

当前位置: 首页 > 爬虫
-

RSS源如何实现内容推荐
要实现RSS内容推荐,需在RSS数据基础上构建智能推荐系统。首先通过feedparser等工具抓取并解析RSS内容,提取标题、摘要、发布时间等信息,并存储到数据库中;对于仅提供片段的源,可结合WebScraping技术获取全文。随后利用NLP技术对内容进行处理,包括分词、去停用词、词干还原等预处理操作,并采用TF-IDF、TextRank提取关键词,使用LDA进行主题建模,或借助Word2Vec、BERT等词嵌入技术生成语义向量,从而构建内容特征向量。同时,收集用户订阅、点击、阅读时长、标签等行
XML/RSS教程 3652025-10-07 17:27:02
-

HTML代码怎么实现服务端渲染_HTML代码服务端渲染原理与实现步骤详解
服务端渲染(SSR)的核心优势在于提升首屏加载速度和SEO表现。服务器在接收到请求后,直接生成含完整内容的HTML并发送给浏览器,用户可快速看到页面,搜索引擎爬虫也能顺利抓取内容。相比客户端渲染(CSR),SSR减少了空白页等待时间,优化了FCP和LCP指标,尤其适用于内容密集型、高SEO要求的网站。主流实现技术包括Next.js、Nuxt.js、SvelteKit及Node.js配合模板引擎等方案,但需应对服务器负载增加、同构代码复杂性、状态同步与缓存策略等挑战。合理评估项目需求,选择合适技术
html教程 4442025-10-07 17:20:02
-

使用 Flask-SQLAlchemy 高效插入爬取数据教程
本教程旨在指导开发者如何将爬取到的数据高效、安全地插入到使用Flask-SQLAlchemy构建的数据库中。文章将详细阐述从传统SQL语句到ORM模型的转变,重点介绍数据模型的定义、在Flask应用上下文中的数据插入操作,以及如何利用会话管理(db.session)和事务控制(commit、rollback)来确保数据一致性与完整性。
Python教程 3952025-10-07 14:35:20
-

Go语言中处理协议相对URL的实践
本文探讨在Go语言中处理缺乏协议(如http:或https:)的URL(即协议相对URL)的方法。在代理或爬虫开发中,这类URL常导致http.Client请求失败。核心解决方案是利用net/url包解析URL,并在检测到缺失协议时,为其指定一个合理的默认协议(如http或https),从而确保能够正确发起网络请求。
Golang 1662025-10-07 14:09:01
-

Go语言中处理缺失协议(Scheme)的URL:实践与解析
在Go语言进行网络编程时,经常会遇到缺少协议(如http:或https:)的URL,例如//www.example.com。本文将深入探讨这类“协议相对URL”的解析机制,并提供一种在Go中通过net/url包检测并动态补充默认协议(如http或https)的有效方法,确保HTTP请求能够正确执行,从而提升网络应用的健壮性。
Golang 5342025-10-07 13:51:29
-

用JS生成HTML是否利于SEO_用JS生成HTML是否利于SEO影响分析
搜索引擎能执行JS但存在延迟与不确定性,导致首屏内容、URL路由和元信息等问题影响SEO,建议采用SSR或预渲染并确保核心内容在初始HTML中以提升可索引性。
html教程 4372025-10-07 10:58:01
-

Prestashop分页隐藏分类描述的SEO考量与处理
本文探讨了Prestashop商店中分类描述在分页后消失的问题。我们解释了这种现象通常并非SEO问题,因为搜索引擎主要关注第一页的描述内容。教程将深入分析此行为背后的SEO逻辑,并提供确保网站SEO友好的最佳实践,强调第一页描述的重要性及规范使用Canonical标签。
php教程 9382025-10-07 09:55:31
-

Go语言中处理无协议(Scheme-less)URL的实践指南
本文探讨了在Go语言中处理无协议(如//example.com)URL的有效方法。当进行网络请求时,这类URL会引发错误。教程详细介绍了如何利用net/url包解析并智能地为这些URL补充默认协议(如HTTP或HTTPS),从而确保net/http客户端能够成功发起请求,特别适用于构建代理或爬虫应用。
Golang 5172025-10-07 09:18:05
-
千帆搜索官网查找入口_千帆搜索引擎最新在线平台
千帆搜索官网入口为https://qianfan.cloud.baidu.com,提供基于AI的自然语言搜索、多模态处理与上下文记忆功能,支持API调用,界面简洁,具备语音输入、图片上传及分类结果展示等特性。
浏览器 3492025-10-06 23:08:02
-

如何使用Golang处理网络超时
使用context和net.Dialer设置超时是Go网络编程核心,通过context.WithTimeout控制请求总时长,结合http.Client的Transport字段精细管理各阶段超时,如连接、TLS握手等,确保应用在异常网络中稳定运行。
Golang 5762025-10-06 15:46:02
-

python如何重写start_requests方法
start_requests方法是Scrapy中用于生成初始请求的默认方法,它基于start_urls创建Request对象;重写该方法可自定义初始请求,如添加headers、cookies、支持POST请求或结合认证逻辑,从而灵活控制爬虫启动行为。
Python教程 5892025-10-06 15:19:02
-

