

What is the Redis cache update strategy?

1. Benefits and costs of caching
1.1 Benefits
Accelerate reading and writing: Because the cache is usually full memory (for example Redis, Memcache), and the storage layer usually does not have strong read and write performance (such as MySQL), and the memory read and write speed is much higher than disk I/O. The use of cache can effectively accelerate reading and writing and optimize user experience.
Reduce back-end load: Help the back-end reduce access (Mysql is set with a maximum number of connections, if a large number of accesses reach the database at the same time, and disk I/O The speed is very slow, which can easily cause the maximum number of connections to be used up, but Redis theoretical maximum) and complex calculations (such as very complex SQL statements) reduce the load on the backend to a great extent.
1.2 Cost
Data inconsistency: The data in the cache layer and the storage layer are inconsistent within a certain time window The time window is related to the update strategy.
Code maintenance cost: After adding the cache, the logic of the cache layer and the storage layer needs to be processed at the same time, which increases the cost of maintaining the code for developers.
Operation and maintenance costs: Take Redis Cluster as an example. After joining, the operation and maintenance costs will be increased virtually.
1.3 Usage scenarios
Complex calculations with high overhead: Take MySQL as an example, some complex operations or calculations (For example, a large number of joint table operations, some grouping calculations), if caching is not added, not only will it be unable to meet the high concurrency, but it will also bring a huge burden to MySQL.
Accelerate request response: Even if querying a single piece of backend data is fast enough, you can still use cache. Taking Redis as an example, tens of thousands of reads can be completed per second. Write, and the batch operations provided can optimize the response time of the entire IO chain
2. Cache update strategy
2.1 Memory overflow elimination strategy
Thinking: Redis in the production environment often loses some data. Once it is written, it may be gone after a while. what is the reason?
Normally, the Redis cache is stored in memory, but considering that memory is precious and limited, it is common to use cheap and large disks for storage. A machine might only have a few dozen gigabytes of memory, but could have several terabytes of hard drive capacity. Redis is mainly based on memory to perform high-performance, high-concurrency read and write operations. So since the memory is limited, for example, redis can only use 10G. What will you do if you write 20G of data into it? Of course, the 10G data will be deleted, and then the 10G data will be retained. What data needs to be deleted? What data needs to be retained? Obviously, you need to delete infrequently used data and retain frequently used data. Redis's expiration policy determines that even if the data has expired, it will continue to occupy memory.
In Redis, when the used memory reaches the maxmemory upper limit (used_memory>maxmemory), the corresponding overflow control policy will be triggered. The specific policy is controlled by the maxmemory-policy parameter.
Redis supports 6 strategies:
noeviction: Default strategy, no data will be deleted, all write operations will be rejected and returned to the client Error message (error) OOM command not allowed when used memory, at this time Redis only responds to read operations
According to the LRU algorithm, delete the key value with the timeout attribute (expire) and release enough space . If there are no deletable key objects, fall back to the noeviction strategy
volatile-random: randomly delete expired keys until enough space is freed
allkeys-lru: Delete keys according to the LRU algorithm, regardless of whether the data has a timeout attribute set, until enough space is made available
allkeys-random: Delete all keys randomly until enough space is made available Until there is enough space (not recommended)
volatile-ttl: Delete the most recently expired data based on the ttl (time to live, TTL) attribute of the key-value object. If not, fall back to the noeviction strategy
LRU: Least Recently Used, the least recently used, cached elements have a timestamp, when the cache capacity is full and needs to be freed up When a new element is cached, the element with the timestamp farthest from the current time among the existing cache elements will be cleared from the cache.
The memory overflow control strategy can be dynamically configured using config set maxmemory-policy{policy}. Write commands lead to frequent execution of memory recovery when memory overflows, which is very costly. In the master-slave replication architecture, the delete command corresponding to the memory recovery operation will be synchronized to the slave node to ensure the data consistency of the master and slave nodes, resulting in write amplification. The problem.
