
 Technology peripherals
AI
Everyone understands ChatGPT Chapter 1: ChatGPT and natural language processing
Technology peripherals
AI
Everyone understands ChatGPT Chapter 1: ChatGPT and natural language processing
Everyone understands ChatGPT Chapter 1: ChatGPT and natural language processing


ChatGPT (Chat Generative Pre-training Transformer) is an AI model that belongs to the field of Natural Language Processing (NLP). NLP is a branch of artificial intelligence. The so-called natural language refers to English, Chinese, German, etc. that people come into contact with and use in their daily lives. Natural language processing refers to allowing computers to understand and correctly operate natural language to complete tasks specified by humans. Common tasks in NLP include keyword extraction from text, text classification, machine translation, etc.
There is another very difficult task in NLP: dialogue systems, which can also be generally referred to as chatbots, which is exactly what ChatGPT accomplishes.
ChatGPT and Turing Test
Since the advent of computers in the 1950s, people have begun to study how computers can assist humans in understanding and processing natural language. This is also the development goal of the field of NLP. The most famous is undoubtedly the Turing test.
In 1950, Alan Turing, the father of computers, introduced a test to check whether a machine could think like a human. This test was called the Turing test . Its specific testing method is exactly the same as the current ChatGPT method, that is, building a computer dialogue system, where a person and the model being tested talk to each other. If the person cannot distinguish whether the other party is a machine model or another person, it means that the model has passed After passing the Turing test, the computer is intelligent.For a long time, the Turing test has been considered by academic circles to be an elusive peak. Because of this, NLP is also known as the crown jewel of artificial intelligence. The work that ChatGPT can do goes far beyond the scope of chat robots. It can write articles according to user instructions, answer technical questions, do math problems, do foreign language translation, play word games, etc. So, in a way, ChatGPT has taken the crown jewel.
ChatGPT’s modeling form
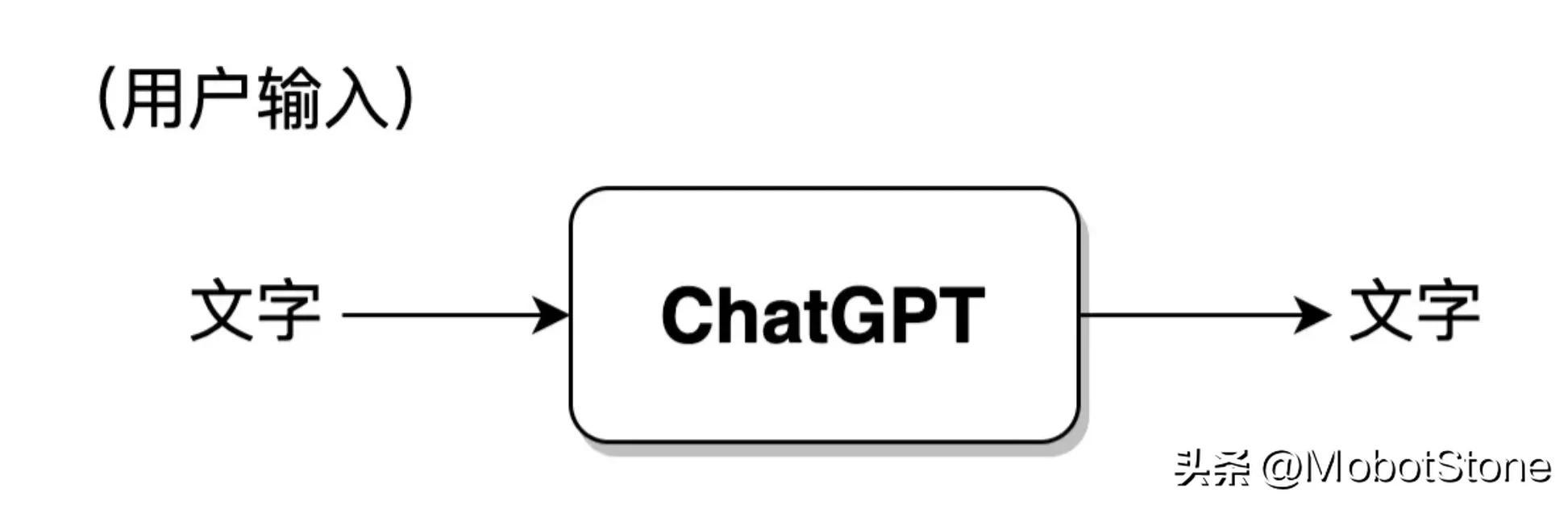
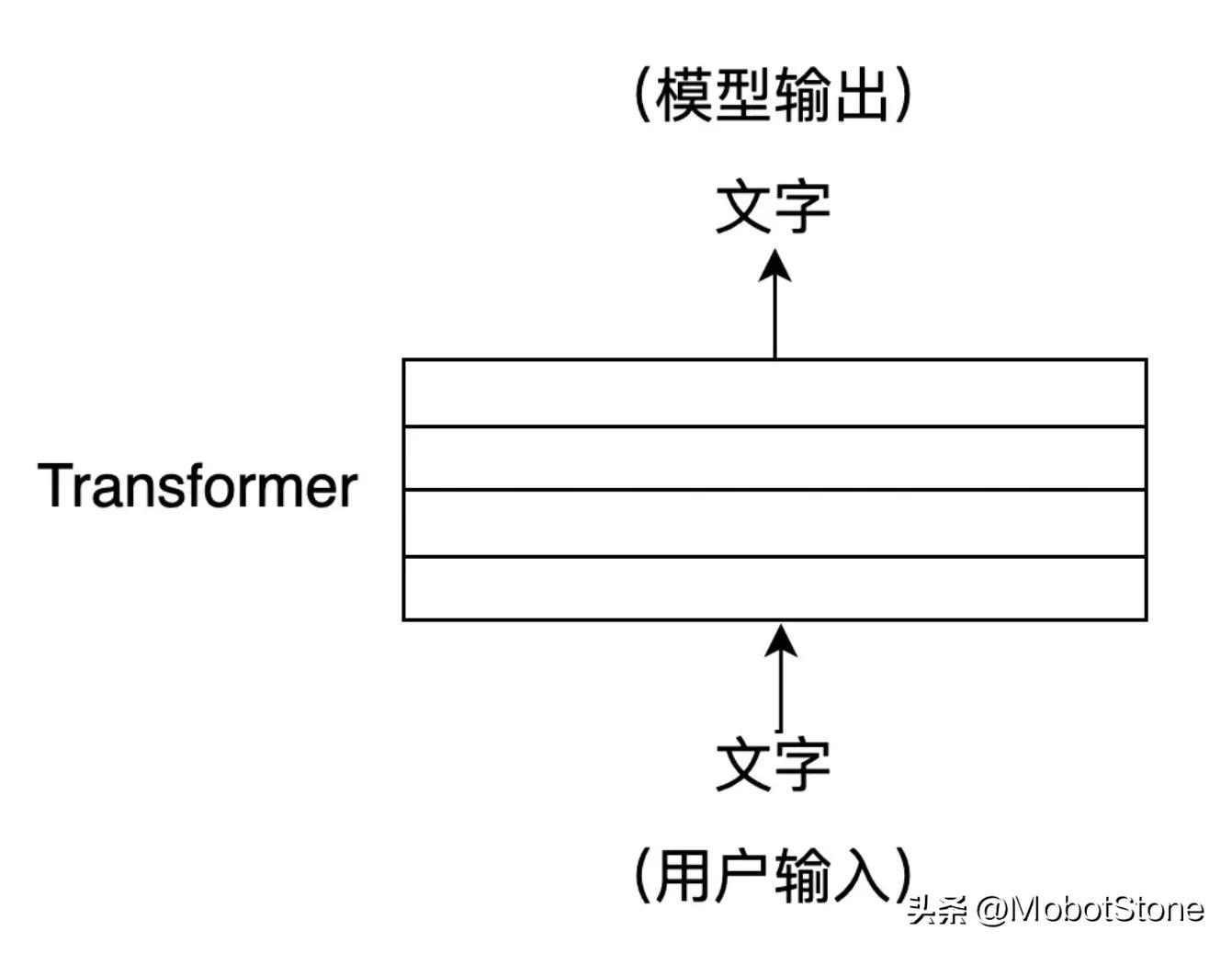
The working form of ChatGPT is very simple. If the user asks any question to ChatGPT, the model will answer it.
