

Basic and commonly used algorithms in Python
This article mainly focuses on learning common algorithms in Python and common sorting algorithms in Python, which has a certain reference value. Interested friends can refer to it
The content of this section
Algorithm definition
Time complexity
Space complexity
Commonly used algorithm examples
##1.Algorithm definition
Algorithm refers to an accurate and complete description of a problem-solving solution. It is a series of clear instructions for solving problems. Algorithm represents a systematic method to describe the strategic mechanism for solving problems. In other words, it is possible to obtain the required output within a limited time for a certain specification of input. If an algorithm is flawed or inappropriate for a problem, executing the algorithm will not solve the problem. Different algorithms may use different time, space, or efficiency to complete the same task. The quality of an algorithm can be measured by its space complexity and time complexity. An algorithm should have the following seven important characteristics: ①Finiteness: The finiteness of an algorithm means that the algorithm must be able to terminate after executing a limited number of steps;②Definiteness: Each step of the algorithm must have an exact definition; ③Input: An algorithm has 0 or more inputs to describe the operand The so-called 0 inputs refer to the initial conditions set by the algorithm itself; ④Output: An algorithm has one or more outputs to reflect the results of processing the input data . An algorithm without output is meaningless;⑤Effectiveness: Any calculation steps performed in the algorithm can be decomposed into basic executable operation steps, that is, each calculation step All can be completed within a limited time (also called effectiveness); ⑥High efficiency: fast execution and less resource usage;⑦Robustness : Correct response to data.2. Time complexity
In computer science, the time complexity of an algorithm is a function that quantitatively describes the operation of the algorithm. Time, time complexity commonly used Big O notation (Big O notation) is a mathematical notation used to describe the asymptotic behavior of a function. More precisely, it is a function that is described in terms of another (usually simpler) function The asymptotic upper bound of the order of magnitude. In mathematics, it is generally used to describe the remaining terms of truncated infinite series, especially asymptotic series; in computer science, it is very useful in analyzing the complexity of algorithms. , using this method, the time complexity can be said to be asymptotic, which considers the situation when the size of the input value approaches infinity.Big O, in short, it can be considered to mean "order of" (approximately).
Infinite asymptotic
When n increases, the n^2; term will start to dominate, and the other terms can be ignored - for example: when n = 500, the 4n^2; term is 1000 times larger than the 2n term, Therefore, in most cases, the effect of omitting the latter on the value of the expression will be negligible.
1. Calculation method
The number of statement executions in an algorithm is called statement frequency or time frequency. Denote it as T(n).
When calculating the time complexity, first find out the basic operations of the algorithm, then determine the number of executions based on the corresponding statements, and then find the same order of magnitude of T(n) (its same order of magnitude are as follows: 1 , Log2n, n, nLog2n, n square, n cube, 2 n power, n!), after finding out, f (n) = this order of magnitude, if T (n)/f (n) find the limit A constant c can be obtained, and the time complexity T(n)=O(f(n)).
Constant order O(1), Logarithmic order O(log2n), linear order O(n), linear logarithmic order O(nlog2n), square order O(n^2), cubic order O(n^3),..., kth power order O(n ^k), exponential order O(2^n).
in,
1.O(n), O(n^2), cubic order O(n^3),..., kth order O(n^k) are polynomial order time complexity, respectively called First-order time complexity, second-order time complexity. . . .
2.O(2^n), exponential time complexity, this kind of impractical
3. Logarithmic order O(log2n), linear logarithmic order O(nlog2n), except for constant order, this The most efficient one
Example: Algorithm:
for(i=1;i<=n;++i)
{
for(j=1;j<=n;++j)
{
c[ i ][ j ]=0; //该步骤属于基本操作 执行次数:n^2
for(k=1;k<=n;++k)
c[ i ][ j ]+=a[ i ][ k ]*b[ k ][ j ]; //该步骤属于基本操作 执行次数:n^3
}
} Then there is T(n)=n^2+n^3, According to the same order of magnitude in the brackets above, we can determine that n^3 is the same order of magnitude as T(n)
Then f(n) = n^3, and then find the limit according to T(n)/f(n) Obtain the constant c
, then the time complexity of the algorithm: T(n)=O(n^3)
4. Definition: If the scale of a problem is n , the time required for a certain algorithm to solve this problem is T(n), which is a certain function of n. T(n) is called the "time complexity" of this algorithm.
