

Completely master Oracle advanced learning to view execution plan

This article brings you relevant knowledge about Oracle, which mainly introduces the related issues of viewing execution plans. I hope it will be helpful to everyone.

Recommended tutorial: "Oracle Video Tutorial"
Today we will talk about the way Oracle views execution plans and how to view execution plan.
1. How to view the execution plan
1.1. Set autotrace
The autotrace command is as follows
Serial number |
Command |
##Explanation |
| 1 | SET AUTOTRACE OFF | This is the default value, which means Autotrace is turned off |
| 2 | SET AUTOTRACE ON EXPLAIN | Display only execution plan |
| SET AUTOTRACE ON STATISTICS | Display execution only Statistics for | |
| SET AUTOTRACE ON | contains 2 and 3 items | ##5 |
| ##SET AUTOTRACE TRACEONLY | Similar to ON, but does not display the execution results of the statement |
1.2. Use third-party toolssuch as the explain window of PL/SQL Develop
It is said that adding EXPLAIN PLAN FOR before the executed SQL can check the execution plan. I haven’t figured it out yet. I will add for example:SQL> EXPLAIN PLAN FOR SELECT * FROM EMP; Copy after login SQL> SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE')); Copy after login SQL> select * from table(dbms_xplan.display); Copy after login ALTER SYSTEM FLUSH SHARED_POOL; ALTER SYSTEM FLUSH BUFFER_CACHE; ALTER SYSTEM FLUSH GLOBAL CONTEXT; Copy after login CREATE TABLE CUST_INFO (CST_NO NUMBER, CST_NAME VARCHAR2(50), AGE SMALLINT); CREATE TABLE CST_TRAN ( CST_NO NUMBER, TRAN_DATE VARCHAR2(8), TRAN_AMT NUMBER(19,3) ); Copy after login INSERT INTO CUST_INFO
SELECT 100000+LEVEL,
'test'||LEVEL,
ROUND(DBMS_RANDOM.VALUE(1,100))
FROM DUAL
CONNECT BY LEVEL<=10000;
INSERT INTO CST_TRAN
WITH AA AS
(SELECT LEVEL FROM DUAL CONNECT BY LEVEL<=100)
SELECT T.CST_NO,
TO_CHAR(SYSDATE - DBMS_RANDOM.VALUE(1,1000),'yyyymmdd'),
ROUND(DBMS_RANDOM.VALUE(1,999999999),3)
FROM CUST_INFO T
INNER JOIN AA
ON 1=1;Copy after login SQL> SELECT T.CST_NO, T.CST_NAME, G.TRAN_DATE, G.TRAN_AMT FROM CUST_INFO T INNER JOIN CST_TRAN G ON G.CST_NO = T.CST_NO;
1000000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2290587575
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 |
|* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 |
| 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("G"."CST_NO"="T"."CST_NO")
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
561 recursive calls
0 db block gets
70483 consistent gets
4389 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
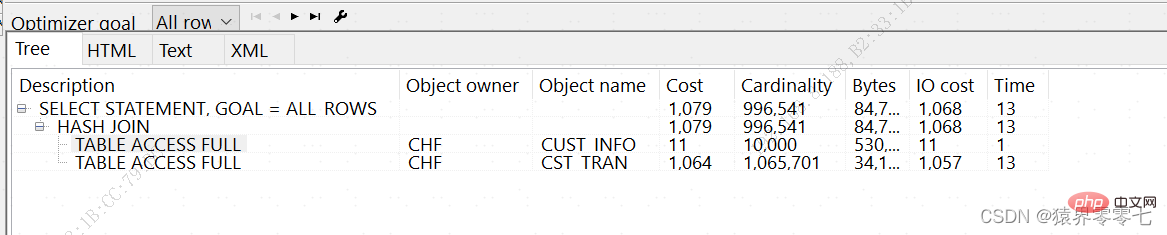
1000000 rows processedCopy after login -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 | |* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 | | 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 | -------------------------------------------------------------------------------- Copy after login Explanation of the fields in the execution plan: ## ID: A serial number, but not the order of execution. The order of execution is judged based on indentation.
