

shock! There are so many locks in one SQL statement...


Recommended (free): SQL tutorial
Gap lock plus row lock, it is easy to judge whether An error occurred when a lock wait problem occurred.
Because gap locks are only effective under the repeatable read isolation level, this article defaults to repeatable read.
Lock rules
- Principle 1
The basic unit of locking is next-key lock, which is an open and closed interval. - Principle 2
Only objects accessed during the search process will be locked. - Optimization 1
For equivalent queries on the index, when locking the unique index, the next-key lock degenerates into a row lock. - Optimization 2
For equivalent queries on the index, when traversing to the right and the last value does not meet the equality condition, the next-key lock degenerates into a gap lock. - A bug
A range query on a unique index will access the first value that does not meet the condition.
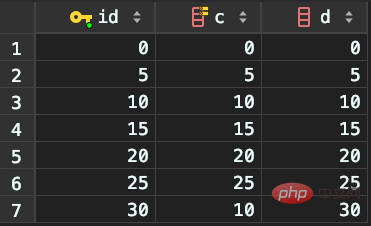
Data preparation
Table name: t
New data: (0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25)
The following examples are basically illustrated with pictures, so I recommend You can read it against the manuscript. Some examples may "destroy the three views." It is also recommended that you practice it yourself after reading the article.
Case
Equal value query gap lock
Equal value query gap lock

There is no id=7 in table t, so according to principle 1, the locking unit is next-key lock, so the locking range of session A is (5,10]
-
At the same time, according to optimization 2, equivalent query (id=7), but id=10 is not satisfied, the next-key lock degenerates into a gap lock, so the final lock range (5,10)

