
 Technology peripherals
AI
Adapting to multiple forms and tasks, the most powerful open source robot learning system 'Octopus' was born
Technology peripherals
AI
Adapting to multiple forms and tasks, the most powerful open source robot learning system 'Octopus' was born
Adapting to multiple forms and tasks, the most powerful open source robot learning system 'Octopus' was born

In terms of robot learning, a common approach is to collect data sets specific to a specific robot and task, and then use them to train a policy. However, if this method is used to learn from scratch, sufficient data needs to be collected for each task, and the generalization ability of the resulting policy is usually poor.
"In principle, experience gathered from other robots and tasks can provide possible solutions, allowing the model to see a variety of robot control problems that may be able to Improving the generalization ability and performance of robots on downstream tasks. However, even if general models that can handle a variety of natural language and computer vision tasks have emerged, it is still difficult to build a "universal robot model."
It is very difficult to train a unified control strategy for a robot, which involves many difficulties, including operating different robot bodies, sensor configurations, action spaces, task specifications, environments and computing budgets.
In order to achieve this goal, some research results related to "robot basic model" have appeared; their approach is to directly map robot observations into actions, and then generalize through zero-sample sample solutions to new areas or new robots. These models are often referred to as "generalist robot policies," or GRPs, which emphasize the robot's ability to perform low-level visuomotor control across a variety of tasks, environments, and robotic systems.
GNM (General Navigation Model) is suitable for a variety of different robot navigation scenarios. RoboCat can operate different robot bodies according to mission goals, and RT-X can be operated through language Five different robot bodies. Although these models are indeed an important advance, they also suffer from multiple limitations: their input observations are often predefined and often limited (such as a single camera input video stream); they are difficult to effectively fine-tune to new domains; in these models The largest versions are not available for people to use (this is important).
Recently, the Octo Model Team composed of 18 researchers from the University of California, Berkeley, Stanford University, Carnegie Mellon University and Google DeepMind released their groundbreaking research results: Octo model. This project effectively overcomes the above limitations.

- Paper title: Octo: An Open-Source Generalist Robot Policy
- Paper address: https://arxiv.org/pdf/2405.12213
- Open source project: https://octo-models. github.io/
They designed a system that allows GRP to more easily cope with the interface diversity problem of downstream robot applications.
The core of this model is the Transformer architecture, which can map any input token (created based on observations and tasks) into an output token (then encoded into an action), and this architecture can be used in a variety of ways ized robot and task data sets for training. The policy can accept different camera configurations without additional training, can control different robots, and can be guided by verbal commands or target images—all by simply changing the tokens input to the model.
Most importantly, the model can also adapt to new robot configurations with different sensor inputs, operating spaces, or robot morphologies. All that is required is to adopt the appropriate adapter and use a Fine-tuning with small target domain datasets and small computational budgets.
Not only that, Octo has also completed pre-training on the largest robot manipulation data set to date - this data set contains 800,000 robots from the Open X-Embodiment data set Demo. Octo is not only the first GRP to be efficiently fine-tuned to new observation and action spaces, it is also the first generalist robot manipulation strategy that is fully open source (training workflow, model checkpoints, and data). The team also highlighted in the paper the unique and innovative nature of its combined Octo components.