1. Operation Record the operations of each step, and judge the order of execution according to the degree of indentation. In OLAP databases, there are many HASH JOIN connections, especially when the returned data set is large, they are basically HASH JOIN. 2. Rows The rows value indicates the number of records that CBO expects to return from a row source. This row source may be a table, an index, or a subquery. . In the execution plan in Oracle 9i, Cardinality is abbreviated as Card. In 10g, Card values are replaced by rows. The rowsvalue is crucial for CBO to make a correct execution plan. If the rows value obtained by CBO is not accurate enough (usually due to lack of analysis or outdated analysis data), there will be deviations in the execution plan cost calculation, which will lead to CBO incorrectly formulating an execution plan. When there is a multi-table related query or a subquery in SQL, the rows value of each related table or subquery has a great impact on the main query. It can even be said that CBO depends on each related table. Or the subquery rows value calculates the final execution plan. For multi-table queries, CBO uses the number of rows (rows) returned by each associated table to determine what access method to use for table association (such as Nested loops Join or hash Join) 3. Cost (CPU) and Time are important reference values for the execution plan 3.2.2. Predicate description:Predicate Information (identified by operation id):------------------------------------------------ ---
Note ----- - dynamic sampling used for this statement (level=2) Filter: Indicates that the value of the predicate condition will not affect the access path of the data and only plays a filtering role. (Not in this example) Note: Pay attention toaccess in the predicate. You must consider the conditions of the predicate and whether the access path used is correct. 参数说明: 这个指标的计算方式和一个参数息息相关,arraysize。 arraysize是什么呢? 请查阅大牛博文:Oracle arraysize 和 fetch size 参数 与 性能优化 说明 arraysize定义了一次返回到客户端的行数,取值范围【1-5000】,默认15。 使用命令在数据库中查看arraysize的值。 show arraysize 还可以修改这个值 set arraysize 5000; 明白了arraysize这个参数就可以计算SQL*Net roundtrips to/from client的值了。上例中,返回客户端结果集的行数是1000000,默认arraysize值是15,1000000/15向上取整等于66667。 为啥要向上取整? 举个栗子,如果有10个苹果,一个只能拿3个,几次可以拿完,3次可以拿9个,还剩1个,所以还需要再拿一次,共4次。 统计分析中的值是66668,为什么我们计算的值是66667? 就要看这个指标本身了,再粘贴一次:SQL*Net roundtrips to/from client 重点看from,意思是我们还要接受一次客户端发来的SQL语句,因此是:66667+1,本问题纯属个人臆断,无真凭实据,受限于本人的知识水平,如有误,请指出。 将arraysize的值修改为5000后,再观察SQL*Net roundtrips to/from client的变化,结果为201。 前面提到 arraysize的取值范围是【1-5000】,我们可以试一下改为不在这个区间的值,比如改为0,结果报错了 译为中文就是:一致性读, 好抽象的一个指标,啥叫一致性读,心中无数羊驼驼在大海中狂奔。 官网对consistent gets 的解释: consistent gets:Number of times a consistent read wasrequested for a block. 通常我们执行SQL查询时涉及的每一block都是Consistent Read, 只是有些CR(Consistent Read)需要使用undo 来进行构造, 大部分CR(Consistent Read)并不涉及到undo block的读. 还有就是每次读这个block都是一次CR(可能每个block上有多个数据row), 也就是如果某个block被读了10次, 系统会记录10个Consistent Read. 如果想深入学习,请参考大佬博文:Oracle 有关 Consistent gets 的测试 -- cnDBA.cn_中国DBA社区 接来下测试下, consistent gets是从哪来的,需要使用有sysdba权限的用户,因为oradebug工具需要sysdba权限。 oradebug工具介绍:oracle实用工具:oradebug 使用10046对同一条数据跟踪两次,注意观察 consistent gets的不同 为了不影响测试结果,首先清空缓存 第一次执行 第二次执行 通过对比两次执行,发现consistent gets、physical reads、sorts (memory)都有变化,这是因为SGA中已经缓存了部分数据块。 再对比下我们刚才生产的两个跟踪日志,为方便查看,先将其格式转换以下 打开 /u01/chf1.trc,下面贴出部分重要信息 打开 /u01/chf2.trc,下面贴出部分重要信息 比较发现,第一次执行解析SQL语句,生产执行计划时,consistent gets发生67次,执行SQL语句时发生70301。第一次执行解析SQL语句,生产执行计划时,因已经有缓存,所以consistent gets发生0次,执行SQL语句时发生70301。 推荐教程:《Oracle视频教程》 |
The above is the detailed content of Completely master Oracle advanced learning to view execution plan. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What to do if the oracle can't be opened
Apr 11, 2025 pm 10:06 PM
What to do if the oracle can't be opened
Apr 11, 2025 pm 10:06 PM
Solutions to Oracle cannot be opened include: 1. Start the database service; 2. Start the listener; 3. Check port conflicts; 4. Set environment variables correctly; 5. Make sure the firewall or antivirus software does not block the connection; 6. Check whether the server is closed; 7. Use RMAN to recover corrupt files; 8. Check whether the TNS service name is correct; 9. Check network connection; 10. Reinstall Oracle software.
