

What is data mining?

Data Mining is the process of extracting potentially useful information that is unknown in advance from a large amount of data. The goal of data mining is to build a decision-making model to predict future behavior based on past action data.
#Data mining refers to the process of searching for information hidden in large amounts of data through algorithms.
Data mining is usually related to computer science and achieves the above goals through many methods such as statistics, online analytical processing, intelligence retrieval, machine learning, expert systems (relying on past rules of thumb) and pattern recognition.
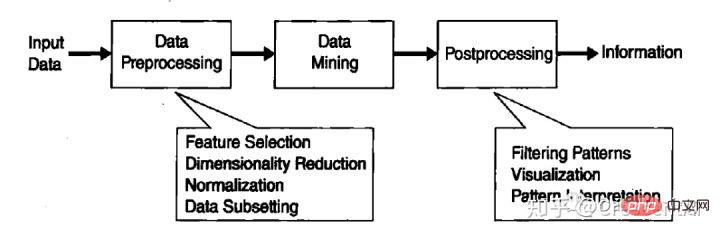
Data mining is an indispensable part of knowledge discovery in database (KDD), and KDD is the entire process of converting raw data into useful information. This process includes a series of conversion steps. From data pre-processing to post-processing of data mining results.
The Origin of Data Mining
Researchers from different disciplines came together and began to develop tools that could handle different data types. More efficient, scalable tools. These works are based on the methodologies and algorithms previously used by researchers, and culminate in the field of data mining.
In particular, data mining utilizes ideas from the following fields: (1) sampling, estimation, and hypothesis testing from statistics; (2) search algorithm modeling of artificial intelligence, pattern recognition, and machine learning Technology and learning theory.
Data mining has also rapidly embraced ideas from other fields, including optimization, evolutionary computation, information theory, signal processing, visualization, and information retrieval.
Some other areas also play an important supporting role. Database systems provide efficient storage, indexing, and query processing support. Technologies derived from high-performance (parallel) computing are often important in processing massive data sets. Distributed technologies can also help with processing massive amounts of data, and are even more critical when data cannot be processed centrally.

KDD(Knowledge Discovery from Database)
-
Data cleaning
Eliminate noise and inconsistent data;
-
Data integration
Multiple data sources can be combined together;
-
Data selection
Extract data related to analysis tasks from the database;
-
Data transformation
Transform and unify the data into data suitable for mining through summary or aggregation operations Form;
-
Data mining
Basic steps, using intelligent methods to extract data patterns;
-
Pattern evaluation
Identify truly interesting patterns representing knowledge based on a certain degree of interest;
-
Knowledge Representation
Use visualization and knowledge representation technology to provide users with mined knowledge .

Data mining methodology
-
Business understanding
Understand the goals and requirements of the project from a business perspective, and then transform this understanding into operational problems for data mining through theoretical analysis, and formulate a preliminary plan to achieve the goals;
-
Data understanding
The data understanding phase begins with the collection of raw data, then becomes familiar with the data, identifies data quality issues, explores a preliminary understanding of the data, and discovers interesting subsets to formulate Hypotheses for exploring information;
-
Data preparation
The data preparation stage refers to the activity of constructing the information required for data mining from the unprocessed data in the original raw data. . Data preparation tasks may be performed multiple times without any prescribed order. The main purpose of these tasks is to obtain the required information from the source system according to the requirements of dimensional analysis, which requires data preprocessing such as conversion, cleaning, construction, and integration of data;
-
Modeling
At this stage, it is mainly about selecting and applying various modeling techniques. At the same time, their parameters are tuned to achieve optimal values. Usually there are multiple modeling techniques for the same data mining problem type. Some technologies have special requirements for data forms, and often need to return to the data preparation stage;
-
Model evaluation (evaluation)
Before model deployment and release, it is necessary to start from At the technical level, judge the effect of the model and examine each step of building the model, as well as evaluate the practicability of the model in actual business scenarios based on business goals. The key purpose of this stage is to determine whether there are some important business issues that have not been fully considered;
-
Model deployment (deployment)
After the model is completed, the (Customer) Based on the current background and goal completion status, the package meets the business system usage needs.
Data mining tasks
Generally, data mining tasks are divided into the following two categories.
Prediction task. The goal of these tasks is to predict the value of a specific attribute based on the value of other attributes. The attributes being predicted are generally called target variables or dependent variables, and the attributes used for prediction are called explanatory variables or independent variables.
-
Describe the task. The goal is to derive patterns (correlations, trends, clusters, trajectories, and anomalies) that summarize underlying connections in the data. Descriptive data mining tasks are often exploratory in nature and often require post-processing techniques to verify and interpret the results.