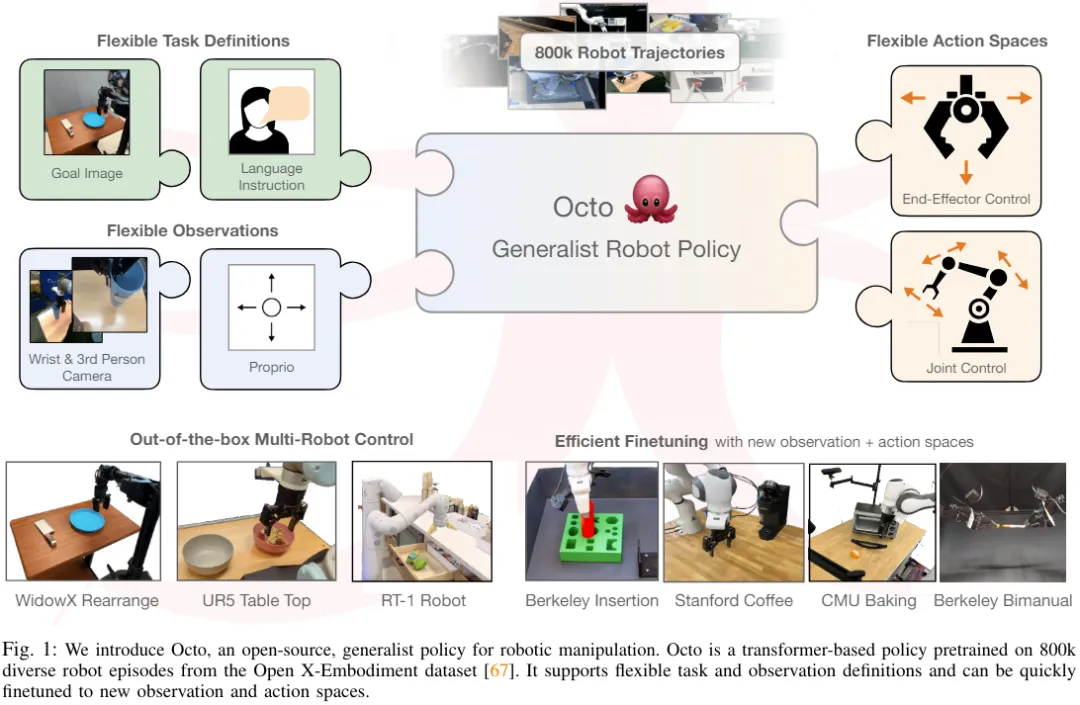
Octo model
Let’s take a look at how Octo, the open source generalist robot strategy, is built of. Overall, Octo is designed to be a flexible and broadly applicable generalist robotics strategy that can be used by a number of different downstream robotics applications and research projects.
Architecture
The core of Octo is based on the Transformer strategy π. It contains three key parts: the input tokenizer, the Transformer backbone network, and the readout head.
As shown in Figure 2, the function of the input tokenizer is to convert language instructions, targets and observation sequences into tokens. The Transformer backbone will process these tokens into embeddings and read out the headers. Then the desired output is obtained, which is the action.
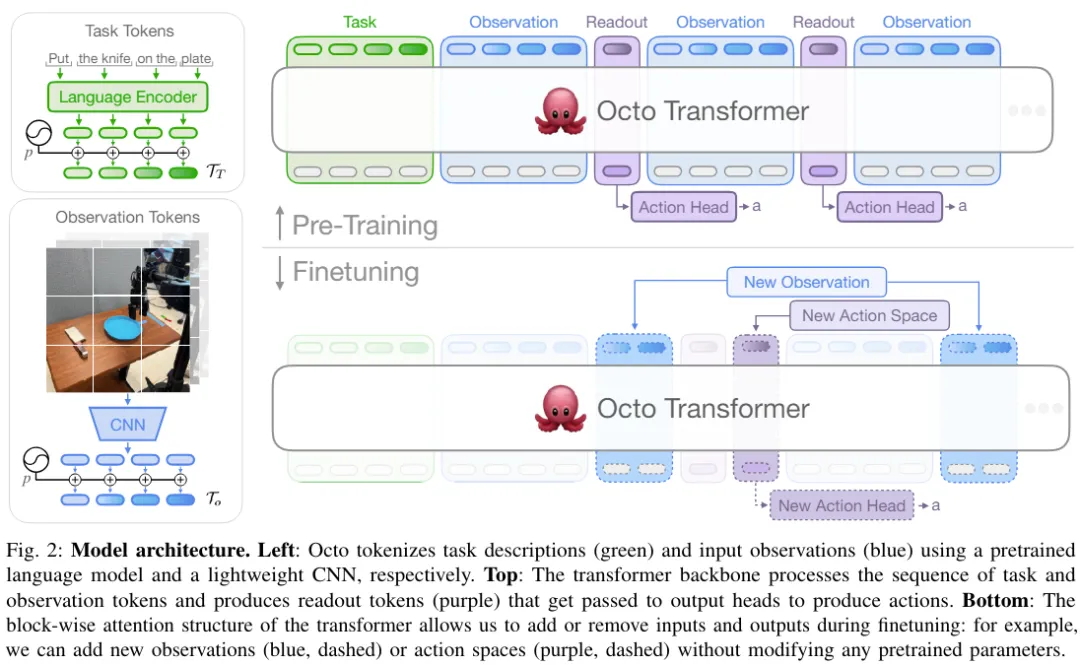
Task and observation tokenizer
In order to define the task (such as language instructions and target images ) and observations (such as camera video streams) into commonly used tokenized formats. The team uses different tokenizers for different modalities:
For language input, first tokenization, and then process it into a language embedding token sequence through a pre-trained Transformer. Specifically, the model they used is t5-base (111M).
