

MySQL distributed cluster MyCAT (2) schema code detailed explanation

In the first part, there is a brief introduction to the basic situation of MyCAT construction and configuration files. This article details some specific parameters of the schema and its actual function
Post it first In the schema file used for my own testing, the backslash before the double quotation mark will not be eliminated. Let’s pretend it does not exist...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema># The first line of parameters<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100"/>
In this line of parameters, schema name defines the name of the logical database that can be displayed on the MyCAT front-end,
When the checkSQLschema parameter is False, it indicates that MyCAT will automatically ignore the database name before the table name. For example, mydatabase1.test1 will be regarded as test1;
sqlMaxLimit specifies the limit on the number of rows returned by the SQL statement;
As you can see in the upper right corner, MyCAT itself is cached;
So, if the statement we execute needs to return more data rows, what will MyCAT do without modifying this limit?
# can be seen from the screenshot, mycat does not ignore the actual needs of the front end, 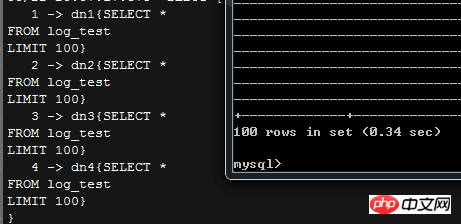
This is honest back 100 pieces of data This #, so if a large amount of data needs to be returned in an actual application, you may have to manually change the logic In version 1.4 of MyCAT, the user’s Limit parameter will overwrite the default MyCAT setting
------------------------------------------------ -------------------------------------------------- -------------------------------------------------- ----------------------------------
#table
name
=
"students" dataNode="dn1,dn2,dn3,dn4" rule="rule1" /> This line represents What table names will be displayed on the MyCAT front-end? Similar lines all represent the same meaning. The emphasis here is on the table, and MyCAT does not define the table structure in the configuration file. If you use show create table on the front-end, MyCAT will display normally. Table structure information, observe the Debug log, It can be seen that MyCAT distributes the command to the database represented by dn1, and then returns the query result of dn1 to the front end
It can be judged that some similar query instructions at the database level may be distributed to a certain node separately. Then return the information of a certain node to the front end; Specific segmentation strategy, currently MyCAT only supports segmentation according to a special column and following some special rules, such as modulo, enumeration, etc. The details will be discussed later
----- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------
name
=
"item_test" primaryKey="ID" type ="global" dataNode="dn1,dn2,dn3,dn4" /> This row represents the global table, which means that the item_test table will save complete data copies in the four dataNodes, then Will the query be distributed to all databases? The query of the table will only be distributed to a certain node -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------I have not actually used childtable in the test, but it is mentioned in the design document of MyCAT that childtable is a structure that depends on the parent table.
This means that the joinkey of the childtable will follow the parentKey strategy of the parent table. Split together, when the parent table and child table are connected, and the connection condition is childtable.joinKey=parenttable.parentKey, cross-database connection will not be performed. -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------
The parameters of dataNode have been introduced in the previous chapter, so skip here~
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
dataHost configures the actual back-end database cluster. Most of the parameters are simple and easy to understand. Here are I will not introduce them one by one. I will only introduce the two more important parameters, writeType and balance. From the
cluster configuration
The test process here is more troublesome, so I will post the conclusion directly:
) 2.bALANCE = 1, read operations will be randomly scattered on LocalHost1 and two Readhost (
LocalHost failed, the writing operation will be in
Localhost1, if If localhost1 fails again, the write operation will not be possible. #localhost1,
localhost1 and two readhosts (same as above) 4. When writeType=0, the write operation will be on localhost. If localhost fails, it will automatically Switch to localhost1. After localhost is restored, it will not switch back to localhost for write operations. On
localhost and localhost1, a single point of failure will not affect the write operation of the cluster. However, the back-end slave library will not be able to obtain updates from the failed main library, and will fail when reading data. Data inconsistency occurs
## , but localhost’s slave library cannot obtain updates from localhost, localhost’s slave library has data inconsistency with other libraries
------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------In fact, MyCAT's own read-write separation is based on the synchronization of the back-end cluster, and MyCAT itself provides the statement distribution function. Of course, The sqlLimit restriction also causes MyCAT to have some impact on the logic of the front-end application layer.
The configuration from schema to table shows that the logical structure of MyCAT itself includes the characteristics of sub-database and sub-table (can be Specify that different tables exist in different databases without having to be divided into all databases)
The above is the detailed content of MySQL distributed cluster MyCAT (2) schema code detailed explanation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
The process of starting MySQL in Docker consists of the following steps: Pull the MySQL image to create and start the container, set the root user password, and map the port verification connection Create the database and the user grants all permissions to the database
 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 How to install mysql in centos7
Apr 14, 2025 pm 08:30 PM
How to install mysql in centos7
Apr 14, 2025 pm 08:30 PM
The key to installing MySQL elegantly is to add the official MySQL repository. The specific steps are as follows: Download the MySQL official GPG key to prevent phishing attacks. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
