixy, so in the end we chose Predixy.
In order to adapt to the business and K8s environment, we made a lot of changes to Predixy before going online and added many new features, such as dynamic switching of back-end Redis Cluster, black and white lists, abnormal operation auditing, etc.
3. Proxy deployment method
Due to its stateless and lightweight deployment characteristics, proxy (Proxy) is used as the deployment method to provide services through load balancing (LB) , can easily achieve dynamic expansion and contraction. At the same time, we have developed the function of dynamically switching back-end Redis Cluster for Proxy, which can add and switch Redis Cluster online.
4. Proxy automatic expansion and contraction method
We use K8s’ native HPA (Horizontal Pod Autoscaler) to achieve dynamic expansion and contraction of Proxy. When the average CPU usage of all Proxy pods exceeds a certain threshold, expansion will be automatically triggered. HPA will increase the Proxy's replica number by 1. After that, LVS will detect the new Proxy pod and cut off part of the traffic. When the CPU usage exceeds the specified threshold, the capacity will be expanded. If the CPU usage still does not meet the requirements, the expansion logic will continue to be triggered. However, within 5 minutes of successful expansion, no matter how low the CPU usage drops, the shrinking logic will not be triggered, thus avoiding the impact of frequent expansion and shrinking on cluster stability.
HPA can configure the minimum (MINPODS) and maximum (MAXPODS) number of pods in the cluster. No matter how low the cluster load is, it will not be scaled down to the number of pods below MINPODS. It is recommended that customers judge their actual business conditions to determine the values of MINPODS and MAXPODS.
3. Why Proxy
1. Restarting Redis pod can cause IP changes
Redis clients that use Redis Cluster need to configure some IP and Port of the cluster to find the entrance to Redis Cluster when the client restarts. For Redis nodes deployed in physical machine clusters, even if the instance is restarted or the machine is restarted, the IP and Port can remain unchanged, and the client can still find the topology of the Redis Cluster. However, for Redis Cluster deployed on K8s, the IP will not be guaranteed to remain unchanged when the pod is restarted (even if it is restarted on the original K8s node), so when the client restarts, it may not be able to find the entrance to Redis Cluster.
By adding a Proxy between the client and Redis Cluster, the Redis Cluster information is shielded from the client. The Proxy can dynamically sense the topology changes of Redis Cluster. The client only needs to change the IP:Port of LVS. As an entry point, the request is forwarded to the Proxy, that is, the Redis Cluster cluster can be used like the stand-alone version of Redis, without the need for a Redis smart client.
2. Redis handles high connection load
Before version 6.0, Redis processed most tasks in a single thread. When the connections to Redis nodes are high, Redis needs to consume a lot of CPU resources to process these connections, resulting in increased latency. With the Proxy, a large number of connections are on the Proxy, and only a few connections are maintained between the Proxy and the Redis instance. This reduces the burden on Redis and avoids the increase in Redis latency caused by the increase in connections.
3. Cluster migration and switching require application restart
During use, as the business grows, the data volume of the Redis cluster will continue to increase. When each node When the amount of data is too high, the BGSAVE time will be greatly extended, reducing the availability of the cluster. At the same time, the increase in QPS will also lead to an increase in the CPU usage of each node. This needs to be solved by adding an expansion cluster. At present, the horizontal scalability of Redis Cluster is not very good, and the native slots migration solution is very inefficient. After adding a new node, some clients such as Lettuce will not be able to recognize the new node due to the security mechanism. In addition, the migration time is completely unpredictable, and there is no way to go back if there are problems during the migration process.
The current expansion plan for physical machine clusters is:
Create new clusters on demand;
Use synchronization tools to transfer data Synchronize from the old cluster to the new cluster;
After confirming that the data is correct, communicate with the business and restart the service to switch to the new cluster.
The whole process is cumbersome and risky, and requires the business to restart the service.
With the Proxy layer, the back-end creation, synchronization and switching clusters can be shielded from the client. After the synchronization of the new and old clusters is completed, you can send a command to the Proxy to switch the connection to the new cluster, which can achieve cluster expansion and contraction that is completely unaware of the client.
4. Data security risks
Redis implements authentication operations through AUTH. The client is directly connected to Redis, and the password still needs to be saved on the client. Using a proxy, the client only needs to access Redis through the proxy's password and does not have to know the Redis password. Proxy also restricts operations such as FLUSHDB and CONFIG SET, preventing customers from mistakenly clearing data or modifying Redis configuration, which greatly improves system security.
At the same time, Redis does not provide auditing functions. We have added a logging function for high-risk operations on the proxy server, providing audit capabilities without affecting overall performance.
4. Problems caused by Proxy
1. The delay caused by one more hop
The Proxy is between the client and the Redis instance. When the client accesses Redis data, it needs to access the Proxy first and then the Redis node. One extra hop will increase the delay. According to the test results, adding one hop will increase the delay by 0.2~0.3ms, but this is usually acceptable for businesses.
