

How trillions of data should be migrated

Java Basic TutorialThe column introduces how trillions of data should be migrated.

Background
There is a very famous line in Xingye's "Westward Journey": "There was once a sincere love I didn't cherish the relationship before me, and regretted it when I lost it. The most painful thing in the world is this. If God could give me another chance, I would say three words to any girl: I love you. If I have to add a time limit to this love, I hope it will be ten thousand years!" In the eyes of our developers, this feeling is the same as the data in our database. We wish it would last ten thousand years. Not changing, but often backfires. As the company continues to develop and the business continues to change, our requirements for data are also constantly changing. There are probably the following situations:
- Sub-database and sub-table: Business development is getting faster and faster, resulting in greater and greater pressure on the single-machine database, and the amount of data is also increasing. At this time, the sub-database method is usually used to solve this problem, and the database is The traffic is evenly distributed to different machines. In the process from a stand-alone database to a sub-database, we need to completely migrate our data so that we can successfully use our data in a sub-database.
- Replace the storage medium: Generally speaking, after we migrate the sub-database introduced above, the storage medium will still be the same. For example, if we used a stand-alone Mysql before, after the sub-database is It has become MySQL on multiple machines, and the fields of our database tables have not changed. The migration is relatively simple. Sometimes our sub-databases and tables cannot solve all problems. If we need a lot of complex queries, using Mysql may not be a reliable solution at this time. Then we need to replace the query storage medium, such as using elasticsearch. This This type of migration is slightly more complicated and involves data conversion from different storage media.
- Switching to a new system: Generally, when a company is developing at a high speed, there will be many projects that are repeatedly constructed for the sake of speed. When the company reaches a certain period of time, these projects will often Be merged and become a platform or middle platform, such as some of our membership systems, e-commerce systems, etc. At this time, we often face a problem. The data in the old system needs to be migrated to the new system. This time it becomes more complicated. It is possible that not only the storage medium has changed, but also the project language may be different. From the upper level From a different perspective, departments may be different, so this kind of data migration is more difficult and the risk is greater.
In actual business development, we will make different migration plans according to different situations. Next, let’s discuss how to migrate data.
Data migration
Data migration is not accomplished overnight. Each data migration takes a long time, which may be a week or several months. Generally speaking, we migrate data The process is basically similar to the picture below: 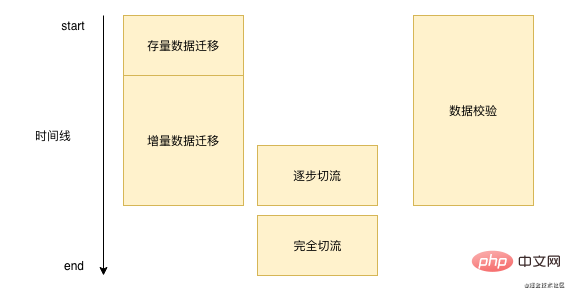 '
First, we need to batch migrate the existing data in our database, and then we need to process the new data. We need to write this part of the data to our new storage in real time after writing the original database. Here We need to continuously verify data during the process. When we verify that the basic problems are not serious, we then perform the stream cutting operation. After the stream is completely cut, we no longer need to perform data verification and incremental data migration.
'
First, we need to batch migrate the existing data in our database, and then we need to process the new data. We need to write this part of the data to our new storage in real time after writing the original database. Here We need to continuously verify data during the process. When we verify that the basic problems are not serious, we then perform the stream cutting operation. After the stream is completely cut, we no longer need to perform data verification and incremental data migration.
Stock Data Migration
First of all, let’s talk about how to do stock data migration. After searching for stock data migration in the open source community, we found that there is no easy-to-use tool. At present, Alibaba The cloud's DTS provides existing data migration. DTS supports migration between homogeneous and heterogeneous data sources, and basically supports common databases in the industry such as Mysql, Orcale, SQL Server, etc. DTS is more suitable for the first two scenarios we mentioned before. One is the scenario of sub-database. If you are using Alibaba Cloud's DRDS, you can directly migrate the data to DRDS through DTS. The other is the scenario of heterogeneous data, whether it is Redis, ES, and DTS all support direct migration.