 Among them, the user's input and the model's output are both in the form of
Among them, the user's input and the model's output are both in the form of
. One user input and one corresponding output from the model are called a conversation. We can abstract the ChatGPT model into the following process:
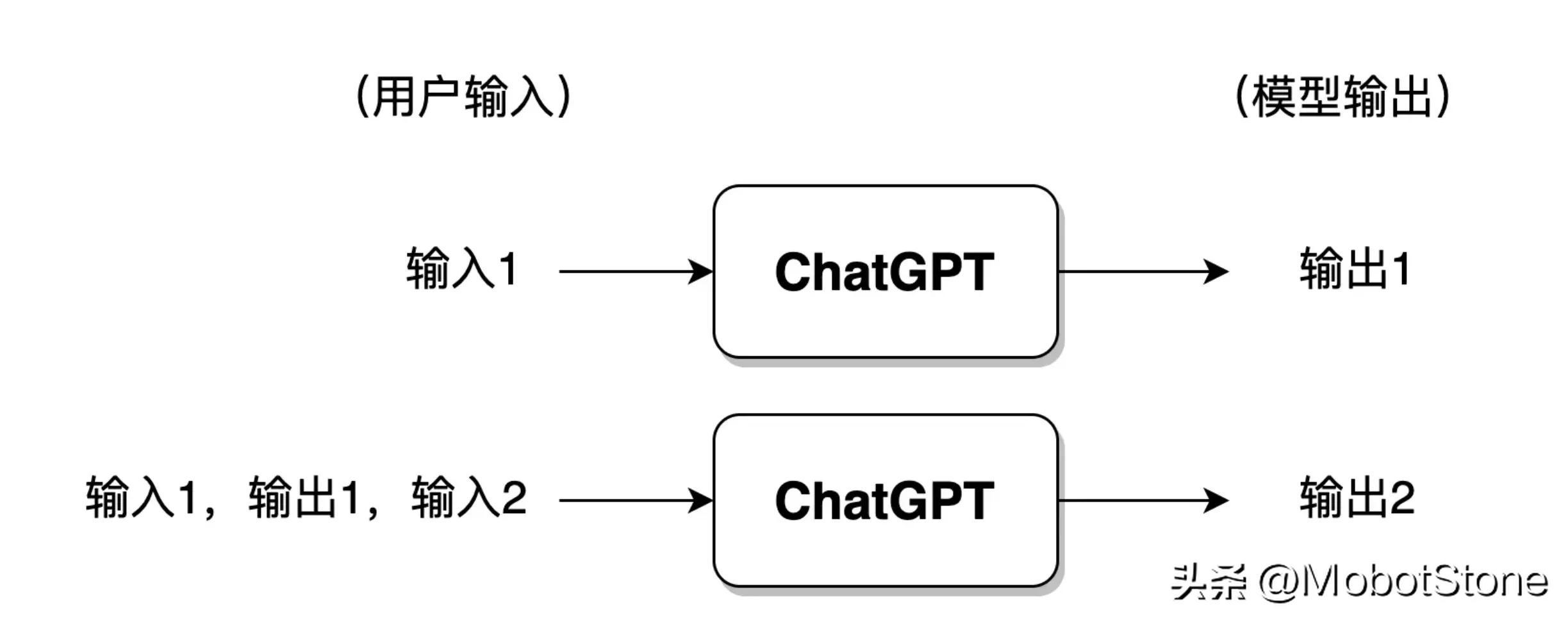
 In addition, ChatGPT can also answer continuous questions from users, that is, multiple rounds of dialogue, and there are Information related. Its specific form is also very simple. When the user inputs for the second time, the system will splice the input and output information of the first time together by default for ChatGPT to refer to the information of the last conversation.
In addition, ChatGPT can also answer continuous questions from users, that is, multiple rounds of dialogue, and there are Information related. Its specific form is also very simple. When the user inputs for the second time, the system will splice the input and output information of the first time together by default for ChatGPT to refer to the information of the last conversation.
