
 Technology peripherals
AI
Google launches multi-modal Vid2Seq, understanding video IQ online, subtitles will not be offline | CVPR 2023
Technology peripherals
AI
Google launches multi-modal Vid2Seq, understanding video IQ online, subtitles will not be offline | CVPR 2023
Google launches multi-modal Vid2Seq, understanding video IQ online, subtitles will not be offline | CVPR 2023

Chinese doctors and Google scientists recently proposed the pre-trained visual language model Vid2Seq, which can distinguish and describe multiple events in a video. This paper has been accepted by CVPR 2023.
Recently, researchers from Google proposed a pre-trained visual language model for describing multi-event videos - Vid2Seq, which has been accepted by CVPR23.
Previously, understanding video content was a challenging task because videos often contained multiple events occurring at different time scales.
For example, a video of a musher tying a dog to a sled and then the dog starting to run involves a long event (dog sledding) and a short event (dog tied to sled).
One way to advance video understanding research is through dense video annotation tasks, which involve temporally locating and describing all events in a minute-long video.

Paper address: https://arxiv.org/abs/2302.14115
The Vid2Seq architecture enhances the language model with special time stamps, allowing it to Seamlessly predict event boundaries and textual descriptions in the same output sequence.
In order to pre-train this unified model, the researchers exploited unlabeled Narrated video.

Vid2Seq Model Overview
The resulting Vid2Seq model was pre-trained on millions of narrated videos, improving various dense The technical level of video annotation benchmarks, including YouCook2, ViTT and ActivityNet Captions.
Vid2Seq is also well suited to few-shot dense video annotation settings, video segment annotation tasks, and standard video annotation tasks.

Visual language model for dense video annotation
The multi-modal Transformer architecture has refreshed the SOTA of various video tasks, such as action recognition. However, adapting such an architecture to the complex task of jointly locating and annotating events in minutes-long videos is not straightforward.
To achieve this goal, researchers enhance the visual language model with special time markers (such as text markers) that represent discrete timestamps in the video, similar to Pix2Seq in the spatial domain.
For a given visual input, the resulting Vid2Seq model can both accept the input and generate text and time-tagged sequences.
First, this enables the Vid2Seq model to understand the temporal information of the transcribed speech input, which is projected as a single sequence of tokens. Second, this enables Vid2Seq to jointly predict dense event annotations temporally within the video while generating a single sequence of markers.
The Vid2Seq architecture includes a visual encoder and a text encoder that encode video frames and transcribed speech input respectively. The resulting encodings are then forwarded to a text decoder, which automatically predicts the output sequence of dense event annotations, as well as their temporal positioning in the video. The architecture is initialized with a strong visual backbone and a strong language model.

Large-scale pre-training on videos
Manually collecting annotations for dense video annotation is particularly costly due to the intensive nature of the task.
Therefore, the researchers used unlabeled narration videos to pre-train the Vid2Seq model, which are easily available at scale. They also used the YT-Temporal-1B dataset, which includes 18 million narrated videos covering a wide range of domains.
The researchers used transcribed speech sentences and their corresponding timestamps as supervision, and these sentences were projected as a single token sequence.
Vid2Seq is then pretrained with a generative objective that teaches the decoder to predict only transcribed speech sequences given visual input, and a denoising objective that encourages multimodal learning, requiring the model to Predictive masks in the context of noisy transcribed speech sequences and visual input. In particular, noise is added to the speech sequence by randomly masking span tokens.

Benchmark results for downstream tasks
The resulting pre-trained Vid2Seq model can be fine-tuned on downstream tasks via a simple maximum likelihood objective that uses teacher forcing (i.e., given Predict the next token based on the previous basic real token).
After fine-tuning, Vid2Seq surpasses SOTA on three standard downstream dense video annotation benchmarks (ActivityNet Captions, YouCook2, and ViTT) and two video clip annotation benchmarks (MSR-VTT, MSVD).
In the paper, there are additional ablation studies, qualitative results, and results in a few-shot setting and video paragraph annotation tasks.
Qualitative testing
The results show that Vid2Seq can predict meaningful event boundaries and annotations, and that the predicted annotations and boundaries are significantly different from the transcribed speech input (this also shows that the input importance of visual markers).

The next example is about a series of instructions in a cooking recipe, which is an example of intensive event annotation prediction by Vid2Seq on the YouCook2 validation set:

What follows is an example of Vid2Seq’s dense event annotation predictions on the ActivityNet Captions validation set. In all of these videos, there is no transcribed speech.
However, there will still be cases of failure. For example, the picture marked in red below, Vid2Seq said, is a person taking off his hat in front of the camera.
Benchmarking SOTA
Table 5 compares Vid2Seq with the most advanced dense video annotation methods: Vid2Seq refreshes SOTA on the three data sets of YouCook2, ViTT and ActivityNet Captions.