2. IP changes caused by Pod drift
On K8s, the proxy is implemented through deployment, so there is also the problem of IP changes caused by node restarts. . Our K8s LB solution can sense the IP changes of the Proxy and dynamically switch the LVS traffic to the restarted Proxy.
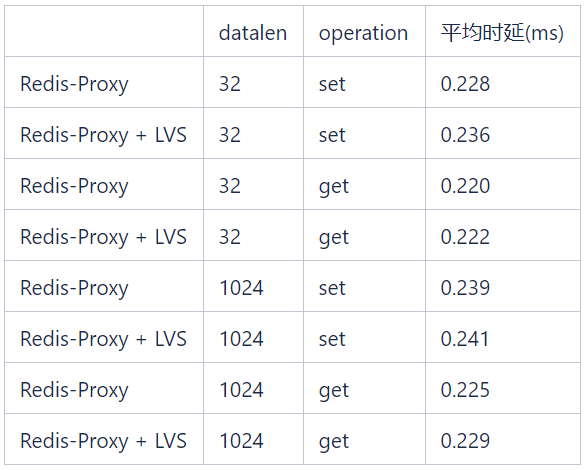
3. Latency caused by LVS
In the tests shown in the table below, the LVS latency introduced by get/set operations with different data lengths is less than 0.1 ms.
5. Benefits brought by K8s
1. Easy deployment
Calling K8s API through the operation and maintenance platform to deploy the cluster greatly improves operation and maintenance efficiency.
2. Solve the port management problem
Currently, Xiaomi’s deployment of Redis instances on physical machines is distinguished by ports, and offline ports cannot be reused, that is, Say that each Redis instance in the entire company has a unique port number. Currently, more than 40,000 of the 65,535 ports have been used. According to the current business development rate, port resources will be exhausted within two years. Through K8s deployment, the K8s pod corresponding to each Redis instance has an independent IP, and there is no problem of port exhaustion and complex management issues.
3. Lower the threshold for customer use
For applications, you only need to use the stand-alone version of the non-intelligent client to connect to the VIP, which lowers the threshold for use and avoids cumbersome and complicated parameter settings. Applications do not need to handle the Redis Cluster's topology themselves because VIPs and ports are statically fixed.
4. Improve client performance
Using non-smart clients can also reduce the load on the client, because the smart client needs to hash the key on the client to determine Which Redis node the request is sent to will consume the CPU resources of the client machine when the QPS is relatively high. Of course, in order to make client application migration easier, we also made Proxy support the smart client protocol.
5. Dynamic upgrade and expansion and contraction
Proxy supports the function of dynamically adding and switching Redis Cluster, so that the cluster upgrade and expansion switching process of Redis Cluster can be done correctly. The business end is completely unaware. For example, the business side uses a 30-node Redis Cluster. Due to the increase in business volume, the data volume and QPS have increased rapidly, and the cluster size needs to be doubled. If the capacity is expanded on the original physical machine, the following process is required:
Coordinate resources and deploy a new cluster of 60 nodes;
Manual configuration migration Tool to migrate the data of the current cluster to the new cluster;
After verifying that the data is correct, notify the business party to modify the Redis Cluster connection pool topology and restart the service.
Although Redis Cluster supports online expansion, the relocation of slots during the expansion process will have an impact on online business, and the migration time is uncontrollable, so this method is rarely used at this stage. It is only used occasionally when resources are severely insufficient.
Under the new K8s architecture, the migration process is as follows:
Create a new cluster of 60 nodes with one click through the API interface;
Also create a cluster synchronization tool with one click through the API interface to migrate data to a new cluster;
After verifying that the data is correct, send a command to the Proxy to add the new cluster information and complete the switch .
The entire process is completely unaware of the business end.
Cluster upgrade is also very convenient: if the business side can accept a certain delay glitch, it can be implemented through StatefulSet rolling upgrade during off-peak hours; if the business has requirements for delay, data can be migrated by creating a new cluster way to achieve it.
6. Improve service stability and resource utilization
Use the resource isolation function of K8s to enable mixed deployment of different types of applications. This not only improves resource utilization but also ensures service stability.
6. Problems encountered
1. Pod restart leads to data loss
K8s pod crash When the problem is restarted, because the restart speed is too fast, the pod will be restarted before the Redis Cluster cluster is discovered and switched to the master. If Redis on the pod is a slave, it will not have any impact. But if Redis is the master and there is no AOF, all the original memory data will be cleared after restarting. Redis will reload the previously stored RDB file, but the RDB file is not real-time data. Later, the slave will also synchronize its own data to the data mirror in the previous RDB file, which will cause some data loss.
