

How SpringBoot integrates Kafka configuration tool class

spring-kafka is based on the integration of the java version of kafka client and spring. It provides KafkaTemplate, which encapsulates various methods for easy operation. It encapsulates apache's kafka-client and does not need to import client dependencies
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>YML Configuration
kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'Simple tool class, can meet normal use, the theme cannot be modified
@Component
@Slf4j
public class KafkaUtils<K, V> {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.bootstrap-servers}")
String[] servers;
/**
* 获取连接
* @return
*/
private Admin getAdmin() {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
// 正式环境需要添加账号密码
return Admin.create(properties);
}
/**
* 增加topic
*
* @param name 主题名字
* @param partition 分区数量
* @param replica 副本数量
* @date 2022-06-23 chens
*/
public R addTopic(String name, Integer partition, Integer replica) {
Admin admin = getAdmin();
if (replica > servers.length) {
return R.error("副本数量不允许超过Broker数量");
}
try {
NewTopic topic = new NewTopic(name, partition, Short.parseShort(replica.toString()));
admin.createTopics(Collections.singleton(topic));
} finally {
admin.close();
}
return R.ok();
}
/**
* 删除主题
*
* @param names 主题名字集合
* @date 2022-06-23 chens
*/
public void deleteTopic(List<String> names) {
Admin admin = getAdmin();
try {
admin.deleteTopics(names);
} finally {
admin.close();
}
}
/**
* 查询所有主题
*
* @date 2022-06-24 chens
*/
public Set<String> queryTopic() {
Admin admin = getAdmin();
try {
ListTopicsResult topics = admin.listTopics();
Set<String> set = topics.names().get();
return set;
} catch (Exception e) {
log.error("查询主题错误!");
} finally {
admin.close();
}
return null;
}
// 向所有分区发送消息
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
return kafkaTemplate.send(topic, data);
}
// 指定key发送消息,相同key保证消息在同一个分区
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
return kafkaTemplate.send(topic, key, data);
}
// 指定分区和key发送。
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data) {
return kafkaTemplate.send(topic, partition, key, data);
}
}Send message Use asynchronous
@GetMapping("/{topic}")
public String test(@PathVariable String topic, @PathVariable Long index) throws ExecutionException, InterruptedException {
ListenableFuture future = null;
Chenshuang user = new Chenshuang(i, "陈爽", "123456", new Date());
String s = JSON.toJSONString(user);
KafkaUtils utils = new KafkaUtils();
future = kafkaUtils.send(topic, s);
// 异步回调,同步get,会等待 不推荐同步!
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
System.out.println("发送成功:" + result);
}
});
return "发送成功";
}Create a topic
If the broker configures auto.create.topics.enable to be true (the default is true), it will be used when receiving a metadata request from the client. Create topic.
Sending and consuming a topic that does not exist will create a new topic. In many cases, unexpected topic creation will lead to many unexpected problems. It is recommended to turn off this feature.
Topic topics are used to distinguish different types of messages. In fact, they are suitable for different business scenarios. By default, messages are saved for one week;
Under the same Topic topic, the default is a partition. That is to say, there can only be one consumer for consumption. If you want to improve consumption capacity, you need to add partitions;
For multiple partitions of the same Topic, there are three ways to distribute messages (key, value) to different Partition, specify the partition, HASH routing, default, the message ID in the same partition is unique and in order;
When consumers consume messages in the partition partition, they use offset to identify the location of the message;
GroupId is used to solve the problem of repeated consumption under the same Topic. For example, if a consumption needs to be received by multiple consumers, it can be achieved by setting different GroupIds.
The actual message is saved in one copy. It is only distinguished by setting the identifier logically. The system will record the offset under the Topic topic -> GroupId group - and partition partition to identify whether it has been consumed.