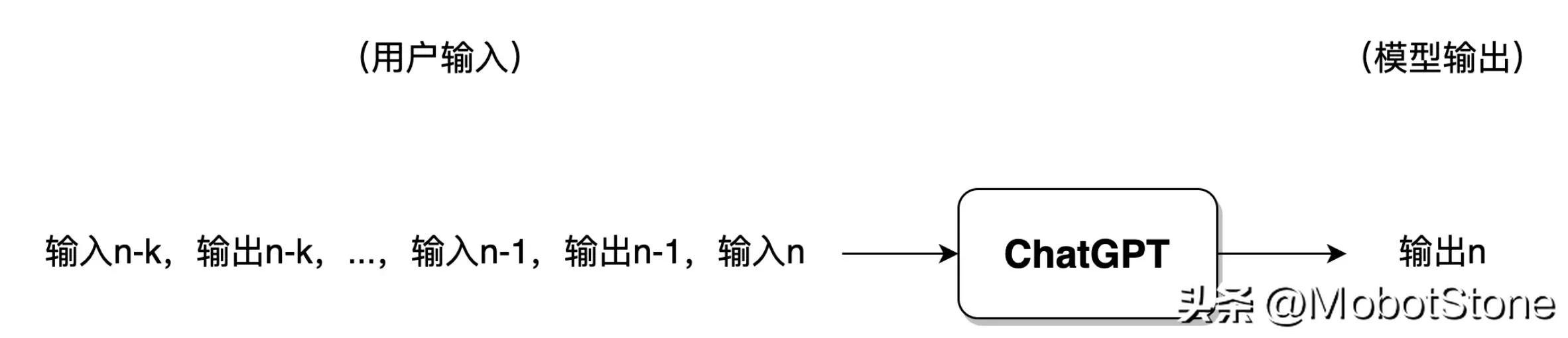
 If the user has had too many conversations with ChatGPT, generally speaking, the model will only retain information from the most recent rounds of conversations, and previous conversation information will be forgotten.
If the user has had too many conversations with ChatGPT, generally speaking, the model will only retain information from the most recent rounds of conversations, and previous conversation information will be forgotten.
 ChatGPT After receiving the user's question input, the output text is not directly generated in one go, but generated word by word. This kind of word by word Generation, that is,
ChatGPT After receiving the user's question input, the output text is not directly generated in one go, but generated word by word. This kind of word by word Generation, that is,
. As shown below.
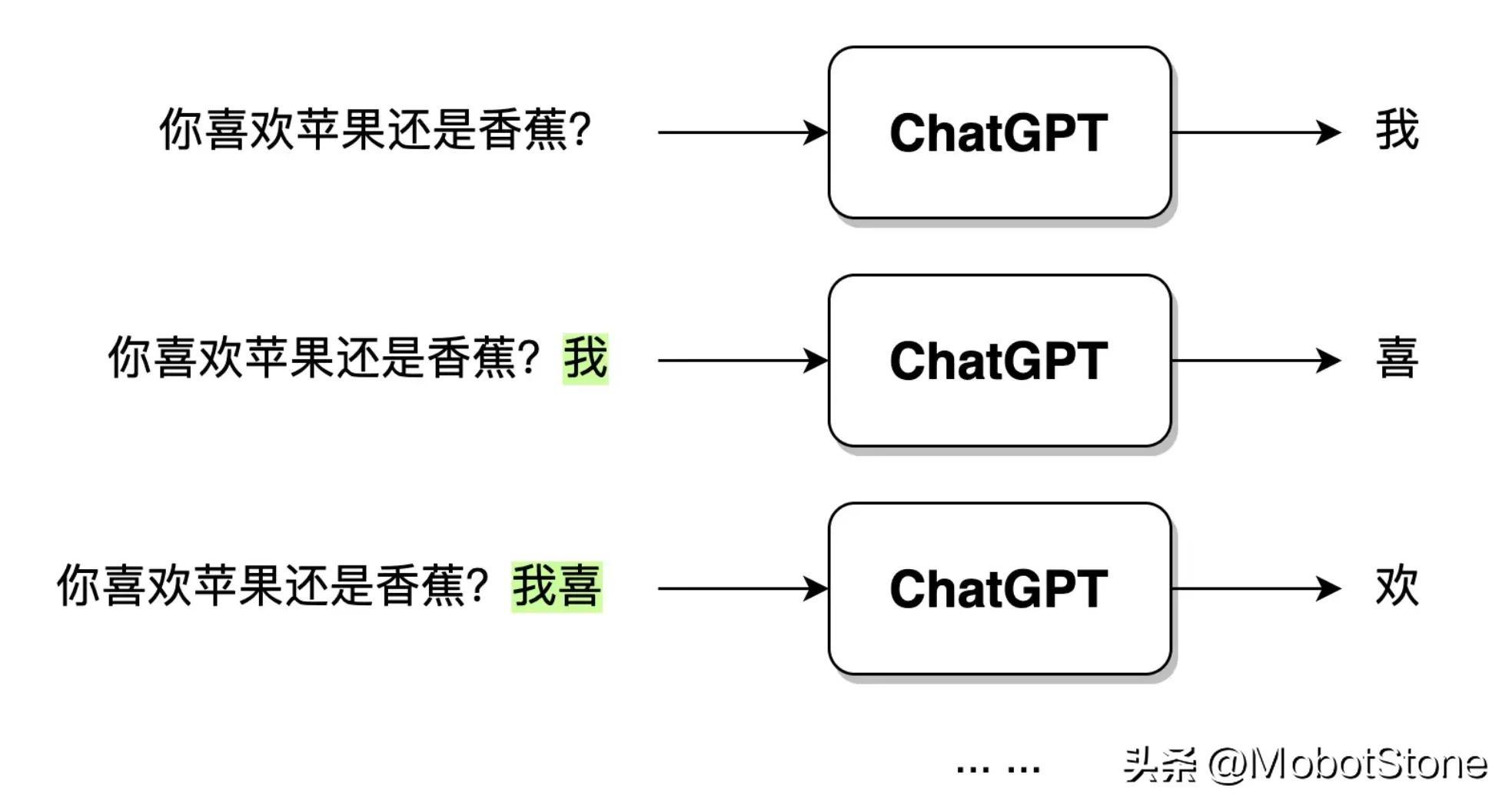 When the user enters the question: "Do you like apples or bananas?", after ChatGPT receives the data, it will first generate the word "I", and then the model will synthesize The user's question and the generated word "I" continue to generate the next word "hi". And so on until a complete sentence "I like apples" is generated.
When the user enters the question: "Do you like apples or bananas?", after ChatGPT receives the data, it will first generate the word "I", and then the model will synthesize The user's question and the generated word "I" continue to generate the next word "hi". And so on until a complete sentence "I like apples" is generated.
The development history of ChatGPT and NLP
The modeling form of ChatGPT was introduced earlier. Just imagine, if you were asked to implement a ChatGPT model, what ideas and methods would you have? In fact, there are roughly two strategies, NLP based on rules and NLP based on statistics. Since the beginning of ChatGPT, the field of NLP has entered the reinforcement learning era, that is, NLP based on reinforcement learning.