When the input quantity n gradually increases, the limit situation of time complexity is called the "asymptotic time complexity" of the algorithm.
We often use big O notation to express time complexity. Note that it is the time complexity of a certain algorithm. Big O means that there is an upper bound. By definition, if f(n)=O(n), then f(n)=O(n^2) obviously holds. It gives you an upper bound, but it is not a supremum. , but people are generally used to express the former when expressing.
In addition, a problem itself also has its complexity. If the complexity of an algorithm reaches the lower bound of the complexity of the problem, then such an algorithm is called the best algorithm.
"Big O notation": The basic parameter used in this description is n, the size of the problem instance, expressing the complexity or running time as a function of n. The "O" here represents the order. For example, "Binary search is O(logn)", which means that it needs to "retrieve an array of size n through logn steps." The notation O ( f(n) ) means that when n increases, the running time will at most increase at a rate proportional to f(n).
This asymptotic estimation is very valuable for theoretical analysis and rough comparison of algorithms, but in practice details may also cause differences. For example, an O(n2) algorithm with low overhead may run faster for small n than an O(nlogn) algorithm with high overhead. Of course, as n becomes large enough, algorithms with slower rising functions must work faster.
O(1)
##Temp=i;i=j;j=temp;
The above three single statements The frequency of is all 1, and the execution time of this program segment is a constant independent of the problem size n. The time complexity of the algorithm is constant order, recorded as T(n)=O(1). If the execution time of the algorithm does not increase with the increase of the problem size n, even if there are thousands of statements in the algorithm, its execution time will only be a large constant. The time complexity of this type of algorithm is O(1).O(n^2)
2.1. Exchange the contents of i and j
for(i=1;i<=n;i++) (n times)
for(j=1;j<=n;j++) (n^2 times)
sum++; (n^2 times)
Solution: T(n)=2n^2+n+1 =O(n^2)
y=y+1; ①
for (j=0;j<=(2*n);j++)
x++; -1
f (n) = 2n^2-n-1+(n-) = 2N^2-2
Time complexity of the program T (n) = O (n^2).
O(n)
2.3.
a=0;
b=1; ①
for (i=1;i<=n;i++) ②
{
s=a+b; ③
b=a; ④
a=s; ⑤
}
解:语句1的频度:2,
语句2的频度: n,
语句3的频度: n-1,
语句4的频度:n-1,
语句5的频度:n-1,
T(n)=2+n+3(n-1)=4n-1=O(n).
O(log2n )
2.4.
i=1; ①
while (i<=n)
i=i*2; ②
解: 语句1的频度是1,
设语句2的频度是f(n), 则:2^f(n)<=n;f(n)<=log2n
取最大值f(n)= log2n,
T(n)=O(log2n )
O(n^3)
2.5.
for(i=0;i
for(j=0;j
for(k=0;k
}
}
解:当i=m, j=k的时候,内层循环的次数为k当i=m时, j 可以取 0,1,...,m-1 , 所以这里最内循环共进行了0+1+...+m-1=(m-1)m/2次所以,i从0取到n, 则循环共进行了: 0+(1-1)*1/2+...+(n-1)n/2=n(n+1)(n-1)/6所以时间复杂度为O(n^3).