So how to migrate DTS stock? In fact, it is relatively simple and probably consists of the following steps:
- When the stock migration task is started, we obtain the largest id and minimum id that currently need to be migrated
- Set a segment, For example, 10,000, query 10,000 data each time starting from the smallest ID, and send it to the DTS server for processing. The sql is as follows:
select * from table_name where id > curId and id < curId + 10000;复制代码
3. When the id is greater than or equal to maxId, the existing data migration task ends
Of course we may not use Alibaba Cloud during the actual migration process, or in our third scenario, we need to do a lot of conversions between database fields, and DTS does not support it, then we can imitate DTS's approach is to migrate data by reading data in batches in segments. What needs to be noted here is that when we migrate data in batches, we need to control the size and frequency of segments to prevent them from affecting the normal operation of our online operations.
Incremental data migration
The migration solutions for existing data are relatively limited, but incremental data migration methods are in full bloom. Generally speaking, we have the following methods:
- DTS: Alibaba Cloud's DTS is considered a one-stop service. It not only provides stock data migration, but also provides incremental data migration, but it needs to be charged based on volume.
- Service double-write: It is more suitable for migration without system switching, that is, only the storage is changed but the system is still the same, such as sub-database and table, redis data synchronization, etc. This method is relatively simple and straightforward. The data that needs to be migrated is written synchronously in the code, but since it is not the same database, transactions cannot be guaranteed, which may cause data loss when migrating data. This process will be solved through subsequent data verification.
- MQ asynchronous writing: This can be applied to all scenarios. When data is modified, an MQ message is sent, and the consumer updates the data after receiving the message. This is somewhat similar to the double write above, but it changes the database operation to MQ asynchronous, and the probability of problems will be much smaller.
- Monitoring binlog: We can use the canal mentioned before or some other Open source such as databus performs binlog monitoring. The method of monitoring binlog is the same as the message MQ method above, except that the step of sending messages has been omitted. The amount of development in this method is basically minimal.
With so many methods, which one should we use? Personally, I recommend the method of monitoring binlog. Monitoring binlog reduces development costs. We only need to implement the consumer logic, and the data can ensure consistency. Because it is a monitored binlog, there is no need to worry about the previous double writing being different. business issues.
Data verification
All the solutions mentioned above, although many of them are mature cloud services (dts) or middleware (canal), may cause some data loss. Data loss is relatively rare overall, but it is very difficult to troubleshoot. It may be that the dts or canal accidentally shook, or the data was accidentally lost when receiving data. Since we have no way to prevent our data from being lost during the migration process, we should correct it by other means.
Generally speaking, when we migrate data, there will be a step of data verification, but different teams may choose different data verification solutions:
- Before, in Meituan When , we will do a double read, that is, all our reads will read a copy from the new one, but the returned one is still the old one. At this time, we need to verify this part of the data. If there is any problem, we can send it out Alarm for manual repair or automatic repair. In this way, our commonly used data can be quickly repaired. Of course, we will also run a full data check from time to time, but the time for this kind of check to repair the data is relatively lagging.
- Now after Yuanfudao, we have not adopted the previous method, because although double-reading check can quickly find errors in the data, we do not have such a high level of real-time correction of this part of the data. The amount of code development for verification and double reading is still relatively large, but it cannot be guaranteed by full checks from time to time, which will cause our data verification time to be extremely extended. We adopted a compromise method. We borrowed an idea from T 1 in the reconciliation. We obtained the data updated yesterday in the old database every morning, and then compared it one by one with the data in our new database. If there is any If the data is different or missing, we can repair it immediately.
Of course, we also need to pay attention to the following points during the actual development process:
- How to ensure the correctness of the data verification task? The verification task is originally to correct other data, but if there is a problem with it itself, the meaning of verification will be lost. Currently, we can only Rely on reviewing the code to ensure the correctness of the verification task.
- When verifying the task, you need to pay attention to the printing of logs. Sometimes problems may be caused by direct problems with all data. Then the verification task may print a large number of error logs, and then alarm, which may Hang the system, or affect other people's services. If you want to make it simpler here, you can turn some non-manually processed alarms into warnings. If you want to make it more complicated, you can encapsulate a tool. When a certain error print exceeds a certain amount in a certain period of time, there is no need to print it again.
- Be careful not to affect the online running services of the verification task. Usually, the verification task will write many batch query statements, and batch table scanning will occur. If the code is not written well, it can easily cause the database to hang.
Stream cutting
When our data verification basically has no errors, it means that our migration program is relatively stable, then we can use our new data directly ? Of course it's not possible. If we switch it all at once, it will be great if it goes well. But if something goes wrong, it will affect all users.
