
 Technology peripherals
AI
From mice walking in the maze to AlphaGo defeating humans, the development of reinforcement learning
Technology peripherals
AI
From mice walking in the maze to AlphaGo defeating humans, the development of reinforcement learning
From mice walking in the maze to AlphaGo defeating humans, the development of reinforcement learning

When it comes to reinforcement learning, many researchers’ adrenaline surges uncontrollably! It plays a very important role in game AI systems, modern robots, chip design systems and other applications.
There are many different types of reinforcement learning algorithms, but they are mainly divided into two categories: "model-based" and "model-free".
In a conversation with TechTalks, neuroscientist and author of "The Birth of Intelligence" Daeyeol Lee discusses different models of reinforcement learning in humans and animals, artificial intelligence and natural intelligence, and future research directions .

Model-free reinforcement learning
In the late 19th century, the "law of effect" proposed by psychologist Edward Thorndike became the basis of model-free reinforcement learning . Thorndike proposed that behaviors that have a positive impact in a specific situation are more likely to happen again in that situation, while behaviors that have a negative impact are less likely to happen again.
Thorndike explored this "law of effect" in an experiment. He placed a cat in a maze box and measured the time it took for the cat to escape from the box. To escape, the cat must operate a series of gadgets, such as ropes and levers. Thorndike observed that as the cat interacted with the puzzle box, it learned behaviors that aided in its escape. As time goes by, the cat escapes the box faster and faster. Thorndike concluded that cats can learn from the rewards and punishments their behaviors provide. The "Law of Effect" later paved the way for behaviorism. Behaviorism is a branch of psychology that attempts to explain human and animal behavior in terms of stimuli and responses. The “Law of Effect” is also the basis of model-free reinforcement learning. In model-free reinforcement learning, an agent perceives the world and then takes actions while measuring rewards.
In model-free reinforcement learning, there is no direct knowledge or world model. RL agents must directly experience the results of each action through trial and error.
Model-based reinforcement learning
Thorndike’s “Law of Effect” remained popular until the 1930s. Another psychologist at the time, Edward Tolman, discovered an important insight while exploring how rats quickly learned to navigate mazes. During his experiments, Tolman realized that animals could learn about their environment without reinforcement.
For example, when a mouse is released in a maze, it will freely explore the tunnel and gradually understand the structure of the environment. If the rat is then reintroduced to the same environment and provided with reinforcing signals, such as searching for food or finding an exit, it can reach the goal faster than an animal that has not explored the maze. Tolman calls this "latent learning", which becomes the basis of model-based reinforcement learning. "Latent learning" allows animals and humans to form a mental representation of their world, simulate hypothetical scenarios in their minds, and predict outcomes.
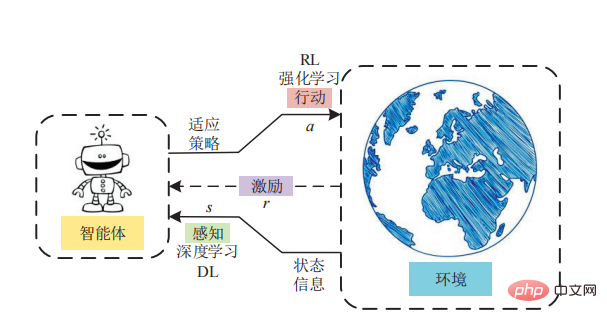
# The advantage of model-based reinforcement learning is that it eliminates the need for the agent to perform trial and error in the environment. It’s worth emphasizing that model-based reinforcement learning has been particularly successful in developing artificial intelligence systems capable of mastering board games such as chess and Go, possibly because the environments of these games are deterministic.

Model-based VS model-free
Generally speaking, model-based reinforcement learning will be very time-consuming. When it is extremely time-sensitive, it may Fatal danger occurs. "Computationally, model-based reinforcement learning is much more complex," Lee said. "First you have to obtain the model, perform a mental simulation, and then you have to find the trajectory of the neural process and then take action. However, model-based reinforcement learning is not necessarily It's more complicated than model-free RL." When the environment is very complex, if it can be modeled with a relatively simple model (which can be obtained quickly), then the simulation will be much simpler and cost-effective.
Multiple learning modes
In fact, neither model-based reinforcement learning nor model-free reinforcement learning is a perfect solution. Wherever you see a reinforcement learning system solving a complex problem, it's likely that it uses both model-based and model-free reinforcement learning, and possibly even more forms of learning. Research in neuroscience shows that both humans and animals have multiple ways of learning, and that the brain is constantly switching between these modes at any given moment. In recent years, there has been growing interest in creating artificial intelligence systems that combine multiple reinforcement learning models. Recent research by scientists at UC San Diego shows that combining model-free reinforcement learning and model-based reinforcement learning can achieve superior performance in control tasks. "If you look at a complex algorithm like AlphaGo, it has both model-free RL elements and model-based RL elements," Lee said. "It learns state values based on the board configuration. It's basically model-free RL, but it Model-based forward search is also performed."
Despite significant achievements, progress in reinforcement learning remains slow. Once an RL model faces a complex and unpredictable environment, its performance begins to degrade.
Lee said: "I think our brain is a complex world of learning algorithms that have evolved to handle many different situations."
In addition to constantly moving between these learning modes Beyond switching, the brain also manages to maintain and update them all the time, even when they are not actively involved in decision-making.
Psychologist Daniel Kahneman said: "Maintaining different learning modules and updating them simultaneously can help improve the efficiency and accuracy of artificial intelligence systems."
We also need to understand another aspect. Thing - how to apply the right inductive bias in AI systems to ensure they learn the right things in a cost-effective way. Billions of years of evolution have given humans and animals the inductive bias needed to learn effectively while using as little data as possible. Inductive bias can be understood as summarizing the rules from the phenomena observed in real life, and then placing certain constraints on the model, which can play the role of model selection, that is, selecting a model that is more consistent with the real rules from the hypothesis space. . "We get very little information from the environment. Using that information, we have to generalize," Lee said. "The reason is that the brain has an inductive bias, and there's a bias to generalizing from a small set of examples. That's a product of evolution." "More and more neuroscientists are interested in this." However, while inductive bias is easy to understand in object recognition tasks, it becomes obscure in abstract problems such as constructing social relationships. In the future, there is still a lot we need to know~~~
Reference materials:
https://thenextweb.com/news/everything-you-need-to-know-about- model-free-and-model-based-reinforcement-learning
The above is the detailed content of From mice walking in the maze to AlphaGo defeating humans, the development of reinforcement learning. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