我们还应该区分算法的最坏情况的行为和期望行为。如快速排序的最 坏情况运行时间是 O(n^2),但期望时间是 O(nlogn)。通过每次都仔细 地选择基准值,我们有可能把平方情况 (即O(n^2)情况)的概率减小到几乎等于 0。在实际中,精心实现的快速排序一般都能以 (O(nlogn)时间运行。
下面是一些常用的记法:
访问数组中的元素是常数时间操作,或说O(1)操作。一个算法如 果能在每个步骤去掉一半数据元素,如二分检索,通常它就取 O(logn)时间。用strcmp比较两个具有n个字符的串需要O(n)时间。常规的矩阵乘算法是O(n^3),因为算出每个元素都需要将n对 元素相乘并加到一起,所有元素的个数是n^2。
指数时间算法通常来源于需要求出所有可能结果。例如,n个元 素的集合共有2n个子集,所以要求出所有子集的算法将是O(2n)的。指数算法一般说来是太复杂了,除非n的值非常小,因为,在 这个问题中增加一个元素就导致运行时间加倍。不幸的是,确实有许多问题 (如著名的“巡回售货员问题” ),到目前为止找到的算法都是指数的。如果我们真的遇到这种情况,通常应该用寻找近似最佳结果的算法替代之。
常用排序
冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
data_set = [ 9,1,22,31,45,3,6,2,11 ]
loop_count = 0
for j in range(len(data_set)):
for i in range(len(data_set) - j- 1): # -1 是因为每次比对的都 是i 与i +1,不减1的话,最后一次对比会超出list 获取范围,-j是因为,每一次大loop就代表排序好了一个最大值,放在了列表最后面,下次loop就不用再运算已经排序好了的值 了
if data_set[i] > data_set[i+1]: #switch
tmp = data_set[i]
data_set[i] = data_set[i+1]
data_set[i+1] = tmp
loop_count +=1
print(data_set)
print(data_set)
print("loop times", loop_count)选择排序
The algorithm works by selecting the smallest unsorted item and then swapping it with the item in the next position to be filled.
The selection sort works as follows: you look through the entire array for the smallest element, once you find it you swap it (the smallest element) with the first element of the array. Then you look for the smallest element in the remaining array (an array without the first element) and swap it with the second element. Then you look for the smallest element in the remaining array (an array without first and second elements) and swap it with the third element, and so on. Here is an example,
data_set = [ 9,1,22,31,45,3,6,2,11 ]
smallest_num_index = 0 #初始列表最小值,默认为第一个
loop_count = 0
for j in range(len(data_set)):
for i in range(j,len(data_set)):
if data_set[i] < data_set[smallest_num_index]: #当前值 比之前选出来的最小值 还要小,那就把它换成最小值
smallest_num_index = i
loop_count +=1
else:
print("smallest num is ",data_set[smallest_num_index])
tmp = data_set[smallest_num_index]
data_set[smallest_num_index] = data_set[j]
data_set[j] = tmp
print(data_set)
print("loop times", loop_count)The worst-case runtime complexity is O(n2).
插入排序(Insertion Sort)
插入排序(Insertion Sort)的基本思想是:将列表分为2部分,左边为排序好的部分,右边为未排序的部分,循环整个列表,每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。

插入排序非常类似于整扑克牌。
在开始摸牌时,左手是空的,牌面朝下放在桌上。接着,一次从桌上摸起一张牌,并将它插入到左手一把牌中的正确位置上。为了找到这张牌的正确位置,要将它与手中已有的牌从右到左地进行比较。无论什么时候,左手中的牌都是排好序的。
也许你没有意识到,但其实你的思考过程是这样的:现在抓到一张7,把它和手里的牌从右到左依次比较,7比10小,应该再往左插,7比5大,好,就插这里。为什么比较了10和5就可以确定7的位置?为什么不用再比较左边的4和2呢?因为这里有一个重要的前提:手里的牌已经是排好序的。现在我插了7之后,手里的牌仍然是排好序的,下次再抓到的牌还可以用这个方法插入。编程对一个数组进行插入排序也是同样道理,但和插入扑克牌有一点不同,不可能在两个相邻的存储单元之间再插入一个单元,因此要将插入点之后的数据依次往后移动一个单元。
