

Python method to parse and read the contents of PDF files

This article mainly introduces the method of Python parsing and reading the content of PDF files. It also describes the relevant operating techniques of Python2.7 in win32 and win64 environments to read PDF in the form of examples. Friends in need can refer to the following
The examples in this article describe how Python parses and reads the contents of PDF files. Share it with everyone for your reference, the details are as follows:
1. Problem description
Use python to read the PDF text content.
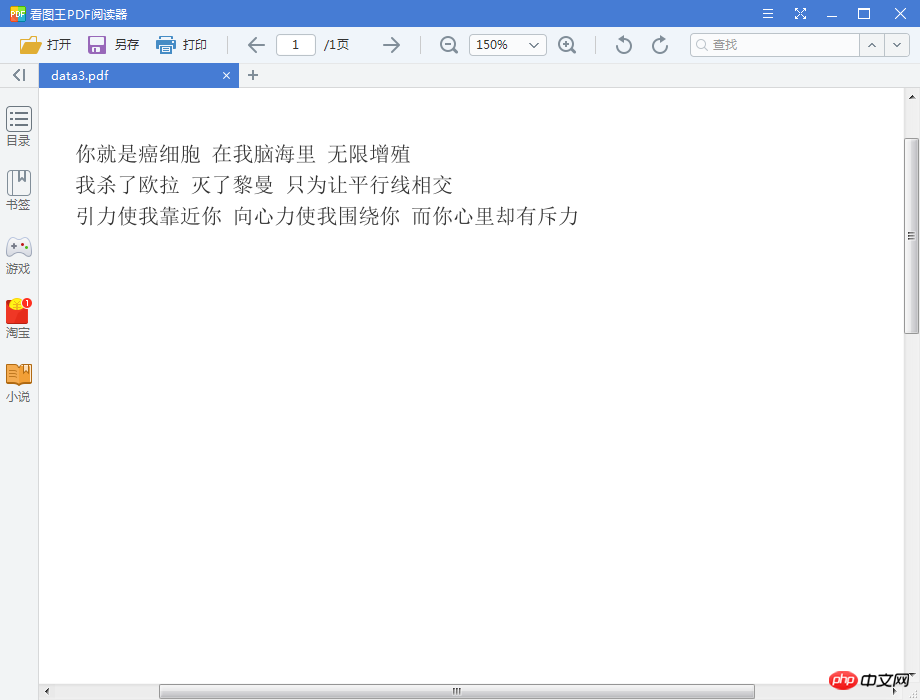
2. Effect
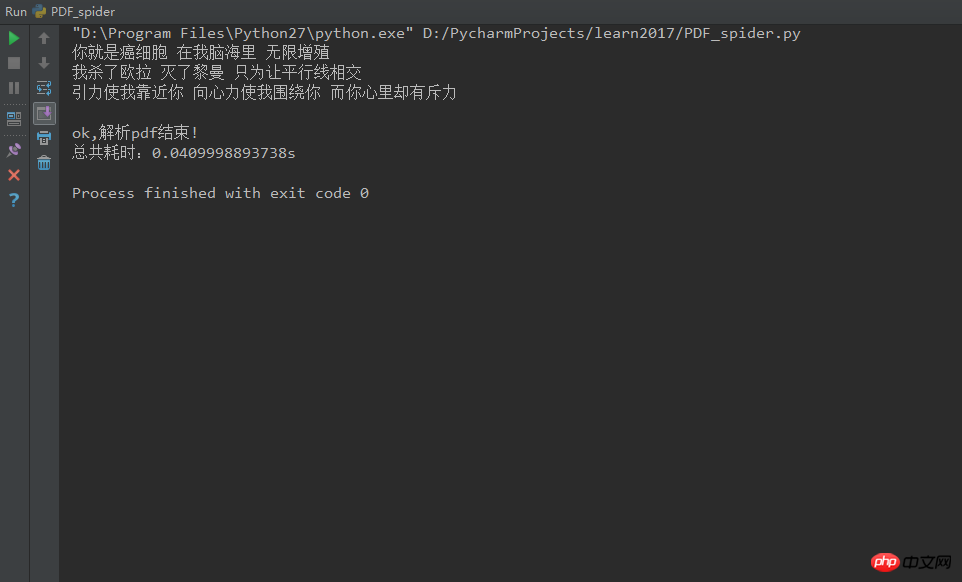
# #3. Running environment
python2.74. Libraries that need to be installed
pip install pdfminer
5. Implementation source code
Code 1 (win64)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/data3.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Code 2 (win32)
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import os.path
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
result=[]
class CPdf2TxtManager():
def __init__(self):
'''''
Constructor
'''
def changePdfToText(self, filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument(praser)
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if hasattr(x, "get_text"):
# print x.get_text()
result.append(x.get_text())
fileNames = os.path.splitext(filePath)
with open(fileNames[0] + '.txt','wb') as f:
results = x.get_text()
print(results)
f.write(results + '\n')
if __name__ == '__main__':
'''''
解析pdf 文本,保存到txt文件中
'''
path = u'C:/36.pdf'
pdf2TxtManager = CPdf2TxtManager()
pdf2TxtManager.changePdfToText(path)
# print result[0]
time2 = time.time()
print u'ok,解析pdf结束!'
print u'总共耗时:' + str(time2 - time1) + 's'Python implements the method of grabbing HTML web pages and saving them as PDF files
The above is the detailed content of Python method to parse and read the contents of PDF files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