Vid2Seq’s SODA indicators on YouCook2 and ActivityNet Captions are 3.5 and 0.3 points higher than PDVC and UEDVC respectively. And E2ESG uses in-domain plain text pre-training on Wikihow, and Vid2Seq is better than this method. These results show that the pre-trained Vid2Seq model has strong ability to label dense events.
Table 6 evaluates the event localization performance of the dense video annotation model. Compared with YouCook2 and ViTT, Vid2Seq is superior in handling dense video annotation as a single sequence generation task.

However, compared to PDVC and UEDVC, Vid2Seq performs poorly on ActivityNet Captions. Compared with these two methods, Vid2Seq integrates less prior knowledge about temporal localization, while the other two methods include task-specific components such as event counters or train a model separately for the localization subtask.
Implementation details
- Architecture
The visual temporal transformer encoder, text encoder and text decoder all have 12 layers, 12 heads, embedding dimensions 768, MLP hidden dimension 2048.
The sequences of the text encoder and decoder are truncated or padded to L=S=1000 tokens during pre-training, and S=1000 and L=256 tokens during fine-tuning. During inference, beam search decoding is used, the first 4 sequences are tracked and a length normalization of 0.6 is applied.
- Training
The author uses the Adam optimizer, β=(0.9, 0.999), without weight decay.
During pre-training, a learning rate of 1e^-4 is used, linearly warmed up (starting from 0) for the first 1000 iterations, and kept constant for the remaining iterations.
During fine-tuning, use a learning rate of 3e^-4, linearly warm up (starting from 0) in the first 10% of iterations, and maintain cosine decay (down to 0) in the remaining 90% of iterations. In the process, a batch size of 32 videos is used and divided on 16 TPU v4 chips.
The author made 40 epoch adjustments to YouCook2, 20 epoch adjustments to ActivityNet Captions and ViTT, 5 epoch adjustments to MSR-VTT, and 10 epoch adjustments to MSVD.
Conclusion
Vid2Seq proposed by Google is a new visual language model for dense video annotation. It can effectively perform large-scale pre-training on unlabeled narration videos. And achieved SOTA results on various downstream dense video annotation benchmarks.
Introduction to the author
First author of the paper: Antoine Yang

