

# | Automate PDF data extraction: User Acceptance Testing

Overview
Prior to each feature release, I do User Acceptance Testing ("UAT") to surface bugs and ensure the business logic is correctly translated to code.
I only clear a feature for release after UAT is 100% successful.
My reasoning is simple: you only get one chance to make a good first impression to your end user, and a poor release makes it doubly hard to do so.

Although this is an MVP feature that isn't meant for production release, I thought it'd be good to do some UAT to keep my skills fresh.
Results
Of the 19 UAT scenarios I came up with, one failed because of a change in the Custodian Statement PDF template.
I anticipated this risk during Discovery, but truth be told, I did not expect the issue to crop up so soon.
I will go into the bug fix details later in the article.
Methodology
My UAT process involves using the business logic or feature requirements as a reference to create test scenarios and expected outcomes.
Test scenarios don't need to be complicated. They can be as simple as : "The feature generates a CSV file within 30 seconds".
For the UAT, I processed 71 pages of documents from 10 Custodian Statement PDFs. This should be a sufficiently large enough sample set.
The expected output is three CSV files containing specific datapoints from the Fund Holdings, Securities Holdings and Cash Holdings sections of the Custodian Statement PDF.
I came up with the following test cases:
CSV 1: Fund Holdings
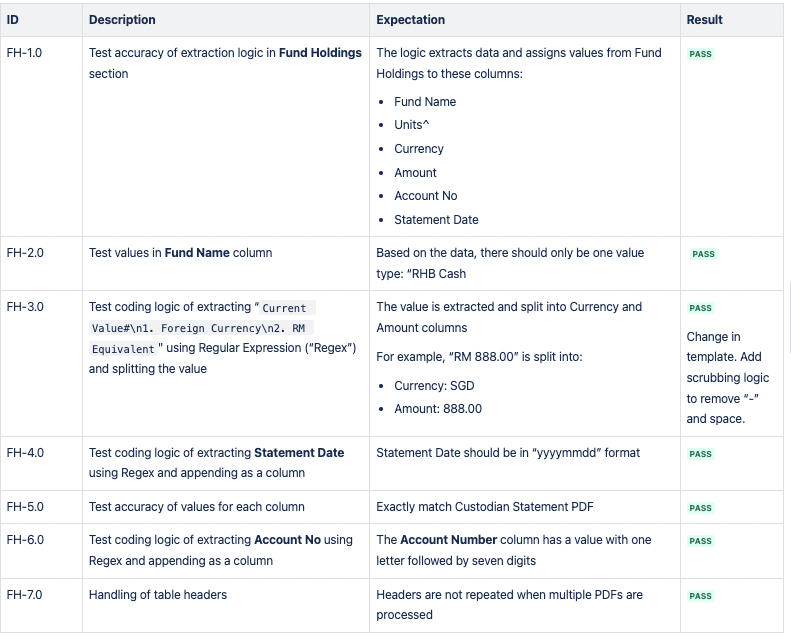
CSV 2: Securities Holdings
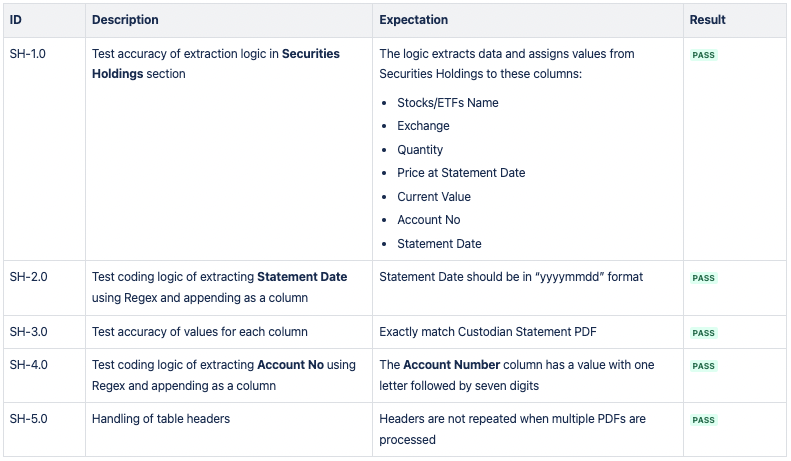
CSV 3: Cash Holdings

Bug Fixing
The one failed test was because the Custodian Statement PDF's template changed slightly in November. More specifically, the values in the "Current Value# 1. Foreign Currency 2. RM Equivalent" column of a Fund Holdings table now has an extra "-n" prefix.
For example, instead of reading "USD 10,000" in previous PDFs, the value now reads "- USD10,000".
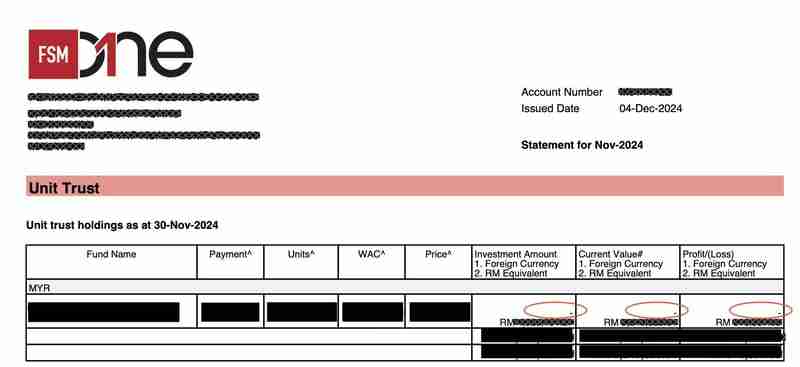
This small change resulted in the following issue:

I consulted ChatGPT on a fix, and it recommended the following scrubbing logic be added to remove the incorrect "-/n" prefix.
# Scrub error prefix
df['Currency'] = df['Currency'].str.replace('[-\n]', '', regex=True)
The scrubbing did the trick and the Fund Holdings CSV output now comes out as expected.
What Next?
I'm now comfortable that the code to extract PDF data is functional. That said, I don't think a CSV file is the best place to store all this data.
While CSV is user friendly (to me), storing data in a database makes it much easier to retrieve and manipulate data as per the end user's requirements.
I have very limited experience in databases. So what I'll do next is Discovery on a database application that I can onboard quickly.
--Ends
The above is the detailed content of # | Automate PDF data extraction: User Acceptance Testing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Python vs. C : Learning Curves and Ease of Use
Apr 19, 2025 am 12:20 AM
Python vs. C : Learning Curves and Ease of Use
Apr 19, 2025 am 12:20 AM
Python is easier to learn and use, while C is more powerful but complex. 1. Python syntax is concise and suitable for beginners. Dynamic typing and automatic memory management make it easy to use, but may cause runtime errors. 2.C provides low-level control and advanced features, suitable for high-performance applications, but has a high learning threshold and requires manual memory and type safety management.
 Learning Python: Is 2 Hours of Daily Study Sufficient?
Apr 18, 2025 am 12:22 AM
Learning Python: Is 2 Hours of Daily Study Sufficient?
Apr 18, 2025 am 12:22 AM
Is it enough to learn Python for two hours a day? It depends on your goals and learning methods. 1) Develop a clear learning plan, 2) Select appropriate learning resources and methods, 3) Practice and review and consolidate hands-on practice and review and consolidate, and you can gradually master the basic knowledge and advanced functions of Python during this period.
 Python vs. C : Exploring Performance and Efficiency
Apr 18, 2025 am 12:20 AM
Python vs. C : Exploring Performance and Efficiency
Apr 18, 2025 am 12:20 AM
Python is better than C in development efficiency, but C is higher in execution performance. 1. Python's concise syntax and rich libraries improve development efficiency. 2.C's compilation-type characteristics and hardware control improve execution performance. When making a choice, you need to weigh the development speed and execution efficiency based on project needs.
 Python vs. C : Understanding the Key Differences
Apr 21, 2025 am 12:18 AM
Python vs. C : Understanding the Key Differences
Apr 21, 2025 am 12:18 AM
Python and C each have their own advantages, and the choice should be based on project requirements. 1) Python is suitable for rapid development and data processing due to its concise syntax and dynamic typing. 2)C is suitable for high performance and system programming due to its static typing and manual memory management.
 Which is part of the Python standard library: lists or arrays?
Apr 27, 2025 am 12:03 AM
Which is part of the Python standard library: lists or arrays?
Apr 27, 2025 am 12:03 AM
Pythonlistsarepartofthestandardlibrary,whilearraysarenot.Listsarebuilt-in,versatile,andusedforstoringcollections,whereasarraysareprovidedbythearraymoduleandlesscommonlyusedduetolimitedfunctionality.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 Python for Scientific Computing: A Detailed Look
Apr 19, 2025 am 12:15 AM
Python for Scientific Computing: A Detailed Look
Apr 19, 2025 am 12:15 AM
Python's applications in scientific computing include data analysis, machine learning, numerical simulation and visualization. 1.Numpy provides efficient multi-dimensional arrays and mathematical functions. 2. SciPy extends Numpy functionality and provides optimization and linear algebra tools. 3. Pandas is used for data processing and analysis. 4.Matplotlib is used to generate various graphs and visual results.
 Python for Web Development: Key Applications
Apr 18, 2025 am 12:20 AM
Python for Web Development: Key Applications
Apr 18, 2025 am 12:20 AM
Key applications of Python in web development include the use of Django and Flask frameworks, API development, data analysis and visualization, machine learning and AI, and performance optimization. 1. Django and Flask framework: Django is suitable for rapid development of complex applications, and Flask is suitable for small or highly customized projects. 2. API development: Use Flask or DjangoRESTFramework to build RESTfulAPI. 3. Data analysis and visualization: Use Python to process data and display it through the web interface. 4. Machine Learning and AI: Python is used to build intelligent web applications. 5. Performance optimization: optimized through asynchronous programming, caching and code