source = [92, 77, 67, 8, 6, 84, 55, 85, 43, 67] for index in range(1,len(source)): current_val = source[index] #先记下来每次大循环走到的第几个元素的值 position = index while position > 0 and source[position-1] > current_val: #当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来 source[position] = source[position-1] #把左边的一个元素往右移一位 position -= 1 #只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止 source[position] = current_val #已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里 print(source)
结果:
[77, 92, 67, 8, 6, 84, 55, 85, 43, 67]
[67, 77, 92, 8, 6, 84, 55, 85, 43, 67]
[8, 67, 77, 92, 6, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 92, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 84, 92, 55, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 92, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 85, 92, 43, 67]
[6, 8, 43, 55, 67, 77, 84, 85, 92, 67]
[6, 8, 43, 55, 67, 67, 77, 84, 85, 92]
#更容易理解的版本
data_set = [ 9,1,22,9,31,-5,45,3,6,2,11 ] for i in range(len(data_set)): #position = i while i > 0 and data_set[i] < data_set[i-1]:# 右边小于左边相邻的值 tmp = data_set[i] data_set[i] = data_set[i-1] data_set[i-1] = tmp i -= 1 # position = i # while position > 0 and data_set[position] < data_set[position-1]:# 右边小于左边相邻的值 # tmp = data_set[position] # data_set[position] = data_set[position-1] # data_set[position-1] = tmp # position -= 1
快速排序(quick sort)
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动
注:在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生改变,则称这种排序方法是不稳定的。
要注意的是,排序算法的稳定性是针对所有输入实例而言的。即在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该排序算法就是不稳定的。
排序演示
示例
假设用户输入了如下数组:

创建变量i=0(指向第一个数据), j=5(指向最后一个数据), k=6(赋值为第一个数据的值)。
我们要把所有比k小的数移动到k的左面,所以我们可以开始寻找比6小的数,从j开始,从右往左找,不断递减变量j的值,我们找到第一个下标3的数据比6小,于是把数据3移到下标0的位置,把下标0的数据6移到下标3,完成第一次比较:

i=0 j=3 k=6
接着,开始第二次比较,这次要变成找比k大的了,而且要从前往后找了。递加变量i,发现下标2的数据是第一个比k大的,于是用下标2的数据7和j指向的下标3的数据的6做交换,数据状态变成下表:

i=2 j=3 k=6
称上面两次比较为一个循环。
接着,再递减变量j,不断重复进行上面的循环比较。
在本例中,我们进行一次循环,就发现i和j“碰头”了:他们都指向了下标2。于是,第一遍比较结束。得到结果如下,凡是k(=6)左边的数都比它小,凡是k右边的数都比它大:

如果i和j没有碰头的话,就递加i找大的,还没有,就再递减j找小的,如此反复,不断循环。注意判断和寻找是同时进行的。
然后,对k两边的数据,再分组分别进行上述的过程,直到不能再分组为止。
注意:第一遍快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边。为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果。
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
def quick_sort(array,left,right):
'''
:param array:
:param left: 列表的第一个索引
:param right: 列表最后一个元素的索引
:return:
'''
if left >=right:
return
low = left
high = right
key = array[low] #第一个值
while low < high:#只要左右未遇见
while low < high and array[high] > key: #找到列表右边比key大的值 为止
high -= 1
