

-
- XML的xmlns:xlink命名空间声明有什么特殊含义?
- XML的xmlns:xlink命名空间声明用于启用XLink规范中的高级链接功能,1.它通过声明xmlns:xlink="http://www.w3.org/1999/xlink"使XML文档能使用XLink属性;2.XLink支持简单、扩展和定位器链接类型,提供比HTML更丰富的链接语义;3.支持单向和双向链接,并可指定xlink:show和xlink:actuate等行为控制链接激活与展示方式;4.允许链接外部资源并嵌入内容,适用于文档管理、知识库等复杂场景;5.尽管现代Web多用JavaS
- XML/RSS教程 . 后端开发 922 2025-08-06 18:47:01
-

- 如何在COBOL中使用XML PARSE语句解析文档?
- 要使用COBOL的XMLPARSE语句解析XML文档,需1.定义XML事件处理程序以响应解析事件;2.定义与XML结构匹配的COBOL数据结构;3.使用XMLPARSE语句启动解析并指定处理程序;4.在事件处理程序中根据XML-EVENT类型(如START-ELEMENT、CHARACTERS)将数据移入对应字段;5.通过XML-ATTRIBUTE-NAME和XML-ATTRIBUTE-VALUE处理元素属性;6.使用ONEXCEPTION子句捕获错误并结合XML-CODE进行错误处理;7.通过
- XML/RSS教程 . 后端开发 932 2025-08-06 18:46:01
-
- 如何在Elixir中使用SweetXml库提取XML数据?
- 添加SweetXml依赖并解析XML字符串;2.使用SweetXml.xpath/2或xpath/3结合XPath表达式提取数据,支持文本、属性及结构化信息提取;3.通过命名空间映射处理带命名空间的XML;4.利用返回值为nil或空列表的特性进行错误处理,无需异常捕获;5.基于xmerl的稳定性适合大多数场景,超大文件需考虑流式解析器。SweetXml凭借XPath集成、简洁API和Elixir化设计,在XML数据提取中表现出色,是Elixir中处理XML的首选工具。
- XML/RSS教程 . 后端开发 732 2025-08-06 18:30:02
-

- 如何在VB.NET中使用LINQ to XML查询XML数据?
- LINQtoXML的核心组件包括XDocument、XElement、XAttribute、XName和XNamespace,1.XDocument是XML文档的根容器,代表整个文档结构;2.XElement表示XML元素,用于访问和操作节点及其内容;3.XAttribute代表元素的属性,可通过@符号访问;4.XName表示带命名空间的XML名称;5.XNamespace用于定义和处理命名空间URI;在查询带命名空间的XML时,必须先将命名空间URI声明为XNamespace变量,并在查询中与
- XML/RSS教程 . 后端开发 977 2025-08-06 18:10:02
-

- XML的VTD-XML解析技术相比DOM有什么优势?
- VTD-XML相比DOM最大的优势在于速度和内存占用,1.速度快:VTD-XML通过索引直接访问元素,避免构建完整DOM树,解析速度远超DOM;2.内存占用少:仅加载必要数据,显著降低内存消耗,适合处理大型XML文件;3.支持XPath:利用索引机制实现快速XPath查询,并通过缓存优化进一步提升性能;4.可更新性:支持在不重新解析的情况下修改文档内容;在处理大型XML文件时,VTD-XML性能优于DOM和SAX,尤其适合内存受限且需高效查询的场景。
- XML/RSS教程 . 后端开发 1028 2025-08-06 18:08:01
-

- 如何在Julia中使用LightXML库读写XML?
- 首先安装LightXML库:使用Pkg.add("LightXML")安装;2.读取XML文件:用parse_file读取文件并获取根节点;3.访问节点:通过get_elements_by_tagname或first_element等函数获取元素、属性和文本内容;4.修改节点:使用content或set_attribute修改元素内容或属性;5.创建文档:使用XMLDocument、create_element、set_attribute、add_child和add_text逐步构建新文档;6.
- XML/RSS教程 . 后端开发 783 2025-08-06 18:07:01
-
- 如何在TypeScript中安全地解析来自网络的XML?
- 选择合适的XML解析库需综合考虑性能、安全性、易用性和TypeScript支持,1.若注重易用性和类型支持,可选xml2js;2.若追求高性能且能接受更多配置,可选fast-xml-parser;3.若需底层控制,可选xmldom但需手动处理更多细节;安全性方面应确保库能防范XXE等漏洞。定义XML类型时,需根据XML结构手动创建TypeScript接口,如单个对象使用interfaceBook{title:string;author:string;price:number;},数组结构则定义为
- XML/RSS教程 . 后端开发 758 2025-08-05 18:22:01
-