So we need to perform grayscale next, which is stream cutting. The dimensions of different business flow cuts will be different. For user dimension flow cuts, we usually use the modulo method of userId to cut flows. For tenant or merchant dimension businesses, we need to take the modulo of the tenant id. way to cut the flow. For this traffic cutting, you need to make a traffic cutting plan, in what time period, how much traffic to release, and when cutting traffic, you must choose a time when the traffic is relatively small. Every time you cut traffic, you need to make detailed observations of the logs. , fix problems as soon as possible. The process of releasing traffic is a process from slow to fast. For example, at the beginning, it is continuously superimposed at 1%. Later, we directly use 10% or 20% to quickly Increase the volume. Because if there is a problem, it will often be discovered when the traffic is small. If there is no problem with the small traffic, then the volume can be increased quickly.
Pay attention to the primary key ID
In the process of migrating data, special attention should be paid to the primary key ID. In the double-writing solution above, it is also mentioned that the primary key ID needs to be double-written manually. Specify to prevent ID generation sequence errors.
If we are migrating because of sub-databases and tables, we need to consider that our future primary key ID cannot be an auto-increment ID, and we need to use distributed IDs. The more recommended one here is Meituan’s open source leaf. It supports two modes. One is the snowflake algorithm trend increasing, but all ids are Long type, which is suitable for some applications that support Long as id. There is also a number segment mode, which will continue to increase from above based on a basic ID you set. And basically all use memory generation, and the performance is also very fast.
Of course, we still have a situation where we need to migrate the system. The primary key id of the previous system already exists in the new system, so our id needs to be mapped. If we already know which systems will be migrated in the future when migrating the system, we can use the reservation method. For example, the current data of system A is 100 million to 100 million, and the data of system B is also 100 million to 100 million. We Now we need to merge the two systems A and B into a new system, then we can slightly estimate some Buffer, for example, leave 100 to 150 million for system A, so that A does not need to be mapped, and system B is 150 million to 300 million. Then when we convert to the old system ID, we need to subtract 150 million. Finally, the new ID of our new system will increase from 300 million. But what if there is no planned reserved segment in the system? You can do this in the following two ways:
- It is necessary to add a new table and make a mapping record between the id of the old system and the id of the new system. This workload is still relatively large, because our general migration will involve dozens or hundreds of tables and records. The cost is still very high.
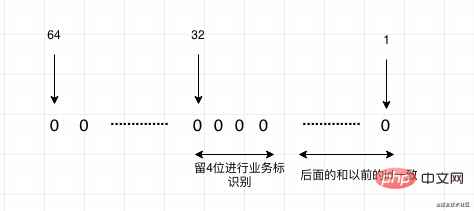
- If the id is of Long type, we can make good use of the fact that long is 64 bits. We can formulate a rule. The ids of our new system will start from a relatively large number, such as greater than Int. Starting from counting, the part of the small Int can be left to our old system for ID migration. For example, the 150 million data volume above us actually only uses 28 bits. Our Int is 32 bits, so there are still 4 Bits can be used, and these 4 bits can represent 16 systems for migration. Of course, if there are more systems to be migrated in the plan, the ID starting point of the new system can be set larger. As shown in the figure below:

Summary
Finally, let’s briefly summarize this routine. It is actually four steps. One note: stock, increment, verification, and cut. Stream, finally pay attention to the id. No matter how large the amount of data is, basically there will be no big problems when migrating according to this routine. I hope this article can help you in your subsequent data migration work.
If you think this article is helpful to you, your attention and forwarding are the greatest support for me, O(∩_∩)O:
Related free learning recommendations: java basic tutorial
The above is the detailed content of How trillions of data should be migrated. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Easy to do! Data migration guide for new and old Huawei mobile phones
Mar 23, 2024 pm 01:54 PM
Easy to do! Data migration guide for new and old Huawei mobile phones
Mar 23, 2024 pm 01:54 PM
In today's society, mobile phones have become an indispensable part of people's lives, and with the rapid development of technology, mobile phone updates are becoming more and more frequent. When we buy a new Huawei mobile phone, one of the most vexing issues is how to smoothly migrate important data from the old phone to the new phone. As a leading domestic communications equipment manufacturer, Huawei's own data migration tools can solve this problem. This article will introduce in detail how to use the data migration tool officially provided by Huawei mobile phones to easily migrate old and new phones.