 How to solve the problem of closing oracle cursor
Apr 11, 2025 pm 10:18 PM
How to solve the problem of closing oracle cursor
Apr 11, 2025 pm 10:18 PM
The method to solve the Oracle cursor closure problem includes: explicitly closing the cursor using the CLOSE statement. Declare the cursor in the FOR UPDATE clause so that it automatically closes after the scope is ended. Declare the cursor in the USING clause so that it automatically closes when the associated PL/SQL variable is closed. Use exception handling to ensure that the cursor is closed in any exception situation. Use the connection pool to automatically close the cursor. Disable automatic submission and delay cursor closing.
 How to paginate oracle database
Apr 11, 2025 pm 08:42 PM
How to paginate oracle database
Apr 11, 2025 pm 08:42 PM
Oracle database paging uses ROWNUM pseudo-columns or FETCH statements to implement: ROWNUM pseudo-columns are used to filter results by row numbers and are suitable for complex queries. The FETCH statement is used to get the specified number of first rows and is suitable for simple queries.
 How to create cursors in oracle loop
Apr 12, 2025 am 06:18 AM
How to create cursors in oracle loop
Apr 12, 2025 am 06:18 AM
In Oracle, the FOR LOOP loop can create cursors dynamically. The steps are: 1. Define the cursor type; 2. Create the loop; 3. Create the cursor dynamically; 4. Execute the cursor; 5. Close the cursor. Example: A cursor can be created cycle-by-circuit to display the names and salaries of the top 10 employees.
 How to stop oracle database
Apr 12, 2025 am 06:12 AM
How to stop oracle database
Apr 12, 2025 am 06:12 AM
To stop an Oracle database, perform the following steps: 1. Connect to the database; 2. Shutdown immediately; 3. Shutdown abort completely.
 What steps are required to configure CentOS in HDFS
Apr 14, 2025 pm 06:42 PM
What steps are required to configure CentOS in HDFS
Apr 14, 2025 pm 06:42 PM
Building a Hadoop Distributed File System (HDFS) on a CentOS system requires multiple steps. This article provides a brief configuration guide. 1. Prepare to install JDK in the early stage: Install JavaDevelopmentKit (JDK) on all nodes, and the version must be compatible with Hadoop. The installation package can be downloaded from the Oracle official website. Environment variable configuration: Edit /etc/profile file, set Java and Hadoop environment variables, so that the system can find the installation path of JDK and Hadoop. 2. Security configuration: SSH password-free login to generate SSH key: Use the ssh-keygen command on each node
 How to create oracle dynamic sql
Apr 12, 2025 am 06:06 AM
How to create oracle dynamic sql
Apr 12, 2025 am 06:06 AM
SQL statements can be created and executed based on runtime input by using Oracle's dynamic SQL. The steps include: preparing an empty string variable to store dynamically generated SQL statements. Use the EXECUTE IMMEDIATE or PREPARE statement to compile and execute dynamic SQL statements. Use bind variable to pass user input or other dynamic values to dynamic SQL. Use EXECUTE IMMEDIATE or EXECUTE to execute dynamic SQL statements.
 How to open a database in oracle
Apr 11, 2025 pm 10:51 PM
How to open a database in oracle
Apr 11, 2025 pm 10:51 PM
The steps to open an Oracle database are as follows: Open the Oracle database client and connect to the database server: connect username/password@servername Use the SQLPLUS command to open the database: SQLPLUS
