
 Database
Redis
What is the principle of Redis's common current limiting algorithm and how to implement it
Database
Redis
What is the principle of Redis's common current limiting algorithm and how to implement it
What is the principle of Redis's common current limiting algorithm and how to implement it

Introduction
Rate Limit refers to only allowing specified events to enter the system. The excess will be denied service, queued or waited for, downgraded, etc.
Common current limiting schemes are as follows:
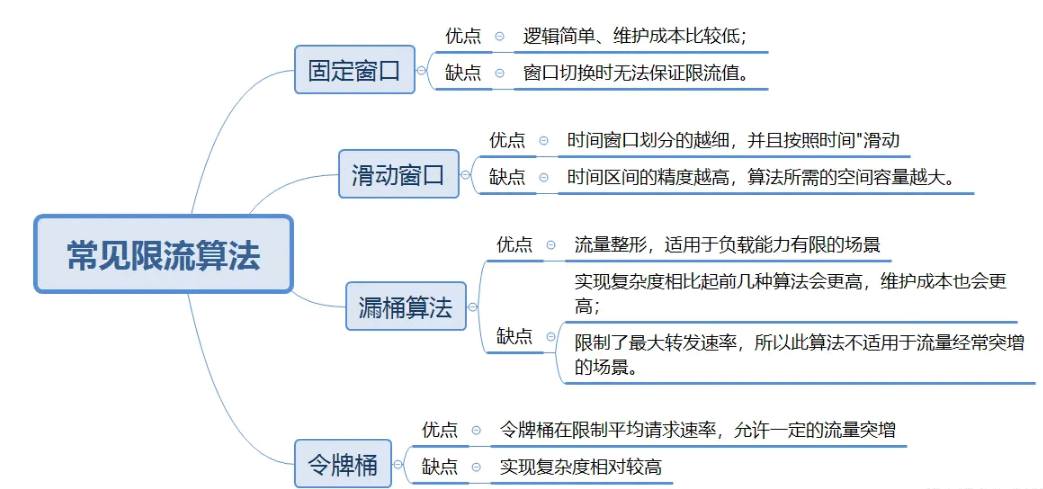
Fixed time window
Fixed time window is one of the most common current limiting algorithms one. The concept of window corresponds to the current limiting time unit in the current limiting scenario.
Principle
The timeline is divided into multiple independent and fixed-size windows;
falls within each time window For requests, the counter will be incremented by 1;
If the counter exceeds the current limiting threshold, subsequent requests falling within this window will be rejected. But when the time reaches the next time window, the counter will be reset to 0.
Example description
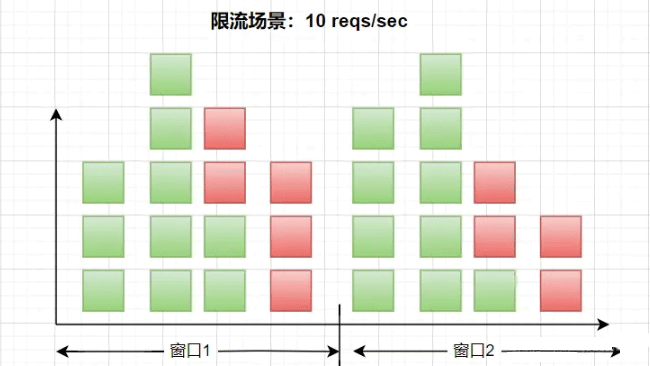
Instructions: The scenario shown above is to limit the flow to 10 times per second, and the window The size is 1 second, each square represents a request, the green square represents a normal request, and the red method represents a current-limited request. In a scenario of 10 times per second, when viewed from left to right, when entering After 10 requests, subsequent requests will be throttled.