#此时直接 把key(array[low]) 跟 比它大的array[high]进行交换
array[low] = array[high]
array[high] = key
while low < high and array[low] <= key : #找到key左边比key大的值,这里为何是<=而不是<呢?你要思考。。。
low += 1
#array[low] =
#找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换
array[high] = array[low]
array[low] = key
quick_sort(array,left,low-1) #最后用同样的方式对分出来的左边的小组进行同上的做法
quick_sort(array,low+1, right)#用同样的方式对分出来的右边的小组进行同上的做法
if __name__ == '__main__':
array = [96,14,10,9,6,99,16,5,1,3,2,4,1,13,26,18,2,45,34,23,1,7,3,22,19,2]
#array = [8,4,1, 14, 6, 2, 3, 9,5, 13, 7,1, 8,10, 12]
print("before sort:", array)
quick_sort(array,0,len(array)-1)
print("-------final -------")
print(array)二叉树
树的特征和定义
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可用树形象表示。树在计算机领域中也得到广泛应用,如在编译源程序时,可用树表示源程序的语法结构。又如在数据库系统中,树型结构也是信息的重要组织形式之一。一切具有层次关系的问题都可用树来描述。
树(Tree)是元素的集合。我们先以比较直观的方式介绍树。下面的数据结构是一个树:
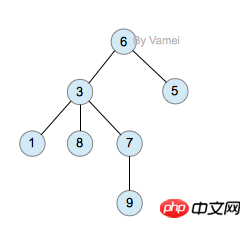
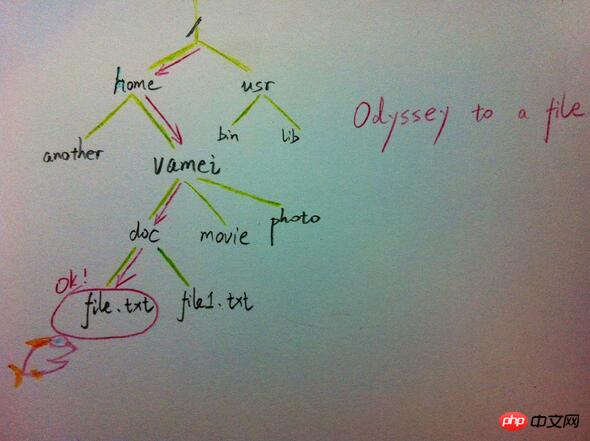
树有多个节点(node),用以储存元素。某些节点之间存在一定的关系,用连线表示,连线称为边(edge)。边的上端节点称为父节点,下端称为子节点。树像是一个不断分叉的树根。
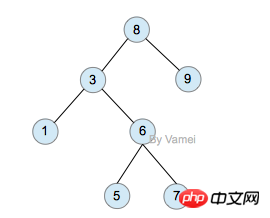
每个节点可以有多个子节点(children),而该节点是相应子节点的父节点(parent)。比如说,3,5是6的子节点,6是3,5的父节点;1,8,7是3的子节点, 3是1,8,7的父节点。树有一个没有父节点的节点,称为根节点(root),如图中的6。没有子节点的节点称为叶节点(leaf),比如图中的1,8,9,5节点。从图中还可以看到,上面的树总共有4个层次,6位于第一层,9位于第四层。树中节点的最大层次被称为深度。也就是说,该树的深度(depth)为4。
如果我们从节点3开始向下看,而忽略其它部分。那么我们看到的是一个以节点3为根节点的树:
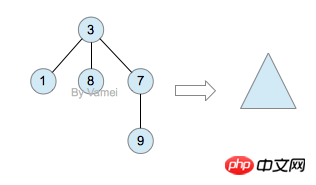
三角形代表一棵树
再进一步,如果我们定义孤立的一个节点也是一棵树的话,原来的树就可以表示为根节点和子树(subtree)的关系:
上述观察实际上给了我们一种严格的定义树的方法:
1. 树是元素的集合。
2. 该集合可以为空。这时树中没有元素,我们称树为空树 (empty tree)。
3. 如果该集合不为空,那么该集合有一个根节点,以及0个或者多个子树。根节点与它的子树的根节点用一个边(edge)相连。
上面的第三点是以递归的方式来定义树,也就是在定义树的过程中使用了树自身(子树)。由于树的递归特征,许多树相关的操作也可以方便的使用递归实现。我们将在后面看到。
树的实现
The schematic diagram of the tree has given a memory implementation of the tree: each node stores elements and multiple pointers to child nodes. However, the number of child nodes is undefined. One parent node may have a large number of child nodes, while another parent node may have only one child node, and the addition and deletion of nodes in the tree will further change the number of child nodes. This uncertainty may lead to a large number of memory-related operations and easily cause a waste of memory.
A classic implementation is as follows:
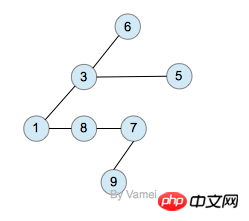
Memory implementation of tree
Two nodes with the same parent node are siblings of each other. In the implementation of the above figure, each node contains a pointer pointing to the first child node, and another pointer pointing to its next sibling node. In this way, we can represent each node with a unified and deterministic structure.