High availability of sending messages - cluster mode, multi-copy implementation; the submission of a message may achieve different availability by setting the acks identifier. When =0, it is OK if the sending is successful. ;=1, the master responds successfully before it is OK, and =all, more than half of the responses are OK (real high availability)
High availability of consumer messages--you can turn off automatic identification Offsert mode, first pull the message, after the consumption is completed, then set the offset position to solve the high availability of consumption
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopic {
// yml自定义主题,项目启动就创建,
@Value("${spring.kafka.topic}")
String topic;
@Value("${spring.kafka.bootstrap-servers}")
String[] server;
/**
* 项目启动 初始化主题,如果存在不会覆盖主题的
*/
@Bean
public NewTopic batchTopic() {
// 最大复制因子 <= 经纪人broker数量.
return new NewTopic(topic, 10, (short) server.length);
}
}Listening class, a message, only one consumer in each group consumes it once, if The message is in zone 1. Specifying partition 1 to monitor will also consume
You can also monitor different topics with the same method and specify displacement monitoringThe same group will consume evenly, and different groups will consume repeatedly.
1. Unicast mode, there is only one consumer group
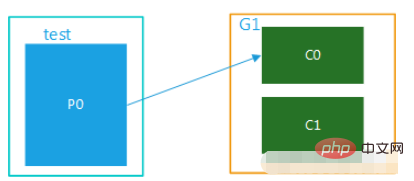
(1) The topic has only one partition. When there are multiple consumers in the group, the messages in the same partition will Can only be consumed by one consumer in the group. When the number of consumers exceeds the number of partitions, the excess consumers are idle, as shown in Figure 1. Topic and test have only one partition and only one group, G1. There are multiple consumers in this group and can only be consumed by one of them, while the others are idle.
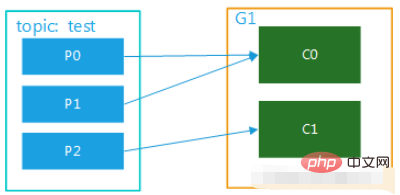
 (2) The topic has multiple partitions, and there are multiple consumers in the group. For example, test has 3 partitions. If there are two consumers in the group, then C0 may correspond to consuming data in p0 and p1, and c1 corresponds to consuming data in p2; if there are three consumers, one consumer corresponds to consuming data in one partition. The diagrams are shown in Figure 2 and Figure 3. This mode is very common in cluster mode. For example, we can start 3 services and set 3 partitions for the corresponding topic, so that parallel consumption can be achieved and the efficiency of processing messages can be greatly improved. efficiency.
(2) The topic has multiple partitions, and there are multiple consumers in the group. For example, test has 3 partitions. If there are two consumers in the group, then C0 may correspond to consuming data in p0 and p1, and c1 corresponds to consuming data in p2; if there are three consumers, one consumer corresponds to consuming data in one partition. The diagrams are shown in Figure 2 and Figure 3. This mode is very common in cluster mode. For example, we can start 3 services and set 3 partitions for the corresponding topic, so that parallel consumption can be achieved and the efficiency of processing messages can be greatly improved. efficiency.
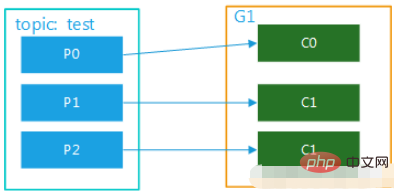 2. Broadcast mode, multiple consumer groups
2. Broadcast mode, multiple consumer groups
If you want to implement the broadcast mode, you need to set up multiple consumer groups, so that after one consumer group consumes the message, it will not affect the consumption of consumers in other groups at all. This is the concept of broadcasting .