For image observations and targets, they are processed through a shallower convolution stack and then split into a sequence of flattened tiles.
Finally, the Transformer’s input sequence is constructed by adding learnable positional embeddings to task and observation tokens and arranging them in a certain order.
Transformer backbone and readout head
After processing the input into a unified token sequence, it can be handed over to Transformer for processing. This is similar to previous research work on training Transformer-based policies based on observations and action sequences.
Octo's attention mode is block-by-block masking: observation tokens can only pay attention to tokens and task tokens from the same or previous time steps according to the causal relationship. Tokens corresponding to non-existent observations are completely masked (such as data sets without language instructions). This modular design makes it easy to add or remove observations or tasks during the fine-tuning phase.
In addition to these input token modules, the team also inserted learned readout tokens. The readout token will pay attention to its previous observation and task tokens, but will not be paid attention to by any observation or task token. Therefore, readout tokens can only read and process the internal embedding, but cannot affect the internal embedding. The readout token acts similarly to the [CLS] token in BERT, acting as a compact vector embedding of the sequence of observations so far. For the embedding of read tokens, a lightweight "action header" that implements the diffusion process will be used. This action header predicts a "chunk" of multiple consecutive actions.
This design allows users to flexibly add new tasks and observation input or action output headers to the model during downstream fine-tuning. When adding new tasks, observations, or loss functions downstream, you can retain the Transformer's pretrained weights as a whole and only add new positional embeddings, a new lightweight encoder, or new headers necessary due to specification changes. parameter. This differs from previous architectures, which required reinitialization or retraining of numerous components of the pretrained model if image inputs were added or removed or task specifications changed.
To make Octo a true "generalist" model, this flexibility is crucial: since it is impossible to cover all possible robot sensor and action configurations in the pre-training stage, , if the inputs and outputs of Octo can be adjusted during the fine-tuning phase, it will make it a versatile tool for the robotics community. Additionally, previous model designs that used a standard Transformer backbone or fused a visual encoder with an MLP output head fixed the type and order of model inputs. In contrast, switching Octo's observations or tasks does not require reinitialization of much of the model.
Training data
The team took a mix of 25 datasets from Open X-Embodiment data set. Figure 3 gives the composition of the data set.
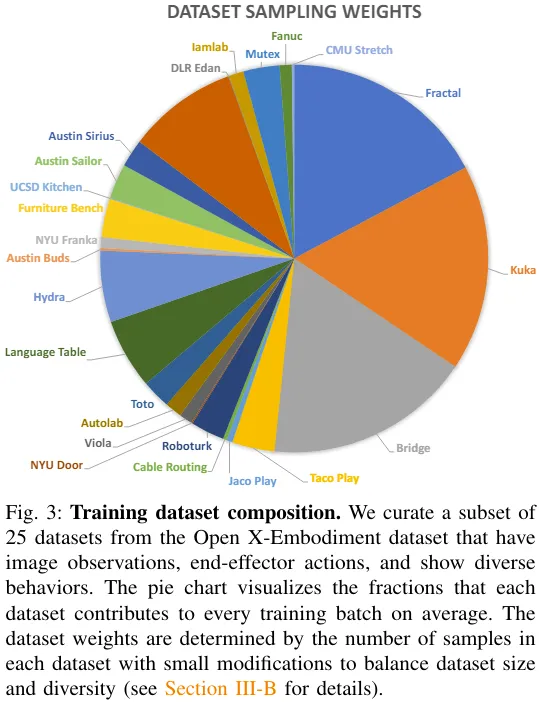
Please refer to the original paper for more details on training objectives and training hardware configuration.
Model checkpoints and code
Here comes the point! The team not only published Octo's paper, but also fully open sourced all resources, including:
- The pre-trained Octo checkpoints include Octo-Small with 27 million parameters and Octo-Base with 93 million parameters.
- Fine-tuning script for Octo models, based on JAX.
- Model pre-training workflow for pre-training Octo on the Open X-Embodiment dataset, based on JAX. Data loader for Open X-Embodiment data, compatible with JAX and PyTorch.
Experiment
The team also conducted an empirical analysis of Octo through experiments, evaluating it as a robot in multiple dimensions Performance of the basic model:
- Can I use Octo directly to control multiple robot bodies and solve language and target tasks?
- Can Octo weights serve as a good initialization basis to support data-efficient fine-tuning for new tasks and robots, and are they superior to training-from-scratch methods and commonly used pre-trained representations?
- Which design decision in Octo is most important in building a generalist robot strategy?