The computer's file system is a tree structure, such as what is introduced in the background knowledge of Linux file management. In the UNIX file system, each file (a folder is also a type of file) can be regarded as a node. Non-folder files are stored in leaf nodes. There are pointers to parent and child nodes in the folder (in UNIX, the folder also contains a pointer to itself, which is different from the tree we saw above). In git, there is a similar tree structure to express version changes of the entire file system (refer to version management of the Three Kingdoms).
Binary tree:
Binary tree is a finite tree composed of n (n≥0) nodes Set, ordered tree with at most two subtrees per node. It is either the empty set or it consists of a root and two disjoint binary trees called left and right subtrees.
Features:
(1) A binary tree is an ordered tree. Even if there is only one subtree, the left and right subtrees must be distinguished;
(2) Each of the binary trees The degree of a node cannot be greater than 2, and can only be one of 0, 1, or 2;
(3) There are 5 forms of all nodes in the binary tree: empty nodes, no left and right subtrees Nodes, nodes with only left subtree, nodes with only right subtree and nodes with left and right subtrees.
Binary tree is a special kind of tree. Each node of the binary tree can only have at most 2 child nodes:
Binary tree
Since the number of child nodes of the binary tree is determined, the above figure can be used directly. Implemented in memory. Each node has a left child node (left children) and a right child node (right children). The left child node is the root node of the left subtree, and the right child node is the root node of the right subtree.
If we add an additional condition to the binary tree, we can get a special binary tree called a binary search tree. Binary search tree requirements: Each node is not smaller than any element of its left subtree, and not larger than any element of its right subtree.
(If we assume that there are no duplicate elements in the tree, then the above requirement can be written as: each node is larger than any node of its left subtree and smaller than any node of its right subtree)
Binary search tree, pay attention to the size of the elements in the tree
Binary search tree can easily implement the search algorithm. When searching for element x, we can compare x with the root node:
1. If x is equal to the root node, then find x and stop the search (termination condition)
2. If x Less than the root node, then search the left subtree
3. If x is greater than the root node, then search the right subtree
The number of operations required for a binary search tree is at most equal to the depth of the tree . The depth of a binary search tree with n nodes is at most n and at least log(n).
Binary tree traversal
Traversal means visiting all the nodes of the tree and only once. According to the location of the root node, it is divided into pre-order traversal, mid-order traversal and post-order traversal.
Pre-order traversal: root node->left subtree->right subtree
In-order traversal: left subtree->root node->right subtree
Post-order traversal: left subtree->right subtree->root node
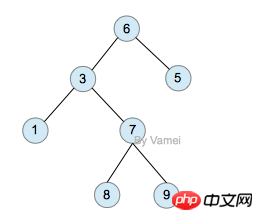
For example: find three traversals of the following tree
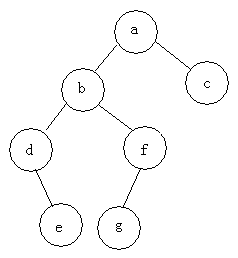
Pre-order traversal: abdefgc
In-order traversal: debgfac
Post-order traversal: edgfbca
Type of binary tree
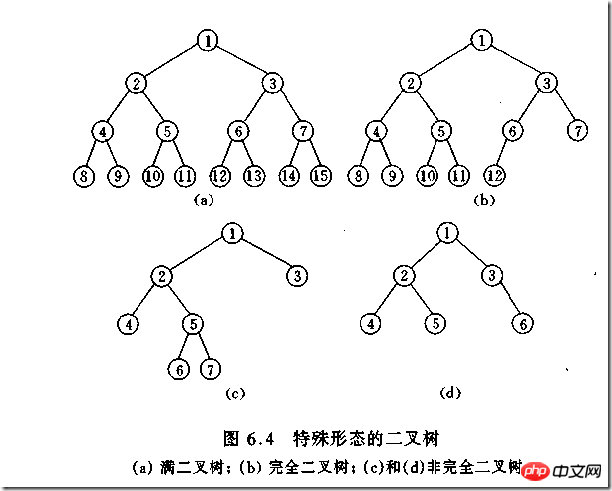
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如何判断一棵树是完全二叉树?按照定义
教材上的说法:一个深度为k,节点个数为 2^k - 1 的二叉树为满二叉树。这个概念很好理解,就是一棵树,深度为k,并且没有空位。
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。
如何判断平衡二叉树?