So, if session B inserts the record with id=8 into this gap, it will be locked, but session C can modify the line with id=10.
Non-unique index equivalent lock
Lock only added to non-unique index
session A wants to add a read lock to the row c=5 of index c
According to principle 1, the locking unit is next-key lock, so add next-key lock to (0,5]
c is normal Index , so only the record c=5 is accessed. cannot stop immediately . It needs to traverse to the right and give up only when c=10 is found. According to principle 2, access must be locked, so (5,10] needs to be added with next-key lock
and it also conforms to optimization 2: equivalence judgment, traverse to the right, the last value does not meet the equivalence condition of c=5, so it is degraded Gap lock (5,10)
According to principle 2, only the accessed object will be locked. This query uses a covering index and does not need to access the primary key index, so no lock is added to the primary key index, so session B The update statement can be executed.
But if session C wants to insert (7,7,7), it will be locked by the gap lock (5,10) of session A.
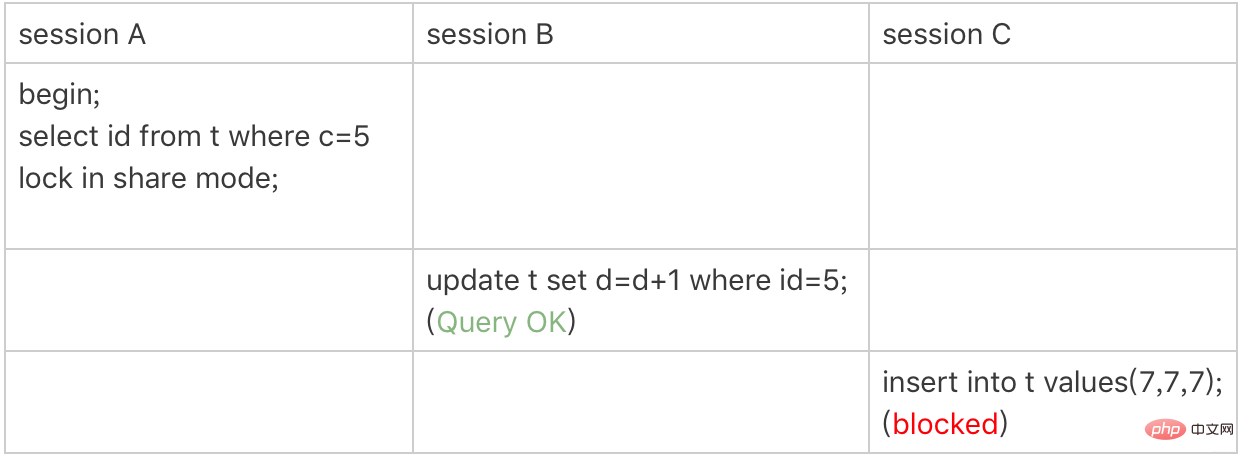
In this example, lock in share mode only locks the covering index, but it is different if it is for update. When executing for update, the system will think that you want to update the data next, so it will give the rows that meet the conditions on the primary key index. Add a row lock.
This example shows that the lock is added to the index; at the same time, it gives us guidance if you want to use lock in share mode to add a read lock to the row to prevent the data from being updated. , you must bypass the optimization of the covering index and add fields that do not exist in the index to the query fields. For example, change the query statement of session A to select d from t where c=5 lock in share mode. You can verify it yourself Here's the effect.
3 Primary key index range lock
Range query.
For our table t, do the following two query statements have the same locking range?
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
You may think, id definition Being of type int, these two statements are equivalent, right? In fact, they are not completely equivalent.
Logically, these two query statements are definitely equivalent, but their locking rules are different. Now, let's let session A execute the second query statement to see the locking effect.
Figure 3 Locks for range queries on the primary key index
Now we will use the locking rules mentioned above to analyze what locks will be added to session A?
When starting execution, we need to find the first row with id=10, so it should be next-key lock(5,10]. According to optimization 1, the equivalent condition on the primary key id degenerates into a row Lock, only the row lock for the row with id=10 is added.
The range search continues to search later, and stops when the row with id=15 is found, so next-key lock(10,15] needs to be added.
So, the lock scope of session A at this time is the primary key index, row lock id=10 and next-key lock(10,15]. In this way, you can understand the results of session B and session C. .
You need to pay attention to one thing here. When session A locates the row with id=10 for the first time, it is judged as an equivalent query. When scanning to the right to id=15, the range is used. Query and judge.
Let’s look at range query locking again. You can compare it with Case 3
Non-unique index range lock
| session_1 | session_2 | session_3 |
|---|---|---|
| select * from t where c>=10 and c<11 for update; | ||
##insert into t values(8,8 ,8);(blocked) | ||
| ##update t set d =d 1 where c=15;(blocked) |
- to locate the record for the first time, index c Added
- (5,10) next-key lock
c is anon-unique index , there is no optimization rule, that is, it will not degenerate into a row lock - So session1 is finally locked as (5,10] and
- (10,15]
next-key lock of c.So from Judging from the results, sesson2 was blocked when it wanted to insert the insert statement of (8,8,8).
Unique index range lock bug
The first four cases use two principles and two optimizations, and then look at the locking rule bug case.
| session_3 | ||
|---|---|---|
|
|
||
| where id=20;(blocking) |
|
|
|
insert into t values(16,16,16);(blocking) |
session1 is a range query |
| begin; | delete * from t||
|---|---|---|
|
|
##insert into t | values(13,13,13);(blocking)|
|
When traversing session1, first access the first c=10: |
According to principle 1, add (c=5,id=5) to (c=10,id=10) next-key lock |
- 7 limit statement lock
session_2
| begin; | delete * from twhere c=10 limit 2 |
|---|---|
|
| # #insert into t values(13,13,13);(blocking) |
The above is the detailed content of shock! There are so many locks in one SQL statement.... For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
HQL and SQL are compared in the Hibernate framework: HQL (1. Object-oriented syntax, 2. Database-independent queries, 3. Type safety), while SQL directly operates the database (1. Database-independent standards, 2. Complex executable queries and data manipulation).
 Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Usage of Division Operation in OracleSQL" In OracleSQL, division operation is one of the common mathematical operations. During data query and processing, division operations can help us calculate the ratio between fields or derive the logical relationship between specific values. This article will introduce the usage of division operation in OracleSQL and provide specific code examples. 1. Two ways of division operations in OracleSQL In OracleSQL, division operations can be performed in two different ways.
 Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Oracle and DB2 are two commonly used relational database management systems, each of which has its own unique SQL syntax and characteristics. This article will compare and differ between the SQL syntax of Oracle and DB2, and provide specific code examples. Database connection In Oracle, use the following statement to connect to the database: CONNECTusername/password@database. In DB2, the statement to connect to the database is as follows: CONNECTTOdataba
 Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Interpretation of MyBatis dynamic SQL tags: Detailed explanation of Set tag usage MyBatis is an excellent persistence layer framework. It provides a wealth of dynamic SQL tags and can flexibly construct database operation statements. Among them, the Set tag is used to generate the SET clause in the UPDATE statement, which is very commonly used in update operations. This article will explain in detail the usage of the Set tag in MyBatis and demonstrate its functionality through specific code examples. What is Set tag Set tag is used in MyBati
 What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What is Identity in SQL? Specific code examples are needed. In SQL, Identity is a special data type used to generate auto-incrementing numbers. It is often used to uniquely identify each row of data in a table. The Identity column is often used in conjunction with the primary key column to ensure that each record has a unique identifier. This article will detail how to use Identity and some practical code examples. The basic way to use Identity is to use Identit when creating a table.
 How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
Solution: 1. Check whether the logged-in user has sufficient permissions to access or operate the database, and ensure that the user has the correct permissions; 2. Check whether the account of the SQL Server service has permission to access the specified file or folder, and ensure that the account Have sufficient permissions to read and write the file or folder; 3. Check whether the specified database file has been opened or locked by other processes, try to close or release the file, and rerun the query; 4. Try as administrator Run Management Studio as etc.
 Database technology competition: What are the differences between Oracle and SQL?
Mar 09, 2024 am 08:30 AM
Database technology competition: What are the differences between Oracle and SQL?
Mar 09, 2024 am 08:30 AM
Database technology competition: What are the differences between Oracle and SQL? In the database field, Oracle and SQL Server are two highly respected relational database management systems. Although they both belong to the category of relational databases, there are many differences between them. In this article, we will delve into the differences between Oracle and SQL Server, as well as their features and advantages in practical applications. First of all, there are differences in syntax between Oracle and SQL Server.
 How to use months_between in SQL
Jan 25, 2024 pm 03:23 PM
How to use months_between in SQL
Jan 25, 2024 pm 03:23 PM
MONTHS_BETWEEN in SQL is a common function used to calculate the month difference between two dates. How it is used depends on the specific database management system.