Advantages and Disadvantages
Advantages:
- ##Simple logic and relatively low maintenance cost;
Disadvantages:
The current limit value cannot be guaranteed when switching windows. Related implementationThe specific implementation of the fixed time window can be implemented by using Redis to call the Lua current limiting script. Current limiting scriptlocal key = KEYS[1]
local count = tonumber(ARGV[1])
local time = tonumber(ARGV[2])
local current = redis.call('get', key)
if current and tonumber(current) > count then
return tonumber(current)
end
current = redis.call('incr', key)
if tonumber(current) == 1 then
redis.call('expire', key, time)
end
return tonumber(current)Copy after login
Specific implementationlocal key = KEYS[1]
local count = tonumber(ARGV[1])
local time = tonumber(ARGV[2])
local current = redis.call('get', key)
if current and tonumber(current) > count then
return tonumber(current)
end
current = redis.call('incr', key)
if tonumber(current) == 1 then
redis.call('expire', key, time)
end
return tonumber(current) public Long ratelimiter(String key ,int time,int count) throws IOException
{
Resource resource = new ClassPathResource("ratelimiter.lua");
String redisScript = IOUtils.toString(resource.getInputStream(), StandardCharsets.UTF_8);
List<String> keys = Collections.singletonList(key);
List<String> args = new ArrayList<>();
args.add(Integer.toString(count));
args.add(Integer.toString(time));
long result = redisTemplate.execute(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
Object nativeConnection = connection.getNativeConnection();
if (nativeConnection instanceof Jedis)
{
return (Long) ((Jedis) nativeConnection).eval(redisScript, keys, args);
}
return -1l;
}
});
return result;
}Copy after login
Test public Long ratelimiter(String key ,int time,int count) throws IOException
{
Resource resource = new ClassPathResource("ratelimiter.lua");
String redisScript = IOUtils.toString(resource.getInputStream(), StandardCharsets.UTF_8);
List<String> keys = Collections.singletonList(key);
List<String> args = new ArrayList<>();
args.add(Integer.toString(count));
args.add(Integer.toString(time));
long result = redisTemplate.execute(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
Object nativeConnection = connection.getNativeConnection();
if (nativeConnection instanceof Jedis)
{
return (Long) ((Jedis) nativeConnection).eval(redisScript, keys, args);
}
return -1l;
}
});
return result;
} @RequestMapping(value = "/RateLimiter", method = RequestMethod.GET)
public String RateLimiter() throws IOException
{
int time=3;
int count=1;
String key="redis:ratelimiter";
Long number=redisLockUtil.ratelimiter(key, time, count);
logger.info("count:{}",number);
Map<String, Object> map =new HashMap<>();
if(number==null || number.intValue()>count)
{
map.put("code", "-1");
map.put("msg", "访问过于频繁,请稍候再试");
}else{
map.put("code", "200");
map.put("msg", "访问成功");
}
return JSON.toJSONString(map);
}Copy after login
@RequestMapping(value = "/RateLimiter", method = RequestMethod.GET)
public String RateLimiter() throws IOException
{
int time=3;
int count=1;
String key="redis:ratelimiter";
Long number=redisLockUtil.ratelimiter(key, time, count);
logger.info("count:{}",number);
Map<String, Object> map =new HashMap<>();
if(number==null || number.intValue()>count)
{
map.put("code", "-1");
map.put("msg", "访问过于频繁,请稍候再试");
}else{
map.put("code", "200");
map.put("msg", "访问成功");
}
return JSON.toJSONString(map);
}Description: The test is accessed once every 3 seconds. If the number is exceeded, an error will be prompted.
Sliding time windowThe sliding time window algorithm is an improvement on the fixed time window algorithm. In the sliding window algorithm, it is also necessary to dynamically query the window for the current request. But every element in the window is a child window. The concept of a sub-window is similar to the fixed window in Solution 1, and the size of the sub-window can be dynamically adjusted. Implementation principle- Divide the unit time into multiple intervals, usually evenly divided into multiple small time periods;
- There is a counter in each interval. If a request falls within the interval, the counter in the interval will be incremented by one;
- Every time period passes , the time window will slide one space to the right, discard the oldest interval, and include the new interval;
- When calculating the total number of requests in the entire time window, all the requests will be accumulated If the total number of counters in the time segment exceeds the limit, all requests in this window will be discarded.