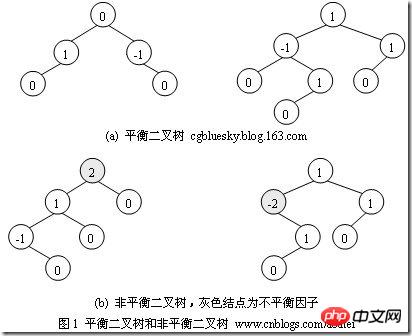
(b)左边的图 左子数的高度为3,右子树的高度为1,相差超过1
(b)右边的图 -2的左子树高度为0 右子树的高度为2,相差超过1
二叉树遍历实现
class TreeNode(object):
def __init__(self,data=0,left=0,right=0):
self.data = data
self.left = left
self.right = right
class BTree(object):
def __init__(self,root=0):
self.root = root
def preOrder(self,treenode):
if treenode is 0:
return
print(treenode.data)
self.preOrder(treenode.left)
self.preOrder(treenode.right)
def inOrder(self,treenode):
if treenode is 0:
return
self.inOrder(treenode.left)
print(treenode.data)
self.inOrder(treenode.right)
def postOrder(self,treenode):
if treenode is 0:
return
self.postOrder(treenode.left)
self.postOrder(treenode.right)
print(treenode.data)
if __name__ == '__main__':
n1 = TreeNode(data=1)
n2 = TreeNode(2,n1,0)
n3 = TreeNode(3)
n4 = TreeNode(4)
n5 = TreeNode(5,n3,n4)
n6 = TreeNode(6,n2,n5)
n7 = TreeNode(7,n6,0)
n8 = TreeNode(8)
root = TreeNode('root',n7,n8)
bt = BTree(root)
print("preOrder".center(50,'-'))
print(bt.preOrder(bt.root))
print("inOrder".center(50,'-'))
print (bt.inOrder(bt.root))
print("postOrder".center(50,'-'))
print (bt.postOrder(bt.root))堆排序
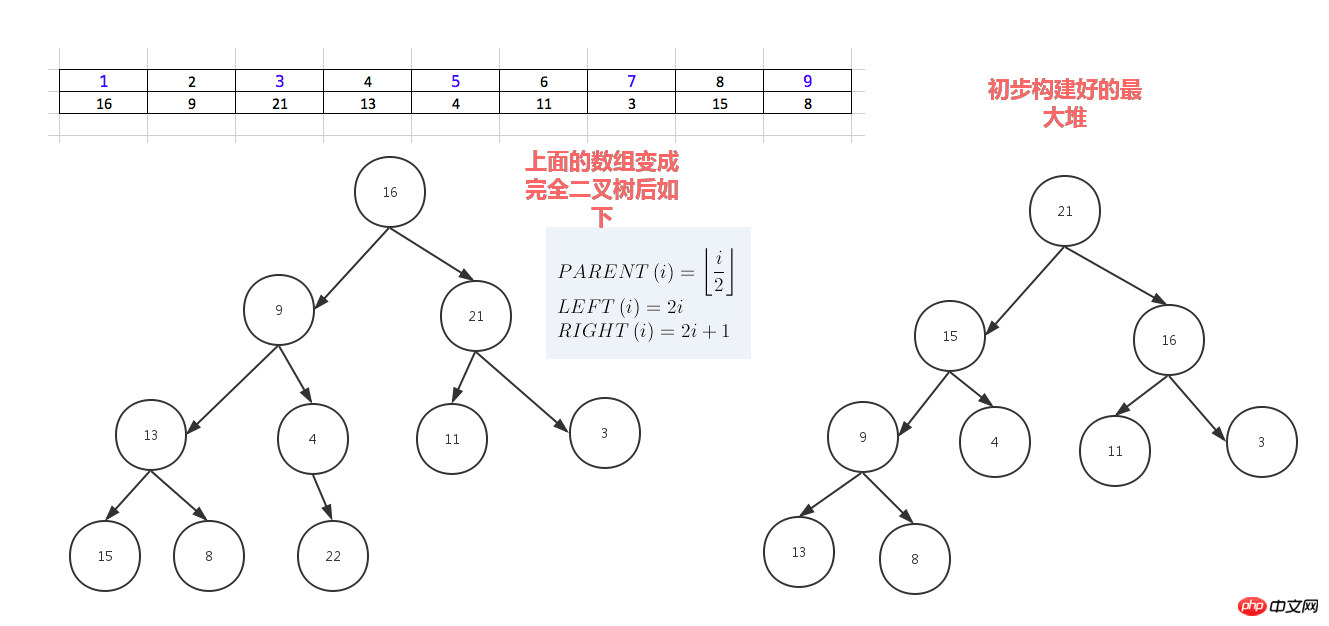
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time,random
def sift_down(arr, node, end):
root = node
#print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root +1 #left child
if child > end:
#print('break',)
break
print("v:",root,arr[root],child,arr[child])
print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边
child += 1 #设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child]= tmp
# 正在调整的节点设置为root
#print("less1:", arr[root],arr[child],root,child)
root = child #
#[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
#print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
#print(arr)
print('-------------')
def heap_sort(arr):
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 -1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
#[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
print('--------end---',arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
#print(arr)
def main():
# [7, 95, 73, 65, 60, 77, 28, 62, 43]
# [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [16,9,21,13,4,11,3,22,8,7,15,27,0]
array = [16,9,21,13,4,11,3,22,8,7,15,29]
#array = []
#for i in range(2,5000):