Predictive modeling (predictive modeling) Involves building a model for the target variable by explaining the function of the variable.
There are two types of predictive modeling tasks: classification, used to predict discrete target variables; regression, used to predict continuous target variables.
For example, predicting whether a Web user will buy a book in an online bookstore is a classification task because the target variable is binary, while predicting the future price of a stock is a regression task because the price has continuous value attributes.
The goal of both tasks is to train a model to minimize the error between the predicted value and the actual value of the target variable. Predictive modeling can be used to determine customer responses to product promotions, predict disturbances in Earth's ecosystems, or determine whether a patient has a disease based on test results.
Association analysis (association analysis) is used to discover patterns that describe strong correlation features in the data.
The discovered patterns are usually expressed in the form of implication rules or subsets of features. Since the search space is exponential in size, the goal of correlation analysis is to extract the most interesting patterns in an efficient manner. Applications of association analysis include finding genomes with related functions, identifying Web pages that users visit together, and understanding the connections between different elements of the Earth's climate system.
Cluster analysis(cluster analysis) aims to find groups of observations that are closely related, so that observations belonging to the same cluster are more similar to each other than observations belonging to different clusters. as similar as possible. Clustering can be used to group related customers, identify areas of the ocean that significantly affect Earth's climate, compress data, and more.
Anomaly detection (anomaly detection) The task is to identify observations whose characteristics are significantly different from other data.
Such observations are called anomalies or outliers. The goal of anomaly detection algorithms is to discover real anomalies and avoid mistakenly labeling normal objects as anomalies. In other words, a good anomaly detector must have a high detection rate and a low false alarm rate.
Applications of anomaly detection include detecting fraud, cyberattacks, unusual patterns of disease, ecosystem disturbances, and more.
For more related knowledge, please visit: PHP Chinese website!
The above is the detailed content of What is data mining?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use Go language for data mining?
Jun 10, 2023 am 08:39 AM
How to use Go language for data mining?
Jun 10, 2023 am 08:39 AM
With the rise of big data and data mining, more and more programming languages have begun to support data mining functions. As a fast, safe and efficient programming language, Go language can also be used for data mining. So, how to use Go language for data mining? Here are some important steps and techniques. Data Acquisition First, you need to obtain the data. This can be achieved through various means, such as crawling information on web pages, using APIs to obtain data, reading data from databases, etc. Go language comes with rich HTTP
 Data Analysis with MySql: How to Handle Data Mining and Statistics
Jun 16, 2023 am 11:43 AM
Data Analysis with MySql: How to Handle Data Mining and Statistics
Jun 16, 2023 am 11:43 AM
MySql is a popular relational database management system that is widely used in enterprise and personal data storage and management. In addition to storing and querying data, MySql also provides functions such as data analysis, data mining, and statistics that can help users better understand and utilize data. Data is a valuable asset in any business or organization, and data analysis can help companies make correct business decisions. MySql can perform data analysis and data mining in many ways. Here are some practical techniques and tools: Use
 What is the difference between data mining and data analysis?
Dec 07, 2020 pm 03:16 PM
What is the difference between data mining and data analysis?
Dec 07, 2020 pm 03:16 PM
Differences: 1. The conclusions drawn by "data analysis" are the results of human intellectual activities, while the conclusions drawn by "data mining" are the knowledge rules discovered by the machine from the learning set [or training set, sample set]; 2. "Data "Analysis" cannot establish mathematical models and requires manual modeling, while "data mining" directly completes mathematical modeling.
 The application practice of Redis in artificial intelligence and data mining
Jun 20, 2023 pm 07:10 PM
The application practice of Redis in artificial intelligence and data mining
Jun 20, 2023 pm 07:10 PM
With the rise of artificial intelligence and big data technology, more and more companies and businesses are paying attention to how to efficiently store and process data. As a high-performance distributed memory database, Redis has attracted more and more attention in the fields of artificial intelligence and data mining. This article will give a brief introduction to the characteristics of Redis and its practice in artificial intelligence and data mining applications. Redis is an open source, high-performance, scalable NoSQL database. It supports a variety of data structures and provides caching, message queues, counters, etc.
 Time Series Forecasting Tips in Python
Jun 10, 2023 am 08:10 AM
Time Series Forecasting Tips in Python
Jun 10, 2023 am 08:10 AM
With the advent of the data era, more and more data are collected and used for analysis and prediction. Time series data is a common data type that contains a series of data based on time. The methods used to forecast this type of data are called time series forecasting techniques. Python is a very popular programming language with strong data science and machine learning support, so it is also a very suitable tool for time series forecasting. This article will introduce some commonly used time series forecasting techniques in Python and provide some practical applications
 Detailed explanation of Apriori algorithm in Python
Jun 10, 2023 am 08:03 AM
Detailed explanation of Apriori algorithm in Python
Jun 10, 2023 am 08:03 AM
The Apriori algorithm is a common method for association rule mining in the field of data mining, and is widely used in business intelligence, marketing and other fields. As a general programming language, Python also provides multiple third-party libraries to implement the Apriori algorithm. This article will introduce in detail the principle, implementation and application of the Apriori algorithm in Python. 1. Principle of Apriori algorithm Before introducing the principle of Apriori algorithm, let’s first learn the next two concepts in association rule mining: frequent itemsets and support.
 Volcano engine tool technology sharing: use AI to complete data mining and complete SQL writing with zero threshold
May 18, 2023 pm 08:19 PM
Volcano engine tool technology sharing: use AI to complete data mining and complete SQL writing with zero threshold
May 18, 2023 pm 08:19 PM
When using BI tools, questions often encountered are: "How can we produce and process data without SQL? Can we do mining analysis without algorithms?" When professional algorithm teams do data mining, data analysis and visualization will also be presented. relatively fragmented phenomenon. Completing algorithm modeling and data analysis work in a streamlined manner is also a good way to improve efficiency. At the same time, for professional data warehouse teams, data content on the same theme faces the problem of "repeated construction, relatively scattered use and management" - is there a way to produce data sets with the same theme and different content at the same time in one task? Can the produced data set be used as input to re-participate in data construction? 1. DataWind’s visual modeling capability comes with the BI platform Da launched by Volcano Engine
 How to perform automatic text classification and data mining in PHP?
May 22, 2023 pm 02:31 PM
How to perform automatic text classification and data mining in PHP?
May 22, 2023 pm 02:31 PM
PHP is an excellent server-side scripting language that is widely used in fields such as website development and data processing. With the rapid development of the Internet and the increasing amount of data, how to efficiently perform automatic text classification and data mining has become an important issue. This article will introduce methods and techniques for automatic text classification and data mining in PHP. 1. What is automatic text classification and data mining? Automatic text classification refers to the process of automatically classifying text according to its content, which is usually implemented using machine learning algorithms. Data mining refers to