Figure 4 shows the 9 tasks for evaluating Octo.

Use Octo directly to control multiple robots
The team compared The zero-sample control capabilities of Octo, RT-1-X, and RT-2-X are shown in Figure 5.
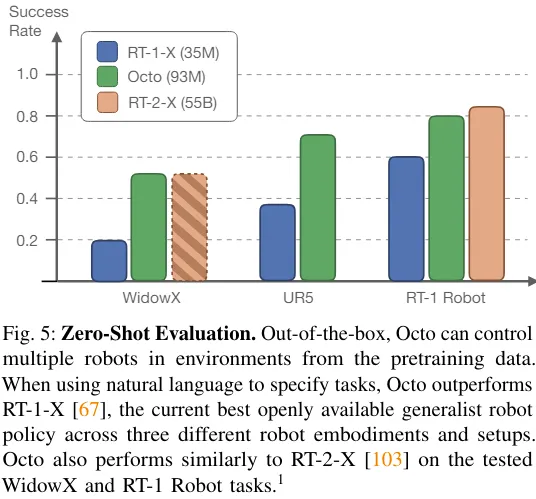
It can be seen that the success rate of Octo is 29% higher than RT-1-X (35 million parameters). In the WidowX and RT-1 Robot evaluation, the performance of Octo is equivalent to that of RT-2-X with 55 billion parameters.
In addition, RT-1-X and RT-2-X only support language commands, while Octo also supports conditional on the target image. The team also found that on the WidowX task, success rates were 25% higher when conditioned on target images than when conditioned on language. This may be because target images provide more information about task completion.
Octo can efficiently use data to adapt to new fields
Table 1 gives the data-efficient fine-tuning Experimental results.

It can be seen that compared to training from scratch or pre-training using pre-trained VC-1 weights, fine-tuning Octo gives better results. good. Across 6 evaluation settings, Octo's average advantage over the second-place baseline is 52%!
And it must be mentioned that for all these evaluation tasks, the recipes and hyperparameters used when fine-tuning Octo were all the same, which shows that the team found a very good default configuration .
Design decisions for generalist robot strategy training
The above results show that Octo can indeed be used as a zero-shot multi-robot control It can also be used as the initialization basis for policy fine-tuning. Next, the team analyzed the impact of different design decisions on the performance of the Octo strategy. Specifically, they focus on the following aspects: model architecture, training data, training objectives, and model size. To do this, they conducted ablation studies.
Table 2 presents the results of the ablation study on model architecture, training data, and training targets.
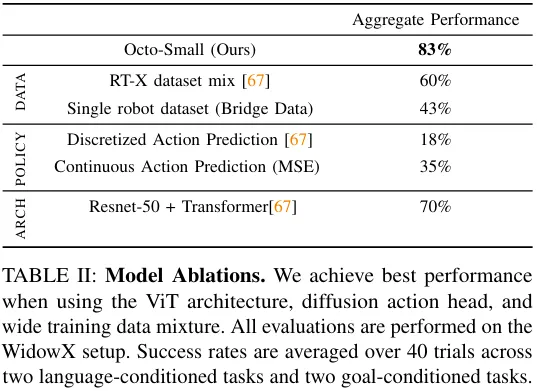
Figure 6 shows the impact of model size on the zero-sample success rate. It can be seen that larger models have better visual scene perception. ability.
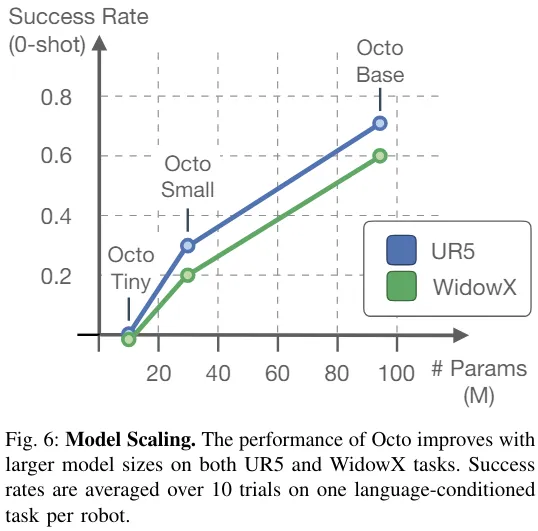
Overall, the effectiveness of Octo’s components is proven.
The above is the detailed content of Adapting to multiple forms and tasks, the most powerful open source robot learning system 'Octopus' was born. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1653
1653
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
