

Detailed explanation of SQL window functions in one article

This article brings you relevant knowledge about SQL, which mainly organizes issues related to window functions. SQL window functions are provided for online analytical processing (OLAP) and business intelligence (BI). It has complex analysis and report statistics functions, such as cumulative sales statistics of products, category rankings, year-on-year/month-on-month analysis, etc. Let’s take a look at it together. I hope it will be helpful to everyone.

Recommended study: "SQL Tutorial"
What is a window function
SQL window function is for online analysis Processing (OLAP) and business intelligence (BI) provide complex analysis and report statistics functions, such as cumulative sales statistics of products, category rankings, year-on-year/month-on-month analysis, etc. These features are often difficult to implement with aggregate functions and grouping operations.
Window function (Window Function) can analyze a set of data and return results like an aggregate function. The difference between the two is that the window function does not summarize a set of data into a single result, but instead Each row of data returns a result. The difference between aggregate functions and window functions is shown in the figure below.

Take the SUM function as an example to demonstrate the difference between the two functions. SUM() in the following statement is an aggregate function:
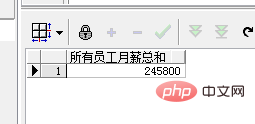
SELECT SUM(salary) AS "所有员工月薪总和" FROM employee
The above SUM function Can be used as an aggregate function to summarize all employee data into one result. Therefore, the query returns the total monthly salary of all employees:
SUM() in the following statement is a window function:
SELECT emp_name AS "员工姓名", SUM(salary) OVER () AS "所有员工月薪总和" FROM employee;
Among them, the keyword OVER Indicates that SUM() is a window function. Empty brackets indicate that all data are summarized as one group. The results returned by this query are as follows:
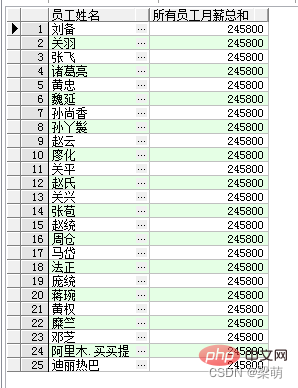
The above query results return all employee names, and the same summary result is returned for each employee through the aggregate function SUM() .
As you can see from the above example, the syntax of the window function is different from that of the aggregate function in that it contains an OVER clause. The OVER clause is used to specify a window for data analysis. The complete window function is defined as follows:

where window_function is the name of the window function and expression is an optional analysis object ( field name or expression), the OVER clause includes three options: partition (PARTITION BY), sorting (ORDER BY), and window size (frame_clause).
Tip: The aggregate function summarizes multiple rows of data in the same group into a single result, while the window function retains all the original data. In some databases, window functions are also called online analytical processing (OLAP) functions, or analytical functions.
Components of window function
1. Create data partition
The PARTITION BY option in the OVER clause of the window function is used to define partitions, and its role is similar to that in the query statement GROUP BY clause. If we specify the partition option, the window function will analyze each partition separately.
For example, the following statement counts the total monthly salary of employees according to different departments:
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", SUM(salary) OVER ( PARTITION BY dept_id ) AS "部门合计" FROM employee;
Among them, the PARTITION BY option indicates partitioning by department. The results returned by the query are as follows:
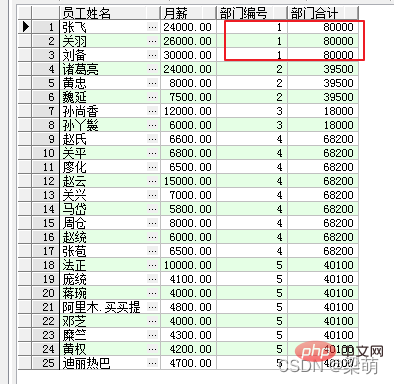
The first three rows of data in the query results belong to the same department, so their corresponding department total fields are equal to 80000 (30000 26000 24000). Employees in other departments are counted in the same way.
Tip: After specifying the PARTITION BY option in the window function OVER clause, we can obtain group statistical results without using the GROUP BY clause.
If the PARTITION BY option is not specified, it means that all data will be analyzed as a whole.
2. Sorting within the partition
The ORDER BY option in the OVER clause of the window function is used to specify the sorting method of the data in the partition, and its function is similar to the ORDER BY clause in the query statement.