Rule-based NLP
Rule-based NLP refers to the use of manually written rules to process natural language. These rules are usually based on knowledge of grammar, semantics, and pragmatics and can be used to parse and generate natural language. For example, we can design a dialogue system based on the following rules:
Rule 1: When the model receives the user's question, remove the word "?" in the question and replace it with "?" "."
Rule 2: Replace "you" with "I" and "I" with "you"
From this, we can make according to these rules A dialogue model, the dialogue mode is turned on.
User: Hello. Model: Hello. User: Are you ChatGPT? Model: Yes, I'm ChatGPT. User: Do you like the Nuggets community? Model: I love the Nuggets community. User: Have you ever used the jionlp toolkit? Model: I have used jionlp toolkit.
The above is a very superficial example of a rule-based dialogue system. I believe readers can easily find out the problems that exist. What if the user problem is too complex? What if there is no question mark in the question? We need to constantly write various rules to cover the above special situations. This shows that there are several obvious shortcomings based on rules:
- In natural language, no rule can completely cover the requirements, so it is not effective when dealing with complex natural language tasks;
- The rules are endless, and it will be a huge amount of work to rely on human power;
- Essentially, the task of natural language processing is not handed over to the computer, it is still dominated by humans.
This is how NLP was developed in the early stages: building a model system based on rules. In the early days, it was also generally called symbolism.
