

What are the knowledge points about MySQL indexing and optimization?

What is index?
Index is a data structure that helps MySQL perform efficient queries. Like the table of contents of a book, it can speed up the query
The structure of the index?
The index can have B-Tree index and Hash index. The index is implemented in the storage engine
InnoDB/MyISAM only supports B-Tree index
Memory/Heap supports B-Tree index and Hash index
-
B-Tree
B-Tree is a data structure that is very suitable for disk operations. It is a multi-way balanced search tree. Its height is generally 2-4, and its non-leaf nodes and leaf nodes will store data. All its leaf nodes are on the same layer. The picture below is a B-Tree
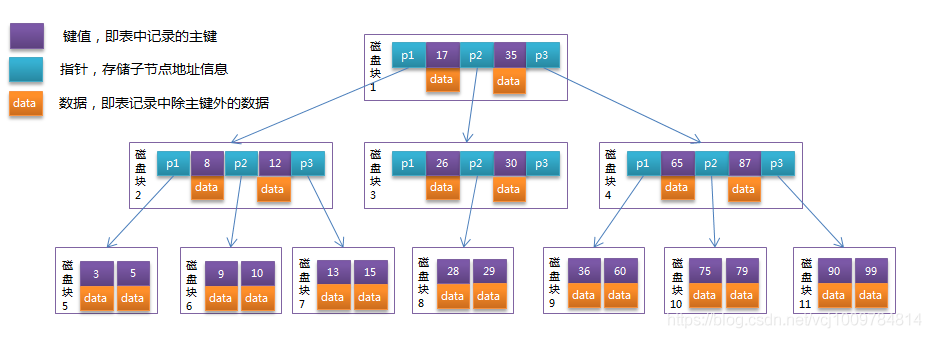
- ## B Tree: B-Tree is a type based on B-Tree optimization. The main difference between it and the B-tree is that all the data of the B-tree is stored in the leaf nodes, and the leaf nodes are strung together by a linked list. The following picture is a B-tree
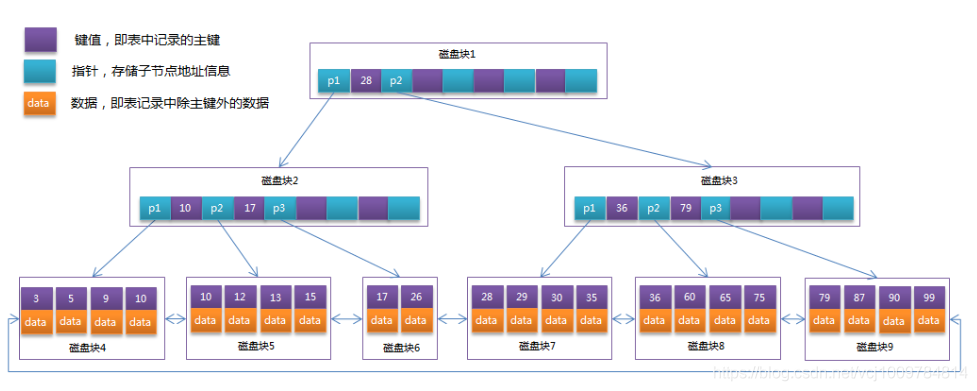
- MyISAM index
MyISAM index and data are stored separately. In the primary key index of MyISAM, the record address is stored in the leaf node of the B tree, so MyISAM needs to go through 2 IOs through the index query
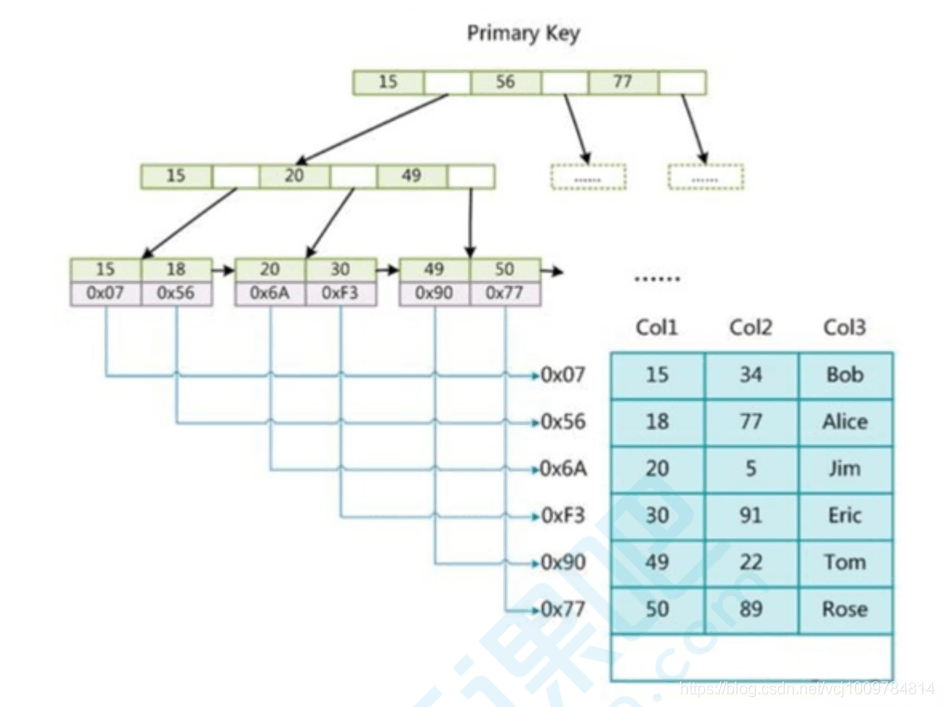
- InnoDB index
InnoDB Data and indexes are stored together, also called clustered indexes. Data is indexed by the primary key and stored on the leaf nodes of the primary key index B-tree.
InnoDB primary key index, the data is already included in the leaf nodes, that is, the index and data are stored together, which is a clustered index.
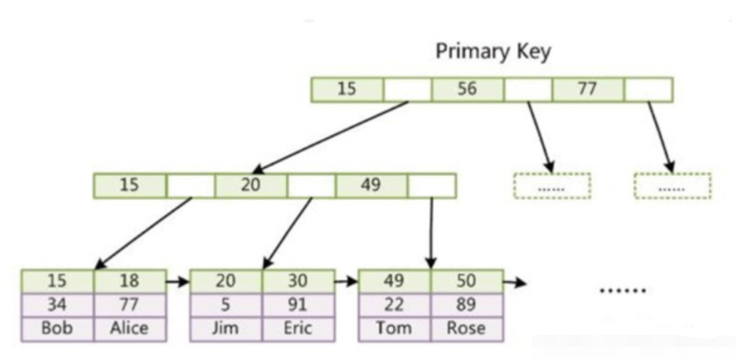
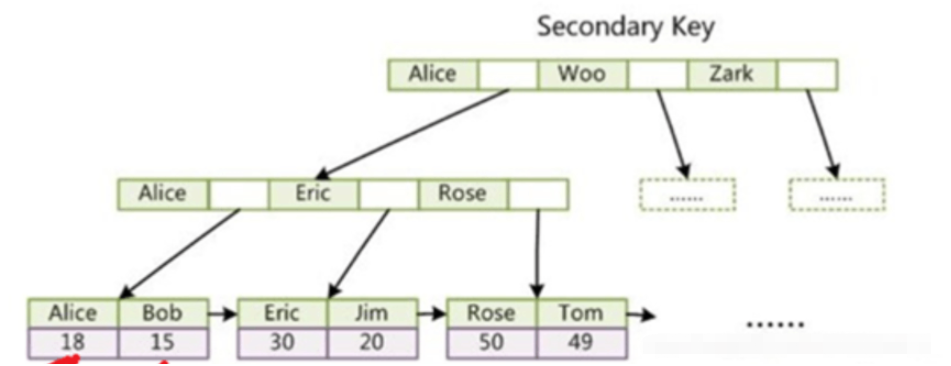
- InnoDB uses a clustered index, and its primary key index directly stores data in the leaf nodes. The leaf nodes in its auxiliary index store the value of the primary key
- MyISAM uses a non-clustered index. The data and index are not in the same file. The leaf nodes in its primary key index store The address where the row record is located, and the leaf node in the auxiliary index also stores the address where the record is located, but the key of the auxiliary index can be repeated, but the key of the primary key index cannot be repeated