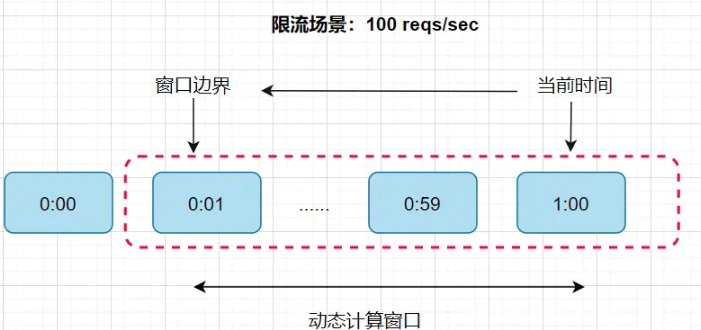
Instructions: For example, the scenario in the picture above is to limit the flow to 100 times per minute. . The time dimension of each sub-window is set to 1 second, so a one-minute window has 60 sub-windows. In this way, every time a request comes, when we dynamically calculate this window, we need to find it up to 60 times. The time complexity has changed from linear to constant level, and the time complexity will be relatively lower.
Specific implementation Regarding the implementation of the sliding time window, sentinel can be used. The use of sentinel will be explained in detail later. Leaky Bucket AlgorithmThe funnel algorithm is to fill the funnel with water first and then flow out at a fixed rate. When the amount of incoming water exceeds the outgoing water, the excess water will be discarded. When the request volume exceeds the current limiting threshold, the server queue acts like a leaky bucket. Therefore, additional requests will be denied service. The leaky bucket algorithm is implemented using queues, which can control the access speed of traffic at a fixed rate and achieve smoothing of traffic. Principle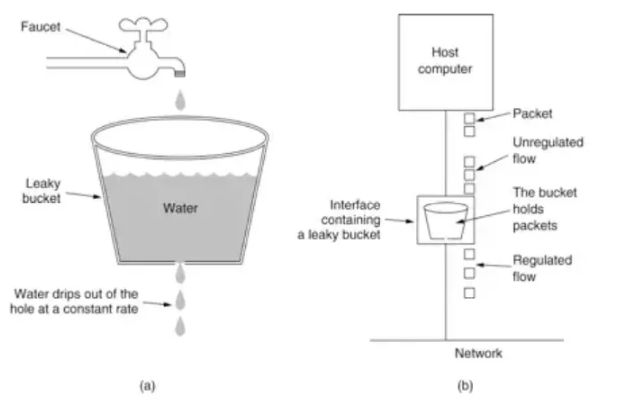
Description:
- Put each request into a fixed size The queue is in progress
- The queue outflows requests at a fixed rate, and stops flowing out if the queue is empty.
- If the queue is full, redundant requests will be rejected directly
long timeStamp = System.currentTimeMillis(); //当前时间
long capacity = 1000;// 桶的容量
long rate = 1;//水漏出的速度
long water = 100;//当前水量
public boolean leakyBucket()
{
//先执行漏水,因为rate是固定的,所以可以认为“时间间隔*rate”即为漏出的水量
long now = System.currentTimeMillis();
water = Math.max(0, water -(now-timeStamp) * rate);
timeStamp = now;
// 水还未满,加水
if (water < capacity)
{
water=water+100;
return true;
}
//水满,拒绝加水
else
{
return false;
}
}
@RequestMapping(value="/leakyBucketLimit",method = RequestMethod.GET)
public void leakyBucketLimit()
{
for(int i=0;i<20;i++) {
fixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
if(leakyBucket())
{
logger.info("thread name:"+Thread.currentThread().getName()+" "+sdf.format(new Date()));
}
else
{
logger.error("请求频繁");
}
}
});
}
}Copy after login
Token bucket algorithmThe token bucket algorithm is an improved version based on leaky bucket. In the token bucket, the token represents the upper limit of requests allowed by the current system, and the token will be put into the bucket at a uniform speed. When the bucket is full, new tokens will be discardedPrinciplelong timeStamp = System.currentTimeMillis(); //当前时间