Statistics-based NLP
Statistics-based NLP uses machine learning algorithms to learn regular features of natural language from a large number of corpora. It was also called connectionism in the early days. This method does not require manual writing of rules. The rules are mainly implicit in the model by learning the statistical characteristics of the language. In other words, in the rule-based method, the rules are explicit and written manually; in the statistical-based method, the rules are invisible, implicit in the model parameters, and are trained by the model based on the data.
These models have developed rapidly in recent years, and ChatGPT is one of them. In addition, there are a variety of models with different shapes and structures, but their basic principles are the same. Their processing methods are mainly as follows:
Training model=> Use the trained model to work
In ChatGPT, pre-training (Pre-training) is mainly used ) technology to complete statistics-based NLP model learning. At the earliest, pre-training in the NLP field was first introduced by the ELMO model (Embedding from Language Models), and this method was widely adopted by various deep neural network models such as ChatGPT.
Its focus is to learn a language model based on large-scale original corpus, and this model does not directly learn how to solve a specific task, but learns from grammar, morphology, pragmatics, to common sense, Knowledge and other information are integrated into the language model. Intuitively, it is more like a knowledge memory rather than applying knowledge to solve practical problems.
Pre-training has many benefits, and it has become a necessary step for almost all NLP model training. We will expand on this in subsequent chapters.
Statistics-based methods are far more popular than rule-based methods. However, its biggest disadvantage is black box uncertainty, that is, the rules are invisible and implicit in the parameters. For example, ChatGPT will also give some ambiguous and incomprehensible results. We have no way to judge from the results why the model gave such an answer.

NLP based on reinforcement learning
The ChatGPT model is based on statistics, but it also uses a new method, reinforcement learning with human feedback (Reinforcement Learning with Human Feedback, RLHF), which has achieved excellent results and brought the development of NLP into a new stage.
A few years ago, Alpha GO defeated Ke Jie. This can almost prove that if reinforcement learning is under suitable conditions, it can completely defeat humans and approach the limit of perfection. Currently, we are still in the era of weak artificial intelligence, but limited to the field of Go. Alpha GO is a strong artificial intelligence, and its core lies in reinforcement learning.
The so-called reinforcement learning is a machine learning method that aims to let the agent (agent, in NLP mainly refers to the deep neural network model, which is the ChatGPT model) learn how to make decisions through interaction with the environment. Optimal decision making.
This method is like training a dog (agent) to listen to a whistle (environment) and eat (learning goal).
A puppy will be rewarded with food when it hears its owner blow the whistle; but when the owner does not blow the whistle, the puppy can only starve. By repeatedly eating and starving, the puppy can establish corresponding conditioned reflexes, which actually completes a reinforcement learning.
In the field of NLP, the environment here is much more complex. The environment for the NLP model is not a real human language environment, but an artificially constructed language environment model. Therefore, the emphasis here is on reinforcement learning with artificial feedback.

Statistics-based methods allow the model to fit the training data set with the greatest degree of freedom; while reinforcement learning gives the model a greater degree of freedom, allowing the model to learn independently , breaking through the established data set limitations. The ChatGPT model is a fusion of statistical learning methods and reinforcement learning methods. Its model training process is shown in the figure below:
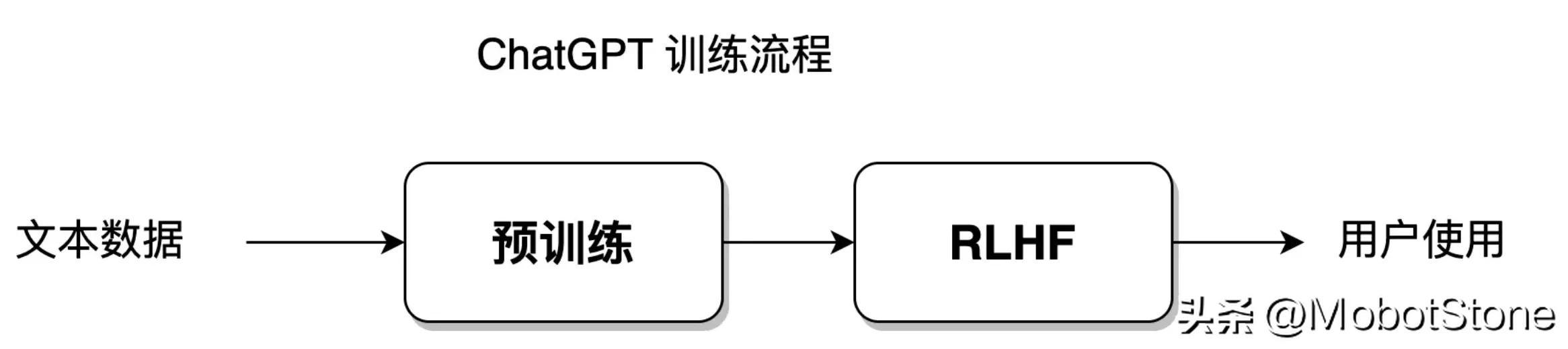
This part of the training process will be launched in Sections 8-11 speak.