2.2 Expiration strategy
The expiration strategy adopted by the Redis server is: Lazy deletion Regular deletion
Lazy deletion:
Each Redis library contains an expiration dictionary, which saves the expiration time of all keys. When the client reads a key, it will first check whether the key has expired in the expiration dictionary. If the key has expired, it will perform a delete operation and return empty. This strategy is to save CPU costs, but using this method alone has the problem of memory leakage. When the expired key has not been accessed, it will not be deleted in time, resulting in the memory not being released in time.
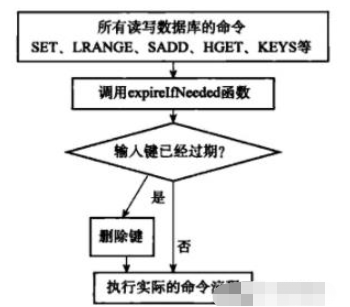
Scheduled deletion:
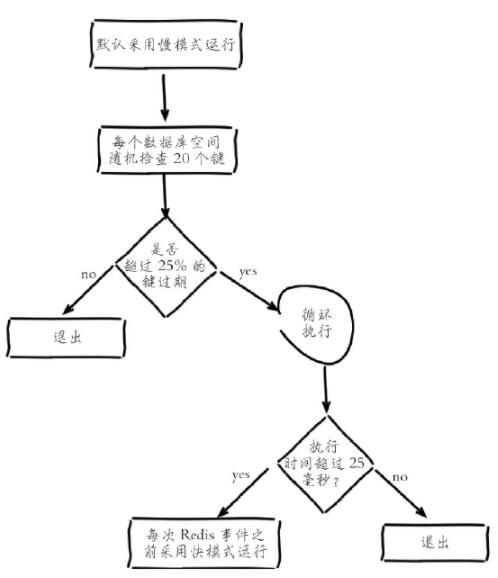
Redis maintains a scheduled task internally, and runs 10 expiration scans per second by default (modified by hz configuration in redis.conf) times), the scan does not traverse all keys in the expired dictionary, but uses an adaptive algorithm to recycle keys based on the expiration ratio of the key using two rate modes: fast and slow:
1. Randomly from the expired dictionary Take out 20 keys
2. Delete the expired keys among these 20 keys
3. If the proportion of expired keys exceeds 25%, repeat steps 1 and 2
to ensure that there will be no loop in the scan Excessive, it has been executing scheduled deletion scheduled tasks and cannot provide services to the outside world, causing the thread to get stuck. It also increases the upper limit of the scan time. The default is 25 milliseconds (that is, the default is in slow mode. If 25 milliseconds have not been completed, switch to block mode, the timeout time in mode is 1 millisecond and can only be run once within 2 seconds. When the slow mode is completed and exits normally, it will switch back to the fast mode)
三, Application side update
1. The application first retrieves the data from the cache. If it does not get it, it retrieves the data from the database. After success, it puts it in the cache.
2. Delete the cache first, and then update the database: This operation has a big problem. After the cache is deleted, the request to update the data receives a read request. At this time, because the cache has been deleted, the read request will be read directly. library, the data for read operations is old and will be loaded into the cache. Subsequent read requests will access all the old data.
3. Update the database first, then delete the cache (recommended). Why not update the cache after writing to the database? The main reason is that two concurrent write operations may cause dirty data.
4. Cache granularity
1 Universality
Caching all data is more versatile than partial data, but from actual experience, applications only need a few important ones for a long time properties.
2 Occupying space
Caching all data takes up more space than part of the data. There are the following problems:
All data will cause memory failure waste.
All data may generate a large amount of network traffic each time it is transmitted, and it will take a relatively long time. In extreme cases, it may block the network.
The CPU overhead of serialization and deserialization of all data is greater.
3 Code Maintenance
Full data has obvious advantages, but if you want to add new fields to some data, you need to modify the business code and usually refresh the cached data. .
The above is the detailed content of What is the Redis cache update strategy?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