 MySql data migration and synchronization: How to achieve MySQL data migration and synchronization between multiple servers
Jun 15, 2023 pm 07:48 PM
MySql data migration and synchronization: How to achieve MySQL data migration and synchronization between multiple servers
Jun 15, 2023 pm 07:48 PM
MySQL is a very popular open source relational database management system that is widely used in various web applications, enterprise systems, etc. In modern business application scenarios, most MySQL databases need to be deployed on multiple servers to provide higher availability and performance, which requires MySQL data migration and synchronization. This article will introduce how to implement MySQL data migration and synchronization between multiple servers. 1. MySQL data migration MySQL data migration refers to the data migration in the MySQL server.
 Data Migration and Population with Laravel: Flexibly Manage Database Structure
Aug 26, 2023 am 09:28 AM
Data Migration and Population with Laravel: Flexibly Manage Database Structure
Aug 26, 2023 am 09:28 AM
Using Laravel for data migration and filling: Flexible management of database structure Summary: Laravel is a very popular PHP framework that provides a convenient way to manage database structure, including data migration and data filling. In this article, we'll cover how to use Laravel's migrate and populate features to flexibly manage your database structure. 1. Data migration Data migration is a tool used to manage changes in database structure. It allows you to use PHP code to define and modify database tables, columns, indexes, constraints, etc.
 Data migration library in PHP8.0: Phinx
May 14, 2023 am 10:40 AM
Data migration library in PHP8.0: Phinx
May 14, 2023 am 10:40 AM
With the development of Internet technology and the continuous expansion of its application scope, data migration has become more and more common and important. Data migration refers to the process of moving existing database structures and data to a different environment or new system. The process of data migration can include from one database engine to another database engine, from one database version to another database version, different database instances, or from one server to another server. In the field of PHP development, Phinx is a widely used data migration library. Phinx support number
 Microservice data synchronization and data migration tool written in Java
Aug 09, 2023 pm 05:15 PM
Microservice data synchronization and data migration tool written in Java
Aug 09, 2023 pm 05:15 PM
Microservice data synchronization and data migration tools written in Java In today's Internet era, microservice architecture has become a widely used design pattern. In a microservices architecture, data synchronization and migration between services has become a critical task. In order to solve this problem, we can use Java to write a simple and powerful microservice data synchronization and data migration tool. In this article, I will detail how to write this tool in Java and provide some code examples. Preparation work First, we need to prepare some
 How to switch from PC to Mac and migrate data from Windows to macOS
May 10, 2023 pm 04:28 PM
How to switch from PC to Mac and migrate data from Windows to macOS
May 10, 2023 pm 04:28 PM
For people who are unfamiliar with Apple's operating system, macOS, moving from Windows to Mac can be a great but intimidating idea. Here's everything potential PC to Mac switchers should consider when making the platform jump. People switch platforms for many different reasons, from frustration with their existing environment to a need to move for work or simple curiosity. In some cases, the switch may be forced on unsuspecting users, such as if a family member gave them a Mac. Whatever your reasons for moving from Windows to Mac, the decision to do so is only the first step. Next, you must migrate your computing environment from Windows to a new and unfamiliar environment. it seems
 How to quickly import old phone data to Huawei mobile phones?
Mar 23, 2024 pm 10:30 PM
How to quickly import old phone data to Huawei mobile phones?
Mar 23, 2024 pm 10:30 PM
How to quickly import old phone data to Huawei mobile phones? In today's information society, mobile phones have become an indispensable part of people's lives. With the development of technology and people's increasing demand for mobile phone functions, replacing mobile phones has become a common phenomenon. And when we upgrade to a new Huawei phone, how to quickly and effectively migrate the data from the old phone to the new phone becomes a problem that needs to be solved. For many users who use old mobile phones, they store a large number of contacts, text messages, photos, music, and videos.
 Detailed explanation of data migration and data synchronization of Gin framework
Jun 22, 2023 pm 09:12 PM
Detailed explanation of data migration and data synchronization of Gin framework
Jun 22, 2023 pm 09:12 PM
The Gin framework is a lightweight web framework with flexible routing and middleware mechanisms, suitable for rapid development of web applications. In actual development, data migration and data synchronization are common requirements. This article will introduce in detail how to use the Gin framework for data migration and data synchronization. 1. What is data migration and data synchronization? Data migration and data synchronization are common data manipulation methods in web development. The purpose is to move a set of data from one location to another and ensure the consistency and integrity of the data. . Data migration usually