When deploying a StatefulSet, the Pod name follows a certain naming format and contains a fixed number, so the StatefulSet is a stateful service. When we initialize Redis Cluster, we set adjacent numbered pods to a master-slave relationship. When restarting a pod, determine its slave through the pod name. Before restarting the pod, send the cluster failover command to the slave node to force the surviving slave node to become the master. In this way, after restarting, the node will automatically join the cluster as a slave node.
LVS mapping delay
Proxy’s pods are load balanced through LVS. There is a certain delay for LVS to take effect on the back-end IP:Port mapping. Proxy A node going offline suddenly will cause some connections to be lost. In order to minimize the impact of Proxy operation and maintenance on the business, we have added the following options to the Proxy deployment template:
lifecycle: preStop: exec: command: - sleep - "171"
For normal Proxy pod offline, such as cluster reduction, rolling update of Proxy version and others When a pod controlled by K8s goes offline, it will send a message to LVS and wait for 171 seconds before the pod goes offline. This time is enough for LVS to gradually switch the traffic of this pod to other pods without any awareness of the business.
2. K8s StatefulSet cannot meet the deployment requirements of Redis Cluster
K8s native StatefulSet cannot fully meet the requirements of Redis Cluster deployment:
In Redis Cluster , nodes with a master-standby relationship cannot be deployed on the same machine. This is easy to understand. If the machine goes down, the data shard will become unavailable.
2) Redis Cluster does not allow more than half of the master nodes in the cluster to fail, because if more than half of the master nodes fail, there will not be enough node votes to meet the requirements of the gossip protocol. Because the master and backup of Redis Cluster may be switched at any time, we cannot avoid the situation that all nodes on the same machine are master nodes, so during deployment, we cannot allow more than 1/4 of the nodes in the cluster to be deployed on the same machine. .
In order to meet the above requirements, the native StatefulSet can use the anti-affinity function to ensure that the same cluster only deploys one node on the same machine, but this machine utilization is very low.
So we developed a CRD based on StatefulSet: RedisStatefulSet, which will use a variety of strategies to deploy Redis nodes. Added some functionality for managing Redis in RedisStatefulSet. We will continue to discuss these in detail in other articles.
7. Summary
Dozens of Redis clusters have been deployed and run on K8s for more than six months. These clusters involve multiple businesses within the group. Thanks to the rapid deployment and fault migration capabilities of K8s, the operation and maintenance workload of these clusters is much lower than that of Redis clusters on physical machines, and their stability has been fully verified.
We also encountered many problems during the operation and maintenance process. Many of the functions mentioned in the article were refined based on actual needs. In the following process, many problems still need to be gradually solved to improve resource utilization efficiency and service quality.
1. Mixed deployment Vs. Independent deployment
The Redis instances of the physical machine are deployed independently. All Redis instances are deployed on a single physical machine, which is beneficial to management. , but the resource utilization rate is not high. Redis instances use CPU, memory, and network IO, but storage space is basically wasted. When a Redis instance is deployed on K8s, any other type of service may be deployed on the machine where it is located. Although this can improve the utilization of the machine, for services like Redis that have high availability and latency requirements, if Being evicted because the machine is out of memory is unacceptable. This requires operation and maintenance personnel to monitor the memory of all machines where Redis instances are deployed. Once the memory is insufficient, they will cut off the master and migrate nodes, but this will increase the workload of operation and maintenance.
If there are other high network throughput applications in the hybrid deployment, it may also have a negative impact on the Redis service. Although the anti-affinity function of K8s can selectively deploy Redis instances to machines that do not have such applications, this situation cannot be avoided when machine resources are tight.
2. Redis Cluster management
Redis Cluster is a P2P cluster architecture without a central node. It relies on gossip protocol to propagate and coordinate to automatically repair the status of the cluster. Nodes go online and offline. Network problems may cause problems with the status of some nodes in Redis Cluster. For example, nodes in failed or handshake status may appear in the cluster topology, or even split-brain. For this abnormal state, we can add more functions to Redis CRD to gradually solve it and further improve operation and maintenance efficiency.
3. Auditing and Security
Redis only provides Auth password authentication protection function and lacks permission management, so security is relatively low. Through Proxy, we can distinguish client types through passwords. Administrators and ordinary users use different passwords to log in, and the executable operation permissions are also different, so that functions such as permission management and operation auditing can be realized.
4. Support multiple Redis Clusters
Due to the limitations of gossip protocol, a single Redis Cluster has limited horizontal expansion capabilities. When the cluster size is 300 nodes, the node selection is The efficiency of class topology changes is significantly reduced. At the same time, since the capacity of a single Redis instance should not be too high, it is difficult for a single Redis Cluster to support a data scale of more than TB. Through Proxy, we can logically shard keys, so that a single Proxy can be connected to multiple Redis Clusters. From the client's perspective, it is equivalent to connecting to a Redis cluster that can support larger data scale.
The above is the detailed content of Redis cluster instance analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