- XML的xml:id属性有什么特殊用途?解析时要注意什么?
- xml:id属性为XML元素提供无需外部定义的全局唯一标识,1.它是XML规范内置机制,无需DTD或Schema声明即可被解析器识别;2.其值必须符合NCName格式且在整个文档中唯一;3.不同解析器对xml:id处理有差异,DOM可直接查找而SAX需手动维护映射;4.主要用于文档内交叉引用、XInclude片段包含、程序化快速定位元素及数据交换中的稳定性保障;5.使用时需注意唯一性校验、格式合法性及错误处理,确保数据完整性。
- XML/RSS教程 . 后端开发 912 2025-08-05 18:20:02
-

- XML Schema中的any和anyAttribute元素起什么作用?
- any元素允许在XMLSchema中定义可扩展的子元素,通过namespace属性指定允许的命名空间范围,如##any(任何命名空间)、##other(除目标命名空间外)、##targetNamespace(仅目标命名空间)、##local(无命名空间)或命名空间列表;2.processContents属性控制验证行为,strict表示必须严格验证,lax表示有Schema则验证否则忽略,skip表示完全跳过验证;3.anyAttribute元素作用于属性层面,允许元素包含未预先定义的属性,其n
- XML/RSS教程 . 后端开发 521 2025-08-05 16:57:01
-
- 如何在Groovy中使用XmlSlurper处理XML数据?
- XmlSlurper通过惰性解析和GPath表达式提供高效、简洁的XML读取与查询能力,特别适合处理大型XML文件和只读场景;1.使用parseText()或parse(InputStream)解析XML,优先选择流式解析以降低内存消耗;2.像访问对象属性一样通过节点名和.@attribute访问元素和属性;3.利用each遍历节点避免collect导致的内存溢出;4.使用findAll和find实现条件查询;5.通过declareNamespace声明命名空间前缀与URI的映射,再使用'pre
- XML/RSS教程 . 后端开发 272 2025-08-05 15:09:01
-

- XML的xml-stylesheet处理指令有什么作用?
- xml-stylesheet处理指令通过type和href属性指定样式类型和位置,1.type属性定义样式表类型,如text/css用于CSS样式,text/xsl用于XSLT转换;2.href属性提供样式表文件的URL路径,支持相对或绝对地址;3.可选属性包括media指定媒体类型,charset声明字符编码,alternate和title支持多样式表切换;浏览器解析XML时会先读取该指令,根据type判断样式表类型,通过href下载对应文件,若为CSS则直接应用样式渲染,若为XSLT则执行转
- XML/RSS教程 . 后端开发 976 2025-08-04 23:21:01
-
- XML的Relax NG与XML Schema相比有哪些特点?
- RelaxNG与XMLSchema的核心区别在于:1.RelaxNG追求简洁、灵活,擅长描述无序和交错内容,语法直观易读,尤其适合结构松散或变化频繁的XML;2.XMLSchema提供丰富的数据类型系统和严格的验证能力,支持复杂的数据约束、派生类型及ID/IDREF引用完整性,适用于对数据精度和一致性要求高的场景;3.RelaxNG在处理无序和交错结构时更自然,使用interleave等操作符可轻松表达任意顺序的子元素组合,而XMLSchema实现类似功能受限且复杂;4.XMLSchema具备强
- XML/RSS教程 . 后端开发 851 2025-08-04 21:41:01
-
- XML的xml:space属性如何影响空白字符解析?
- XML中空白字符的默认行为是可被解析器删除或规范化;1.xml:space="default"时,解析器可移除前导尾随空白、合并连续空白、删除纯空白文本节点;2.xml:space="preserve"时,解析器必须保留所有空白字符,适用于代码、诗歌、日志等需保持格式的场景;3.该属性具有继承性,父元素设置后子元素默认继承;4.常见陷阱包括:解析器虽保留空白但后续处理环节(如XSLT)可能仍会移除、混合内容中标签间空白可能被视为可忽略、滥用preserve影响性能、将格式化空白误认为语义数据。因
- XML/RSS教程 . 后端开发 492 2025-08-04 20:21:01
-
- XML的DOM解析内存占用过高有什么优化方案?
- 当XML文件过大时,DOM解析会因将整个文档加载为对象树而导致内存占用过高;2.若只需顺序读取或提取部分数据,应改用SAX或StAX等流式解析方式以降低内存消耗;3.若必须使用DOM,可通过解析后释放无关节点、使用XPath精准查询、避免调用normalize()、禁用DTD/Schema验证及分块处理等方式优化内存使用;4.选择解析策略应综合考虑文件大小、访问模式、开发复杂度和语言生态,优先在小文件或需随机访问时用DOM,大文件或顺序处理时用流式解析。
- XML/RSS教程 . 后端开发 506 2025-08-04 19:41:01
-
- XML的XForms技术现在还适用吗?怎么解析这类文档?
- XForms的设计初衷是实现数据模型与用户界面的分离,通过声明式XML定义表单逻辑、验证规则和交互行为,预示了现代MVVM/MVC模式的理念;2.它未能成为主流的核心原因是缺乏浏览器原生支持,需依赖插件或特定处理器,违背了Web开放性趋势,同时AJAX和HTML5的兴起提供了更灵活、易用且原生支持的技术方案,加之其学习曲线陡峭、生态系统薄弱,导致开发者转向现代JavaScript框架;3.从XForms迁移到现代技术栈的主要挑战包括:将XML数据模型转换为JSON并重构绑定逻辑,重写基于XPat
- XML/RSS教程 . 后端开发 231 2025-08-04 18:39:01