The development trend of NLP technology
In fact, the three methods based on rules, based on statistics, and based on reinforcement learning are not just a means of processing natural language, but a means of processing natural language. Thought. An algorithm model that solves a certain problem is often the product of a fusion of these three solutions.
If the computer is compared to a child, natural language processing is like a human being educating the child to grow.
The rule-based approach is like a parent controlling a child 100% and requiring him to act according to his own instructions and rules, such as stipulating a few hours of study every day and teaching the child every question. Throughout the process, the emphasis is on hands-on instruction, with the initiative and focus being on the parents. For NLP, the initiative and focus of the entire process lies with programmers and researchers who write language rules.
The statistics-based method is like parents only telling their children how to learn, but not teaching each specific question. The emphasis is on semi-guidance. For NLP, the focus of learning is on neural network models, but the initiative is still controlled by algorithm engineers.
Based on the method of intensive learning, it is like parents only set educational goals for their children. For example, they require their children to reach 90 points in the exam, but they do not care about how the children learn and rely entirely on self-study. Children have a very high degree of freedom and initiative. Parents only reward or punish the final results and do not participate in the entire education process. For NLP, the focus and initiative of the entire process lies in the model itself.
The development of NLP has been gradually moving closer to methods based on statistics, and finally the method based on reinforcement learning achieved complete victory. The sign of victory is ChatGPT came out; and the rule-based method gradually declined and became an auxiliary processing method. From the beginning, the development of the ChatGPT model has been unswervingly progressing in the direction of letting the model learn by itself.
ChatGPT’s neural network structure Transformer
In the previous introduction, in order to facilitate readers’ understanding, the specific internal structure of the ChatGPT model was not mentioned.
ChatGPT is a large neural network. Its internal structure is composed of several layers of Transformer. Transformer is a structure of a neural network. Since 2018, it has become a common standard model structure in the NLP field, and Transformer can be found in almost all NLP models.
If ChatGPT is a house, then Transformer is the brick that builds ChatGPT.
The core of Transformer is the self-attention mechanism (Self-Attention), which can help the model automatically pay attention to other position characters related to the current position character when processing the input text sequence. The self-attention mechanism can represent each position in the input sequence as a vector, and these vectors can participate in calculations at the same time, thereby achieving efficient parallel computing. Give an example:
In machine translation, when translating the English sentence "I am a good student" into Chinese, the traditional machine translation model may translate it into "I am a good student" student", but this translation may not be accurate enough. The article "a" in English needs to be determined based on the context when translated into Chinese.
When using the Transformer model for translation, you can get more accurate translation results, such as "I am a good student."
This is because Transformer can better capture the relationship between words across long distances in English sentences and solve long dependencies in text context. The self-attention mechanism will be introduced in Section 5-6, and the detailed structure of Transformer will be introduced in Section 6-7.
Summary
- The development of the NLP field has gradually shifted from manually writing rules and logically controlling computer programs to completely leaving it to the network model to adapt to the language environment.
- ChatGPT is currently the NLP model closest to passing the Turing test, and GPT4 and GPT5 will be even closer in the future.
- The workflow of ChatGPT is a generative dialogue system.
- ChatGPT’s training process includes language model pre-training and RLHF reinforcement learning with manual feedback.
- The model structure of ChatGPT adopts Transformer with self-attention mechanism as the core.