Question:
Why doesn’t InnoDB use overly long fields as primary keys? A primary key that is too long will make the auxiliary index take up a lot of space
Why is it recommended that InnoDB use auto-incrementing primary keys? If you use an auto-incrementing primary key, each time a new record is inserted, the new record will be sequentially added to the subsequent position of the current index node. When one page is full, a new page will be opened, so that The index structure is very compact, and there is no need to move existing data every time it is inserted, which is very efficient. If you do not use an auto-incrementing primary key, each time you insert a new record, you have to select an insertion position, and the data may need to be moved, which makes the efficiency not high and the index structure not compact
Why use B-tree instead of B-tree
- The index itself is also relatively large and is generally stored on the disk. The index and data may be stored separately (MyISAM's non-clustered index) or they may be stored together (InnoDB's Clustered index)
- Advantages
- Reduce IO Cost, improve data query efficiency
- Reduce sorting cost (the indexed columns will be automatically sorted, using order by will improve the efficiency a lot)
- shortcoming
The index will occupy additional storage space
The index will reduce the efficiency of updating table data. When adding, deleting, or modifying operations, you must not only save the data, but also update the corresponding index
Classification of the index
Single column index
Primary key index
Unique index
Normal index
Combined index
Index uses
to create an index
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
Delete index
DROP INDEX index_name ON table_name;
Scenarios that require indexing
Frequent The columns used as query conditions need to be indexed
In multi-table association, the associated fields need to be indexed
The sorting fields in the query need to be indexed Building an index
Scenarios where indexing is not suitable
- ##A table that writes more and reads less is not suitable for indexing
- Frequently updated fields are not suitable for building indexes