Sort options are usually used for categorical ranking of data. For example, the following statement is used to analyze the monthly salary ranking of employees within the department:
SELECT emp_name AS "员工姓名", salary "月薪", dept_id AS "部门编号", RANK() OVER ( PARTITION BY dept_id ORDER BY salary DESC ) AS "部门内排名" FROM employee;
Among them, the RANK function is used to calculate the ranking of the data, the PARTITION BY option indicates partitioning by department, and the ORDER BY option indicates that within the department, the Monthly salary is sorted from high to low. The results returned by the query are as follows:
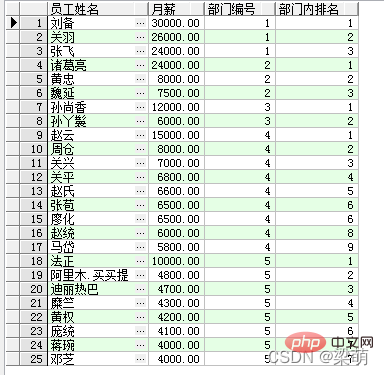
查询结果中的前3行数据属于同一个部门:“刘备”的月薪最高,在部门内排名第1;“关羽”排名第2;“张飞”排名第3。其他部门的员工采用同样的方式进行排名。
提示:窗口函数OVER子句中的ORDER BY选项和查询语句中的ORDER BY子句的使用方法相同。因此,也可以使用NULLS FIRST或者NULLS LAST选项指定空值的排序位置。
3.指定窗口大小
窗口函数OVER子句中的frame_clause选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销售额总和,每个月及其前后各N个月的平均销售额等。
指定窗口大小的具体选项如下:

其中,ROWS表示以数据行为单位计算窗口的偏移量,RANGE表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
frame_start选项用于定义窗口的起始位置,可以指定以下内容之一:
●UNBOUNDED PRECEDING——表示窗口从分区的第一行开始。
●N PRECEDING——表示窗口从当前行之前的第N行开始。
●CURRENT ROW——表示窗口从当前行开始。
frame_end选项用于定义窗口的结束位置,可以指定以下内容之一:
●CURRENT ROW——表示窗口到当前行结束。
●M FOLLOWING——表示窗口到当前行之后的第M行结束。
●UNBOUNDED FOLLOWING——表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义
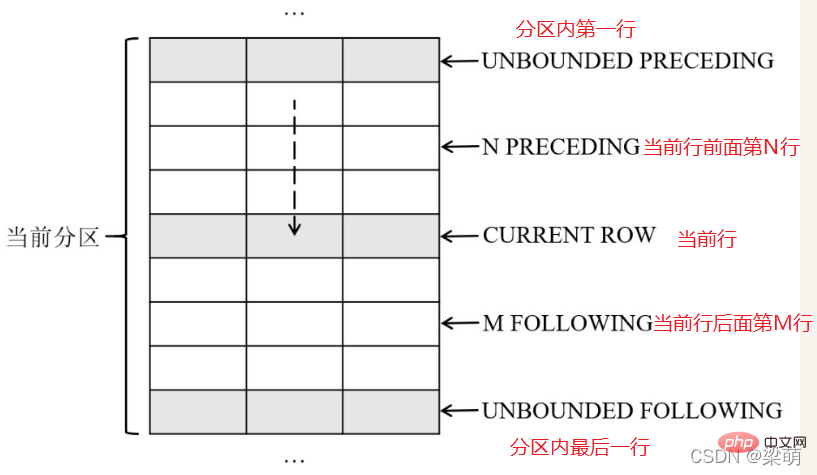
下面语句表示分析窗口从当前分区的第一行开始,直到当前行结束,即对应到图中前面5行记录。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
窗口函数分类
1.聚合窗口函数
许多常见的聚合函数也可以作为窗口函数使用,包括AVG()、SUM()、COUNT()、MAX()以及MIN()等函数。
SQL窗口函数-聚合窗口函数
2.排名窗口函数
排名窗口函数用于对数据进行分组排名,包括ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST()以及NTILE()等函数。
SQL窗口函数-排名窗口函数
3.取值窗口函数
取值窗口函数用于返回指定位置上的数据行,包括FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE()等函数。
SQL窗口函数-取值窗口函数
示例表和脚本
--员工信息表 CREATE TABLE employee ( emp_id NUMBER , emp_name VARCHAR2(50) NOT NULL , sex VARCHAR2(10) NOT NULL , dept_id INTEGER NOT NULL , manager INTEGER , hire_date DATE NOT NULL , job_id INTEGER NOT NULL , salary NUMERIC(8,2) NOT NULL , bonus NUMERIC(8,2) , email VARCHAR2(100) NOT NULL , comments VARCHAR2(500) , create_by VARCHAR2(50) NOT NULL , create_ts TIMESTAMP NOT NULL , update_by VARCHAR2(50) , update_ts TIMESTAMP ) ; COMMENT ON TABLE employee IS '员工信息表'; COMMENT ON COLUMN employee.emp_id IS '员工编号,自增主键'; COMMENT ON COLUMN employee.emp_name IS '员工姓名'; COMMENT ON COLUMN employee.sex IS '性别'; COMMENT ON COLUMN employee.dept_id IS '部门编号'; COMMENT ON COLUMN employee.manager IS '上级经理'; COMMENT ON COLUMN employee.hire_date IS '入职日期'; COMMENT ON COLUMN employee.job_id IS '职位编号'; COMMENT ON COLUMN employee.salary IS '月薪'; COMMENT ON COLUMN employee.bonus IS '年终奖金'; COMMENT ON COLUMN employee.email IS '电子邮箱'; COMMENT ON COLUMN employee.comments IS '备注信息'; COMMENT ON COLUMN employee.create_by IS '创建者'; COMMENT ON COLUMN employee.create_ts IS '创建时间'; COMMENT ON COLUMN employee.update_by IS '修改者'; COMMENT ON COLUMN employee.update_ts IS '修改时间'; INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (1,'刘备', '男', 1, NULL, DATE '2000-01-01', 1, 30000, 10000, 'liubei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (2,'关羽', '男', 1, 1, DATE '2000-01-01', 2, 26000, 10000, 'guanyu@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (3,'张飞', '男', 1, 1, DATE '2000-01-01', 2, 24000, 10000, 'zhangfei@shuguo.com', NULL, 'Admin', TIMESTAMP '2000-01-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (4,'诸葛亮', '男', 2, 1, DATE '2006-03-15', 3, 24000, 8000, 'zhugeliang@shuguo.com', NULL, 'Admin', TIMESTAMP '2006-03-15 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (5,'黄忠', '男', 2, 4, DATE '2008-10-25', 4, 8000, NULL, 'huangzhong@shuguo.com', NULL, 'Admin', TIMESTAMP '2008-10-25 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (6,'魏延', '男', 2, 4, DATE '2007-04-01', 4, 7500, NULL, 'weiyan@shuguo.com', NULL, 'Admin', TIMESTAMP '2007-04-01 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (7,'孙尚香', '女', 3, 1, DATE '2002-08-08', 5, 12000, 5000, 