The above is the detailed content of Everyone understands ChatGPT Chapter 1: ChatGPT and natural language processing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
The foundation, frontier and application of GNN
Apr 11, 2023 pm 11:40 PM
Graph neural networks (GNN) have made rapid and incredible progress in recent years. Graph neural network, also known as graph deep learning, graph representation learning (graph representation learning) or geometric deep learning, is the fastest growing research topic in the field of machine learning, especially deep learning. The title of this sharing is "Basics, Frontiers and Applications of GNN", which mainly introduces the general content of the comprehensive book "Basics, Frontiers and Applications of Graph Neural Networks" compiled by scholars Wu Lingfei, Cui Peng, Pei Jian and Zhao Liang. . 1. Introduction to graph neural networks 1. Why study graphs? Graphs are a universal language for describing and modeling complex systems. The graph itself is not complicated, it mainly consists of edges and nodes. We can use nodes to represent any object we want to model, and edges to represent two
 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
An overview of the three mainstream chip architectures for autonomous driving in one article
Apr 12, 2023 pm 12:07 PM
The current mainstream AI chips are mainly divided into three categories: GPU, FPGA, and ASIC. Both GPU and FPGA are relatively mature chip architectures in the early stage and are general-purpose chips. ASIC is a chip customized for specific AI scenarios. The industry has confirmed that CPUs are not suitable for AI computing, but they are also essential in AI applications. GPU Solution Architecture Comparison between GPU and CPU The CPU follows the von Neumann architecture, the core of which is the storage of programs/data and serial sequential execution. Therefore, the CPU architecture requires a large amount of space to place the storage unit (Cache) and the control unit (Control). In contrast, the computing unit (ALU) only occupies a small part, so the CPU is performing large-scale parallel computing.
 'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
'The owner of Bilibili UP successfully created the world's first redstone-based neural network, which caused a sensation on social media and was praised by Yann LeCun.'
May 07, 2023 pm 10:58 PM
In Minecraft, redstone is a very important item. It is a unique material in the game. Switches, redstone torches, and redstone blocks can provide electricity-like energy to wires or objects. Redstone circuits can be used to build structures for you to control or activate other machinery. They themselves can be designed to respond to manual activation by players, or they can repeatedly output signals or respond to changes caused by non-players, such as creature movement and items. Falling, plant growth, day and night, and more. Therefore, in my world, redstone can control extremely many types of machinery, ranging from simple machinery such as automatic doors, light switches and strobe power supplies, to huge elevators, automatic farms, small game platforms and even in-game machines. built computer. Recently, B station UP main @
 A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
A drone that can withstand strong winds? Caltech uses 12 minutes of flight data to teach drones to fly in the wind
Apr 09, 2023 pm 11:51 PM
When the wind is strong enough to blow the umbrella, the drone is stable, just like this: Flying with the wind is a part of flying in the air. From a large level, when the pilot lands the aircraft, the wind speed may be Bringing challenges to them; on a smaller level, gusty winds can also affect drone flight. Currently, drones either fly under controlled conditions, without wind, or are operated by humans using remote controls. Drones are controlled by researchers to fly in formations in the open sky, but these flights are usually conducted under ideal conditions and environments. However, for drones to autonomously perform necessary but routine tasks, such as delivering packages, they must be able to adapt to wind conditions in real time. To make drones more maneuverable when flying in the wind, a team of engineers from Caltech
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 The practice of contrastive learning algorithms in Zhuanzhuan
Apr 11, 2023 pm 09:25 PM
The practice of contrastive learning algorithms in Zhuanzhuan
Apr 11, 2023 pm 09:25 PM
1 What is contrastive learning 1.1 Definition of contrastive learning 1.2 Principles of contrastive learning 1.3 Classic contrastive learning algorithm series 2 Application of contrastive learning 3 The practice of contrastive learning in Zhuanzhuan 3.1 The practice of CL in recommended recall 3.2 CL’s future planning in Zhuanzhuan 1 What is Contrastive Learning 1.1 Definition of Contrastive Learning Contrastive Learning (CL) is a popular research direction in the field of AI in recent years, attracting the attention of many research scholars. Its self-supervised learning method was even announced by Bengio at ICLR 2020. He and LeCun and other big guys named it as the future of AI, and then successively landed on NIPS, ACL,