(1) Multiple consumer groups, 1 partition
The data in this topic is consumed by multiple consumer groups at the same time. When a consumer group has multiple consumers It can only be consumed by one consumer, as shown in Figure 4:
Figure 4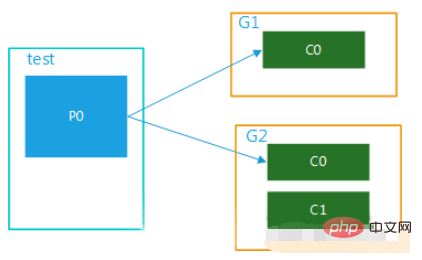 (2) Multiple consumer groups, multiple partitions
(2) Multiple consumer groups, multiple partitions
The data in this topic can be consumed multiple times by multiple consumer groups. Within a consumer group, each consumer can consume in parallel corresponding to one or more partitions in the topic, as shown in the figure five:
注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}The above is the detailed content of How SpringBoot integrates Kafka configuration tool class. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
How to implement real-time stock analysis using PHP and Kafka
Jun 28, 2023 am 10:04 AM
With the development of the Internet and technology, digital investment has become a topic of increasing concern. Many investors continue to explore and study investment strategies, hoping to obtain a higher return on investment. In stock trading, real-time stock analysis is very important for decision-making, and the use of Kafka real-time message queue and PHP technology is an efficient and practical means. 1. Introduction to Kafka Kafka is a high-throughput distributed publish and subscribe messaging system developed by LinkedIn. The main features of Kafka are
 Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot and SpringMVC are both commonly used frameworks in Java development, but there are some obvious differences between them. This article will explore the features and uses of these two frameworks and compare their differences. First, let's learn about SpringBoot. SpringBoot was developed by the Pivotal team to simplify the creation and deployment of applications based on the Spring framework. It provides a fast, lightweight way to build stand-alone, executable
 How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to build real-time data processing applications using React and Apache Kafka
Sep 27, 2023 pm 02:25 PM
How to use React and Apache Kafka to build real-time data processing applications Introduction: With the rise of big data and real-time data processing, building real-time data processing applications has become the pursuit of many developers. The combination of React, a popular front-end framework, and Apache Kafka, a high-performance distributed messaging system, can help us build real-time data processing applications. This article will introduce how to use React and Apache Kafka to build real-time data processing applications, and
 SpringBoot+Dubbo+Nacos development practical tutorial
Aug 15, 2023 pm 04:49 PM
SpringBoot+Dubbo+Nacos development practical tutorial
Aug 15, 2023 pm 04:49 PM
This article will write a detailed example to talk about the actual development of dubbo+nacos+Spring Boot. This article will not cover too much theoretical knowledge, but will write the simplest example to illustrate how dubbo can be integrated with nacos to quickly build a development environment.
 Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five selections of visualization tools for exploring Kafka
Feb 01, 2024 am 08:03 AM
Five options for Kafka visualization tools ApacheKafka is a distributed stream processing platform capable of processing large amounts of real-time data. It is widely used to build real-time data pipelines, message queues, and event-driven applications. Kafka's visualization tools can help users monitor and manage Kafka clusters and better understand Kafka data flows. The following is an introduction to five popular Kafka visualization tools: ConfluentControlCenterConfluent
 Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
Comparative analysis of kafka visualization tools: How to choose the most appropriate tool?
Jan 05, 2024 pm 12:15 PM
How to choose the right Kafka visualization tool? Comparative analysis of five tools Introduction: Kafka is a high-performance, high-throughput distributed message queue system that is widely used in the field of big data. With the popularity of Kafka, more and more enterprises and developers need a visual tool to easily monitor and manage Kafka clusters. This article will introduce five commonly used Kafka visualization tools and compare their features and functions to help readers choose the tool that suits their needs. 1. KafkaManager
 The practice of go-zero and Kafka+Avro: building a high-performance interactive data processing system
Jun 23, 2023 am 09:04 AM
The practice of go-zero and Kafka+Avro: building a high-performance interactive data processing system
Jun 23, 2023 am 09:04 AM
In recent years, with the rise of big data and active open source communities, more and more enterprises have begun to look for high-performance interactive data processing systems to meet the growing data needs. In this wave of technology upgrades, go-zero and Kafka+Avro are being paid attention to and adopted by more and more enterprises. go-zero is a microservice framework developed based on the Golang language. It has the characteristics of high performance, ease of use, easy expansion, and easy maintenance. It is designed to help enterprises quickly build efficient microservice application systems. its rapid growth
 How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
How to install Apache Kafka on Rocky Linux?
Mar 01, 2024 pm 10:37 PM
To install ApacheKafka on RockyLinux, you can follow the following steps: Update system: First, make sure your RockyLinux system is up to date, execute the following command to update the system package: sudoyumupdate Install Java: ApacheKafka depends on Java, so you need to install JavaDevelopmentKit (JDK) first ). OpenJDK can be installed through the following command: sudoyuminstalljava-1.8.0-openjdk-devel Download and decompress: Visit the ApacheKafka official website () to download the latest binary package. Choose a stable version