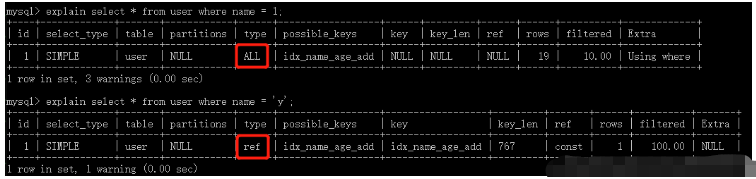
explain select * from user where name = 'am';

possible_keysPossibly used index
keyActually used index
key_lenThe length of the index used for query
refIf it is an equivalent query, it will be const
rowsEstimated number of rows to be scanned (not an exact value)
extra
- using where
indicates that the results returned by the storage engine also need to be filtered at the SQL Layer layer
- using index
indicates that there is no need to query back to the table. Generally, it will be when using a covering index. this value. Covering index means that the columns in the select are all index columns. The query that does not need to be returned to the table means that you can get the value of the index column directly by going through the auxiliary index, and there is no need to go to the primary key index to fetch records
- using index condition
MySQL 5.6.x and later supports the ICP feature (Index Condition Pushdown), which can push the check conditions to the storage engine layer. Records that do not meet the conditions will not be read directly, instead of reading them out first and then reading them as before. SQL Layer layer filtering, which reduces the number of rows scanned by the storage engine layer

- ##using filesort
- cannot be sorted Index used
- system: There is only 1 row of data in the table, or the table is empty
- const: Use a unique index or primary key index, and query with where and other values. The returned record is 1 row, also called a unique index scan

- #ref: For non-unique indexes, queries using equivalent where conditions or leftmost prefix rules.
- The following is the leftmost prefix rule that is satisfied, that is, for idx_name_age_add, the leftmost prefix is satisfied, and the first index is name

- range: Index range scan, common in >, <, between, in, like and other queries

##Note that when like, the wildcard character % cannot be placed at the beginning, otherwise it will cause a full table scan
 ##index :
##index :

 #all that does not completely match the index, but does not need to be queried back to the table : Scan the entire table, and then filter the records that meet the requirements in the SQL Layer
#all that does not completely match the index, but does not need to be queried back to the table : Scan the entire table, and then filter the records that meet the requirements in the SQL Layer
索引使用规范(索引失效分析)
全值匹配
在索引列上使用等值查询
explain select * from user where name = 'y' and age = 15;

2. 最左前缀
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age = 15;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
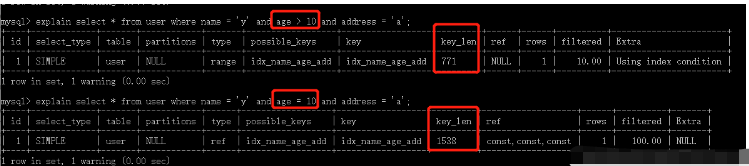
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 ),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
9. 索引字段不要用or

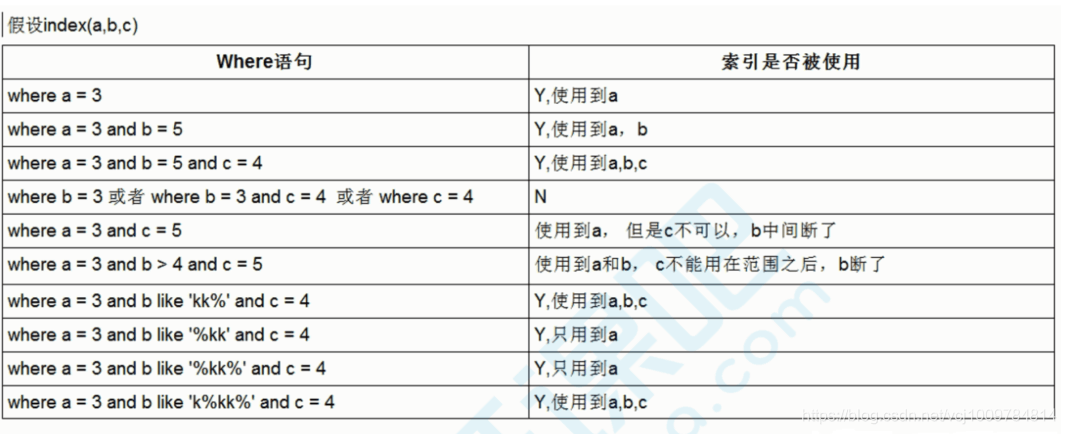
例子总结:
The above is the detailed content of What are the knowledge points about MySQL indexing and optimization?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
The process of starting MySQL in Docker consists of the following steps: Pull the MySQL image to create and start the container, set the root user password, and map the port verification connection Create the database and the user grants all permissions to the database
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 How to install mysql in centos7
Apr 14, 2025 pm 08:30 PM
How to install mysql in centos7
Apr 14, 2025 pm 08:30 PM
The key to installing MySQL elegantly is to add the official MySQL repository. The specific steps are as follows: Download the MySQL official GPG key to prevent phishing attacks. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