# #print(i)
# array.append(random.randrange(1,i))
print(array)
start_t = time.time()
heap_sort(array)
end_t = time.time()
print("cost:",end_t -start_t)
print(array)
#print(l)
#heap_sort(l)
#print(l)
if __name__ == "__main__":
main()人类能理解的版本
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22]
for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
#if r_child_index < len(dataset[0:i]): #avoid right out of list index range
#print(left_child)
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
# if p_node < left_child: #switch p_node with left child
# dataset[p_index - 1] , dataset[l_child_index] = left_child,p_node
# # redefine p_node after the switch ,need call this val below
# p_node = dataset[p_index - 1]
#
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
else:
print("p node [%s] has no right child" % p_node)
#最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆
print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)希尔排序(shell sort)
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高
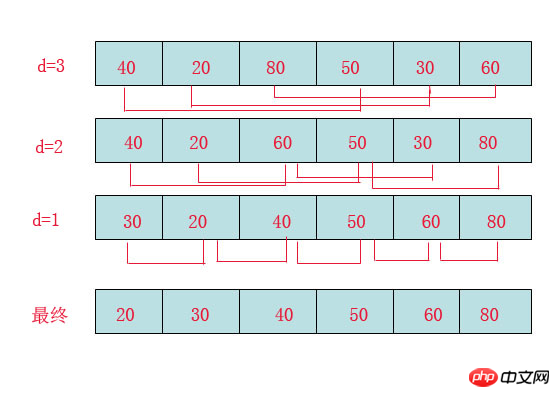
首先要明确一下增量的取法:
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1;
看上图观测的现象为:
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
希尔排序代码
import time,random
#source = [8, 6, 4, 9, 7, 3, 2, -4, 0, -100, 99]
#source = [92, 77, 8,67, 6, 84, 55, 85, 43, 67]
source = [ random.randrange(10000+i) for i in range(10000)]
#print(source)
step = int(len(source)/2) #分组步长
t_start = time.time()
while step >0:
print("---step ---", step)
#对分组数据进行插入排序
for index in range(0,len(source)):
if index + step < len(source):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
if current_val > source[index+step]: #switch
source[index], source[index+step] = source[index+step], source[index]
step = int(step/2)
else: #把基本排序好的数据再进行一次插入排序就好了
for index in range(1, len(source)):
current_val = source[index] # 先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[
position - 1] > current_val: # 当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position - 1] # 把左边的一个元素往右移一位
position -= 1 # 只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val # 已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
t_end = time.time() - t_start
print("cost:",t_end)The above is the detailed content of Basic and commonly used algorithms in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