'sunshangxiang@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (8,'孙丫鬟', '女', 3, 7, DATE '2002-08-08', 6, 6000, NULL, 'sunyahuan@shuguo.com', NULL, 'Admin', TIMESTAMP '2002-08-08 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (9,'赵云', '男', 4, 1, DATE '2005-12-19', 7, 15000, 6000, 'zhaoyun@shuguo.com', NULL, 'Admin', TIMESTAMP '2005-12-19 10:00:00', 'Admin', TIMESTAMP '2006-12-31 10:00:00'); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (10,'廖化', '男', 4, 9, DATE '2009-02-17', 8, 6500, NULL, 'liaohua@shuguo.com', NULL, 'Admin', TIMESTAMP '2009-02-17 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (11,'关平', '男', 4, 9, DATE '2011-07-24', 8, 6800, NULL, 'guanping@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-24 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (12,'赵氏', '女', 4, 9, DATE '2011-11-10', 8, 6600, NULL, 'zhaoshi@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-11-10 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (13,'关兴', '男', 4, 9, DATE '2011-07-30', 8, 7000, NULL, 'guanxing@shuguo.com', NULL, 'Admin', TIMESTAMP '2011-07-30 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (14,'张苞', '男', 4, 9, DATE '2012-05-31', 8, 6500, NULL, 'zhangbao@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-31 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (15,'赵统', '男', 4, 9, DATE '2012-05-03', 8, 6000, NULL, 'zhaotong@shuguo.com', NULL, 'Admin', TIMESTAMP '2012-05-03 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (16,'周仓', '男', 4, 9, DATE '2010-02-20', 8, 8000, NULL, 'zhoucang@shuguo.com', NULL, 'Admin', TIMESTAMP '2010-02-20 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (17,'马岱', '男', 4, 9, DATE '2014-09-16', 8, 5800, NULL, 'madai@shuguo.com', NULL, 'Admin', TIMESTAMP '2014-09-16 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (18,'法正', '男', 5, 2, DATE '2017-04-09', 9, 10000, 5000, 'fazheng@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-04-09 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (19,'庞统', '男', 5, 18, DATE '2017-06-06', 10, 4100, 2000, 'pangtong@shuguo.com', NULL, 'Admin', TIMESTAMP '2017-06-06 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (20,'蒋琬', '男', 5, 18, DATE '2018-01-28', 10, 4000, 1500, 'jiangwan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-01-28 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (21,'黄权', '男', 5, 18, DATE '2018-03-14', 10, 4200, NULL, 'huangquan@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-14 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (22,'糜竺', '男', 5, 18, DATE '2018-03-27', 10, 4300, NULL, 'mizhu@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-03-27 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (23,'邓芝', '男', 5, 18, DATE '2018-11-11', 10, 4000, NULL, 'dengzhi@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-11-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (24,'简雍', '男', 5, 18, DATE '2019-05-11', 10, 4800, NULL, 'jianyong@shuguo.com', NULL, 'Admin', TIMESTAMP '2019-05-11 10:00:00', NULL, NULL); INSERT INTO employee(EMP_ID,emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email, comments, create_by, create_ts, update_by, update_ts) VALUES (25,'孙乾', '男', 5, 18, DATE '2018-10-09', 10, 4700, NULL, 'sunqian@shuguo.com', NULL, 'Admin', TIMESTAMP '2018-10-09 10:00:00', NULL, NULL);
推荐学习:《SQL教程》
The above is the detailed content of Detailed explanation of SQL window functions in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
HQL and SQL are compared in the Hibernate framework: HQL (1. Object-oriented syntax, 2. Database-independent queries, 3. Type safety), while SQL directly operates the database (1. Database-independent standards, 2. Complex executable queries and data manipulation).
 Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Usage of Division Operation in OracleSQL" In OracleSQL, division operation is one of the common mathematical operations. During data query and processing, division operations can help us calculate the ratio between fields or derive the logical relationship between specific values. This article will introduce the usage of division operation in OracleSQL and provide specific code examples. 1. Two ways of division operations in OracleSQL In OracleSQL, division operations can be performed in two different ways.
 Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Oracle and DB2 are two commonly used relational database management systems, each of which has its own unique SQL syntax and characteristics. This article will compare and differ between the SQL syntax of Oracle and DB2, and provide specific code examples. Database connection In Oracle, use the following statement to connect to the database: CONNECTusername/password@database. In DB2, the statement to connect to the database is as follows: CONNECTTOdataba
 Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Interpretation of MyBatis dynamic SQL tags: Detailed explanation of Set tag usage MyBatis is an excellent persistence layer framework. It provides a wealth of dynamic SQL tags and can flexibly construct database operation statements. Among them, the Set tag is used to generate the SET clause in the UPDATE statement, which is very commonly used in update operations. This article will explain in detail the usage of the Set tag in MyBatis and demonstrate its functionality through specific code examples. What is Set tag Set tag is used in MyBati
 What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What is Identity in SQL? Specific code examples are needed. In SQL, Identity is a special data type used to generate auto-incrementing numbers. It is often used to uniquely identify each row of data in a table. The Identity column is often used in conjunction with the primary key column to ensure that each record has a unique identifier. This article will detail how to use Identity and some practical code examples. The basic way to use Identity is to use Identit when creating a table.
 How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
When Springboot+Mybatis-plus does not use SQL statements to perform multi-table adding operations, the problems I encountered are decomposed by simulating thinking in the test environment: Create a BrandDTO object with parameters to simulate passing parameters to the background. We all know that it is extremely difficult to perform multi-table operations in Mybatis-plus. If you do not use tools such as Mybatis-plus-join, you can only configure the corresponding Mapper.xml file and configure The smelly and long ResultMap, and then write the corresponding sql statement. Although this method seems cumbersome, it is highly flexible and allows us to
 How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
Solution: 1. Check whether the logged-in user has sufficient permissions to access or operate the database, and ensure that the user has the correct permissions; 2. Check whether the account of the SQL Server service has permission to access the specified file or folder, and ensure that the account Have sufficient permissions to read and write the file or folder; 3. Check whether the specified database file has been opened or locked by other processes, try to close or release the file, and rerun the query; 4. Try as administrator Run Management Studio as etc.
 How to use SQL statements for data aggregation and statistics in MySQL?
Dec 17, 2023 am 08:41 AM
How to use SQL statements for data aggregation and statistics in MySQL?
Dec 17, 2023 am 08:41 AM
How to use SQL statements for data aggregation and statistics in MySQL? Data aggregation and statistics are very important steps when performing data analysis and statistics. As a powerful relational database management system, MySQL provides a wealth of aggregation and statistical functions, which can easily perform data aggregation and statistical operations. This article will introduce the method of using SQL statements to perform data aggregation and statistics in MySQL, and provide specific code examples. 1. Use the COUNT function for counting. The COUNT function is the most commonly used