Antoine Yang is a third-year doctoral student in the WILLOW team of Inria and École Normale Supérieure in Paris. His supervisors are Antoine Miech, Josef Sivic, Ivan Laptev and Cordelia Schmid.
Current research focuses on learning visual language models for video understanding. He interned at Huawei's Noah's Ark Laboratory in 2019, received an engineering degree from Ecole Polytechnique in Paris and a master's degree in mathematics, vision and learning from the National University of Paris-Saclay in 2020, and interned at Google Research in 2022.
The above is the detailed content of Google launches multi-modal Vid2Seq, understanding video IQ online, subtitles will not be offline | CVPR 2023. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to Completely Remove Unwanted Display Languages on Windows 11
Sep 24, 2023 pm 04:25 PM
How to Completely Remove Unwanted Display Languages on Windows 11
Sep 24, 2023 pm 04:25 PM
Work on the same setup for too long or share your PC with others. You may have some language packs installed, which often create conflicts. So, it’s time to remove unwanted display languages in Windows 11. Speaking of conflicts, when there are multiple language packs, inadvertently pressing Ctrl+Shift changes the keyboard layout. If not taken care of, this can be a hindrance to the task at hand. So, let’s jump right into the method! How to remove display language from Windows 11? 1. From Settings press + to open the Settings app, go to Time & Language from the navigation pane and click on Language & Region. WindowsI click the ellipsis next to the display language you want to remove and select Remove from the pop-up menu. Click "
 3 Ways to Change Language on iPhone
Feb 02, 2024 pm 04:12 PM
3 Ways to Change Language on iPhone
Feb 02, 2024 pm 04:12 PM
It's no secret that the iPhone is one of the most user-friendly electronic gadgets, and one of the reasons why is that it can be easily personalized to your liking. In Personalization, you can change the language to a different language than the one you selected when setting up your iPhone. If you're familiar with multiple languages, or your iPhone's language setting is wrong, you can change it as we explain below. How to Change the Language of iPhone [3 Methods] iOS allows users to freely switch the preferred language on iPhone to adapt to different needs. You can change the language of interaction with Siri to facilitate communication with the voice assistant. At the same time, when using the local keyboard, you can easily switch between multiple languages to improve input efficiency.
 Adding comprehensive audio-visual capabilities to large language models, DAMO Academy opens source Video-LLaMA
Jun 09, 2023 pm 09:28 PM
Adding comprehensive audio-visual capabilities to large language models, DAMO Academy opens source Video-LLaMA
Jun 09, 2023 pm 09:28 PM
Video plays an increasingly important role in today's social media and Internet culture. Douyin, Kuaishou, Bilibili, etc. have become popular platforms for hundreds of millions of users. Users share their life moments, creative works, interesting moments and other content around videos to interact and communicate with others. Recently, large language models have demonstrated impressive capabilities. Can we equip large models with "eyes" and "ears" so that they can understand videos and interact with users? Starting from this problem, researchers from DAMO Academy proposed Video-LLaMA, a large model with comprehensive audio-visual capabilities. Video-LLaMA can perceive and understand the video and audio signals in the video, and can understand the instructions input by the user to complete a series of complex tasks based on audio and video,
 How to set the language of Win10 computer to Chinese?
Jan 05, 2024 pm 06:51 PM
How to set the language of Win10 computer to Chinese?
Jan 05, 2024 pm 06:51 PM
Sometimes we just install the computer system and find that the system is in English. In this case, we need to change the computer language to Chinese. So how to change the computer language to Chinese in the win10 system? Now Give you specific operation methods. How to change the computer language in win10 to Chinese 1. Turn on the computer and click the start button in the lower left corner. 2. Click the settings option on the left. 3. Select "Time and Language" on the page that opens. 4. After opening, click "Language" on the left. 5. Here you can set the computer language you want.
 What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is
Apr 07, 2023 pm 06:21 PM
What a noise! Does ChatGPT understand the language? PNAS: Let's first study what 'understanding” is
Apr 07, 2023 pm 06:21 PM
Asking whether a machine can think about it is like asking whether a submarine can swim. ——Dijkstra Even before the release of ChatGPT, the industry had already smelled the changes brought about by large models. On October 14 last year, professors Melanie Mitchell and David C. Krakauer of the Santa Fe Institute published a review on arXiv, comprehensively investigating all aspects of "whether large-scale pre-trained language models can understand language." Relevant debates, the article describes the "pro" and "con" arguments, as well as the key issues in the broader intelligence science derived from these arguments. Paper link: https://arxiv.o
 You can play Genshin Impact just by moving your mouth! Use AI to switch characters and attack enemies. Netizen: 'Ayaka, use Kamiri-ryu Frost Destruction'
May 13, 2023 pm 07:52 PM
You can play Genshin Impact just by moving your mouth! Use AI to switch characters and attack enemies. Netizen: 'Ayaka, use Kamiri-ryu Frost Destruction'
May 13, 2023 pm 07:52 PM
When it comes to domestic games that have become popular all over the world in the past two years, Genshin Impact definitely takes the cake. According to this year’s Q1 quarter mobile game revenue survey report released in May, “Genshin Impact” firmly won the first place among card-drawing mobile games with an absolute advantage of 567 million U.S. dollars. This also announced that “Genshin Impact” has been online in just 18 years. A few months later, total revenue from the mobile platform alone exceeded US$3 billion (approximately RM13 billion). Now, the last 2.8 island version before the opening of Xumi is long overdue. After a long draft period, there are finally new plots and areas to play. But I don’t know how many “Liver Emperors” there are. Now that the island has been fully explored, grass has begun to grow again. There are a total of 182 treasure chests + 1 Mora box (not included). There is no need to worry about the long grass period. The Genshin Impact area is never short of work. No, during the long grass
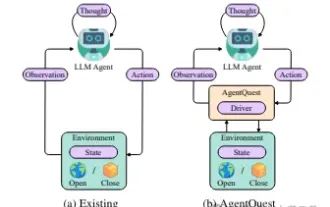 Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Apr 11, 2024 pm 08:52 PM
Exploring the boundaries of agents: AgentQuest, a modular benchmark framework for comprehensively measuring and improving the performance of large language model agents
Apr 11, 2024 pm 08:52 PM
Based on the continuous optimization of large models, LLM agents - these powerful algorithmic entities have shown the potential to solve complex multi-step reasoning tasks. From natural language processing to deep learning, LLM agents are gradually becoming the focus of research and industry. They can not only understand and generate human language, but also formulate strategies, perform tasks in diverse environments, and even use API calls and coding to Build solutions. In this context, the introduction of the AgentQuest framework is a milestone. It not only provides a modular benchmarking platform for the evaluation and advancement of LLM agents, but also provides researchers with a Powerful tools to track and improve the performance of these agents at a more granular level
 Fix: Alt + Shift doesn't change language on Windows 11
Oct 11, 2023 pm 02:17 PM
Fix: Alt + Shift doesn't change language on Windows 11
Oct 11, 2023 pm 02:17 PM
While Alt+Shift doesn't change the language on Windows 11, you can use Win+Spacebar to get the same effect. Also, make sure to use the left Alt+Shift and not the ones on the right side of the keyboard. Why can't Alt+Shift change the language? You have no more languages to choose from. Input language hotkeys have been changed. A bug in the latest Windows update prevents you from changing your keyboard language. Uninstall the latest updates to resolve this issue. You are in the active window of an application that uses the same hotkeys to perform other actions. How do you use AltShift to change the language on Windows 11? 1. Use the correct key sequence First, make sure you are using the correct method of using the + combination.
