
 Technology peripherals
AI
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best
Technology peripherals
AI
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best
LLMs for Coding in 2024: Price, Performance, and the Battle for the Best

The rapidly evolving landscape of Large Language Models (LLMs) for coding presents developers with a wealth of choices. This analysis compares top LLMs accessible via public APIs, focusing on their coding prowess as measured by benchmarks like HumanEval and real-world Elo scores. Whether you're building personal projects or integrating AI into your workflow, understanding these models' strengths and weaknesses is crucial for informed decision-making.
The Challenges of LLM Comparison:
Direct comparison is difficult due to frequent model updates (even minor ones significantly impact performance), the inherent stochasticity of LLMs leading to inconsistent results, and potential biases in benchmark design and reporting. This analysis represents a best-effort comparison based on currently available data.
Evaluation Metrics: HumanEval and Elo Scores:
This analysis utilizes two key metrics:
- HumanEval: A benchmark assessing code correctness and functionality based on given requirements. It measures code completion and problem-solving abilities.
- Elo Scores (Chatbot Arena - coding only): Derived from head-to-head LLM comparisons judged by humans. Higher Elo scores indicate superior relative performance. A 100-point difference suggests a ~64% win rate for the higher-rated model.
Performance Overview:

OpenAI's models consistently top both HumanEval and Elo rankings, showcasing superior coding capabilities. The o1-mini model surprisingly outperforms the larger o1 model in both metrics. Other companies' best models show comparable performance, though trailing OpenAI.

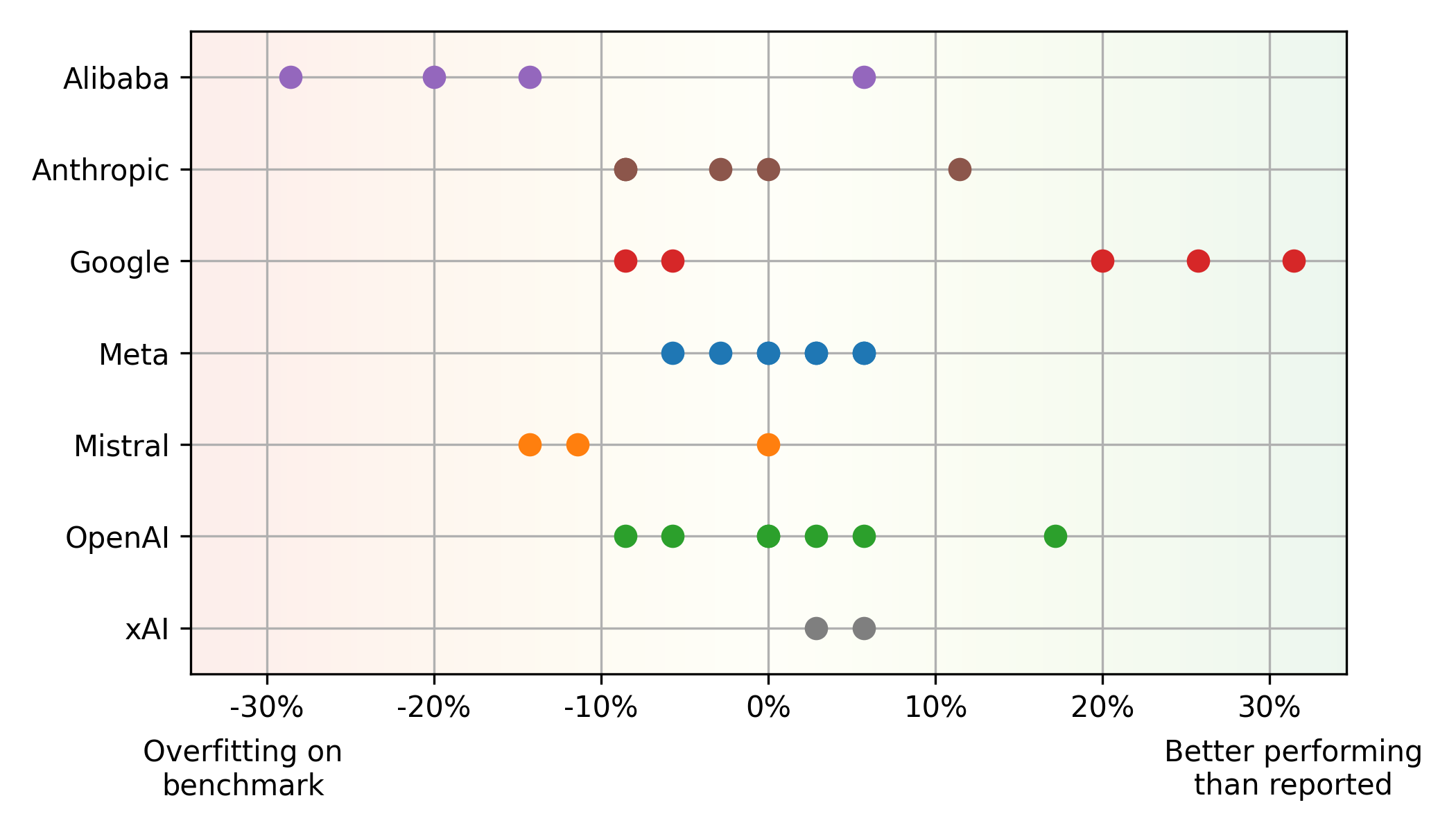
Benchmark vs. Real-World Performance Discrepancies:

A significant mismatch exists between HumanEval and Elo scores. Some models, like Mistral's Mistral Large, perform better on HumanEval than in real-world usage (potential overfitting), while others, such as Google's Gemini 1.5 Pro, show the opposite trend (underestimation in benchmarks). This highlights the limitations of relying solely on benchmarks. Alibaba and Mistral models often overfit benchmarks, while Google's models appear underrated due to their emphasis on fair evaluation. Meta models demonstrate a consistent balance between benchmark and real-world performance.
Balancing Performance and Price:


The Pareto front (optimal balance of performance and price) primarily features OpenAI (high performance) and Google (value for money) models. Meta's open-source Llama models, priced based on cloud provider averages, also show competitive value.
Additional Insights:



LLMs consistently improve in performance and decrease in cost. Proprietary models maintain dominance, although open-source models are catching up. Even minor updates significantly affect performance and/or pricing.
Conclusion:
The coding LLM landscape is dynamic. Developers should regularly assess the latest models, considering both performance and cost. Understanding the limitations of benchmarks and prioritizing diverse evaluation metrics is crucial for making informed choices. This analysis provides a snapshot of the current state, and continuous monitoring is essential to stay ahead in this rapidly evolving field.
The above is the detailed content of LLMs for Coding in 2024: Price, Performance, and the Battle for the Best. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
 Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
Choosing the Best AI Voice Generator: Top Options Reviewed
Apr 02, 2025 pm 06:12 PM
The article reviews top AI voice generators like Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, and Descript, focusing on their features, voice quality, and suitability for different needs.
 How to Access Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
How to Access Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
Falcon 3: A Revolutionary Open-Source Large Language Model Falcon 3, the latest iteration in the acclaimed Falcon series of LLMs, represents a significant advancement in AI technology. Developed by the Technology Innovation Institute (TII), this open
 Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
Top 7 Agentic RAG System to Build AI Agents
Mar 31, 2025 pm 04:25 PM
2024 witnessed a shift from simply using LLMs for content generation to understanding their inner workings. This exploration led to the discovery of AI Agents – autonomous systems handling tasks and decisions with minimal human intervention. Buildin