PHP讨论组
组员:3305人话题:1500
PHP一种被广泛应用的开放源代码的多用途脚本语言,和其他技术相比,php本身开源免费; 可以将程序嵌入于HTML中去执行, 执行效率比完全生成htmL标记的CGI要高许多,它运行在服务器端,消耗的系统资源相当少,具有跨平台强、效率高的特性,而且php支持几乎所有流行的数据库以及操作系统,最重要的是








工具推荐





小巧美观企业全站系统修正版
小巧美观企业全站系统 修正说明:修正了technic.asp、product.asp、guestbook.asp三个文件的已知错误,新增了pass.asp密码设置文件 管理员地址:admin.asp 管理员ID:admin 管理员密码:123
企业站源码
2025-10-28

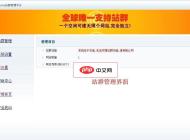
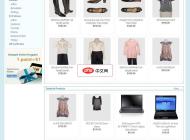
多瑞(doreesoft)外贸网店系统
多瑞外贸网店系统立足于全球化贸易往来的一款外贸类企业用户高端应用电子商务系统软件,帮助企业快速搭建网聚全球商机的电子商务系统。本系统使用纯正的英文,国外用户更容易阅读;多年专业外贸设计经验,熟练掌握美式英语,更符合国外用户考虑和解决问题的逻辑;设计风格、用户体验符合国外用户的习惯;简洁明了的设计风格正是欧美用户的所爱,时时推出新模板、紧跟时尚潮流,供您选择。新增加淘宝数据自动导入,批量上传商品,商品采集等新功能;会员中心、站点栏目的后台编辑功能,以及和进销存软件无缝对接;2.0.1版开始,支持多瑞网店助
电商源码
2025-10-28




生日快乐主题元素PSD分层素材下载
生日快乐主题元素PSD分层素材适用于生日主题元素设计 本作品提供生日快乐主题元素PSD分层素材的图片会员免费下载,格式为PSD,文件大小为2.6M; 请使用软件Photoshop进行编辑,作品中文字及图均可以通过软件修改和编辑;
psd素材
2025-10-28

驾照考试驾校HTML5网站模板
驾照考试驾校HTML5网站模板是一款适合提供驾驶培训和组织驾照考试服务机构宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-06-10

驾照培训服务机构宣传网站模板
驾照培训服务机构宣传网站模板是一款适合提供一般驾驶和计划培训的驾校宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-07


HTML5房地产公司宣传网站模板
HTML5房地产公司宣传网站模板是一款适合从事房地产服务行业宣传网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
前端模板
2025-01-06