Prestashop分类描述在分页时的显示行为解析与SEO考量
Prestashop商店中,分类描述通常仅在首个分页页面显示,而在后续分页页面上消失,甚至从第二页返回第一页时也可能不显示。这并非一个技术故障,而是Prestashop的默认行为,且从SEO角度看,只要描述在直接访问的第一页可见,就已满足核心要求,无需在所有分页页面重复显示,以避免潜在的重复内容问题。
php教程 2682025-10-06 12:09:12
-
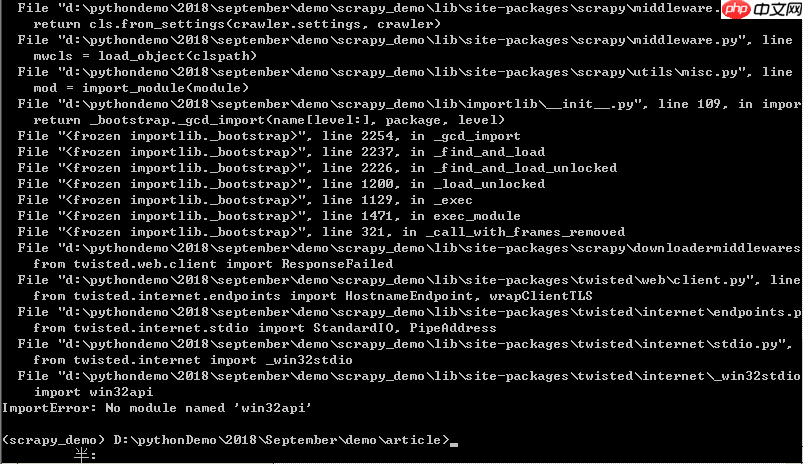
运行Scrapy程序时出现No module named win32api问题的解决思路和方法
在使用Scrapy时,如果遇到“Nomodulenamedwin32api”的错误,许多用户会感到困惑。今天,我们将详细探讨解决这个问题的步骤和方法。出现这个错误的原因是,在Windows系统下缺少一个名为pypiwin32的包。这个错误通常只会在Windows系统上出现。许多用户看到错误信息后,尝试直接通过命令“pipinstallwin32api”进行安装,结果系统会提示如下错误:错误信息显示:“Couldnotfindaversionthatsatisfiestherequ
Windows系列 7132025-10-06 09:37:29
-

海棠书院在线小说网站_海棠书屋2025免费链接
无法通过免费链接合法阅读海棠书屋内容,因其多为盗版且存在风险。应选择起点读书、晋江文学城等正版平台,支持作者并保障安全。
浏览器 7332025-10-05 18:00:03
-

帝国cms怎么设置伪静态URL地址_帝国cms伪静态规则配置与URL优化方法
帝国CMS伪静态设置需后台配置与服务器规则协同完成。首先在后台“系统参数设置”中启用动态页面,栏目设置中选择“不生成HTML”并启用动态页,再通过“数据更新中心”更新信息页地址。随后在“伪静态参数设置”中定义URL格式,如内容页/info-[!dbtype!]-[!classid!]-[!id!].html、列表页/list-[!classid!]-[!page!].html等。接着根据服务器环境配置伪静态规则:Apache环境下在.htaccess中添加RewriteRule规则,Nginx环
帝国CMS 9842025-10-05 14:54:03
-

Scrapy 图片提取教程:利用 XPath 精准定位产品图片链接
本教程深入探讨在Scrapy框架中高效、精准地提取网页产品图片链接的方法。针对传统CSS选择器可能失效的复杂HTML结构,我们将详细介绍如何利用XPath表达式,特别是contains()函数,实现更鲁棒的图片URL抓取。文章包含示例代码、XPath解析及关键注意事项,旨在帮助开发者克服图片抓取难题。
html教程 2892025-10-05 12:19:23
社区问答
-

vue3+tp6怎么加入微信公众号啊
阅读:5015 · 6个月前
-

老师好,当客户登录并立即发送消息,这时候客服又并不在线,这时候发消息会因为touid没有赋值而报错,怎么处理?
阅读:6054 · 7个月前
-
RPC模式
阅读:5029 · 7个月前
-
insert时,如何避免重复注册?
阅读:5841 · 9个月前
-
vite 启动项目报错 不管用yarn 还是cnpm
阅读:6436 · 10个月前















最新文章
-
谷歌邮箱被停用怎么办 Gmail账号封禁与恢复处理方法
阅读:609 · 26分钟前
-
谷歌邮箱怎么收验证码 Gmail验证码收不到的原因与解决
阅读:528 · 26分钟前
-
PHP中加HTML_PHP文件内添加HTML代码指南
阅读:518 · 26分钟前
-
新浪邮箱官网登录地址入口_新浪邮箱官方网站主页链接地址
阅读:449 · 26分钟前
-
如何确保NeosCMS用户界面始终最新且高效运行,Composer助你轻松管理前端依赖
阅读:409 · 26分钟前
-
谷歌邮箱怎么解除封禁 Gmail安全策略与解封申诉步骤
阅读:421 · 26分钟前
-
抓大鹅小游戏在线玩免费 小游戏免费秒玩入口抓大鹅的游戏
阅读:910 · 27分钟前
-
Safari浏览器下载文件没有反应怎么办 Safari浏览器文件下载修复教程
阅读:883 · 27分钟前
-
千牛网页版卖家工作台网址_千牛网页官方客服服务平台入口
阅读:754 · 27分钟前
-
系列第二差!新模式致《战地6》steam差评数量激增
阅读:735 · 28分钟前