long capacity = 1000;// 桶的容量
long rate = 1;//水漏出的速度
long water = 100;//当前水量
public boolean leakyBucket()
{
//先执行漏水,因为rate是固定的,所以可以认为“时间间隔*rate”即为漏出的水量
long now = System.currentTimeMillis();
water = Math.max(0, water -(now-timeStamp) * rate);
timeStamp = now;
// 水还未满,加水
if (water < capacity)
{
water=water+100;
return true;
}
//水满,拒绝加水
else
{
return false;
}
}
@RequestMapping(value="/leakyBucketLimit",method = RequestMethod.GET)
public void leakyBucketLimit()
{
for(int i=0;i<20;i++) {
fixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
if(leakyBucket())
{
logger.info("thread name:"+Thread.currentThread().getName()+" "+sdf.format(new Date()));
}
else
{
logger.error("请求频繁");
}
}
});
}
}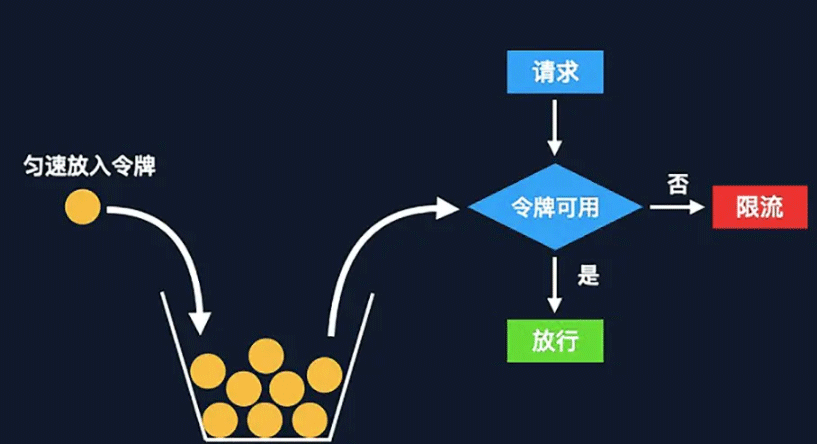
- Tokens are generated and placed at a fixed rate Into the token bucket;
如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
如果桶空了,则拒绝该请求。
具体实现
@RequestMapping(value="/ratelimit",method = RequestMethod.GET)
public void ratelimit()
{
//每1s产生0.5个令牌,也就是说接口2s只允许调用1次
RateLimiter rateLimiter=RateLimiter.create(0.5,1,TimeUnit.SECONDS);
for(int i=0;i<10;i++) {
fixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
//获取令牌最大等待10秒
if(rateLimiter.tryAcquire(1,10,TimeUnit.SECONDS))
{
logger.info("thread name:"+Thread.currentThread().getName()+" "+sdf.format(new Date()));
}
else
{
logger.error("请求频繁");
}
}
});
}
}执行结果:
-[pool-1-thread-3] ERROR 请求频繁
[pool-1-thread-2] ERROR 请求频繁
[pool-1-thread-1] INFO thread name:pool-1-thread-1 2022-08-07 15:44:00
[pool-1-thread-8] ERROR [] - 请求频繁
[pool-1-thread-9] ERROR [] - 请求频繁
[pool-1-thread-10] ERROR [] - 请求频繁
[pool-1-thread-7] INFO [] - thread name:pool-1-thread-7 2022-08-07 15:44:03
[pool-1-thread-6] INFO [] - thread name:pool-1-thread-6 2022-08-07 15:44:05
[pool-1-thread-5] INFO [] - thread name:pool-1-thread-5 2022-08-07 15:44:07
[pool-1-thread-4] INFO [] - thread name:pool-1-thread-4 2022-08-07 15:44:09
说明:接口限制为每2秒请求一次,10个线程需要20s才能处理完,但是rateLimiter.tryAcquire限制了10s内没有获取到令牌就抛出异常,所以结果中会有5个是请求频繁的。
小结
固定窗口:实现简单,适用于流量相对均匀分布,对限流准确度要求不严格的场景。
滑动窗口:适用于对准确性和性能有一定的要求场景,可以调整子窗口数量来权衡性能和准确度
漏桶:适用于流量绝对平滑的场景
令牌桶:适用于流量整体平滑的情况下,同时也可以满足一定的突发流程场景
The above is the detailed content of What is the principle of Redis's common current limiting algorithm and how to implement it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
