扫码关注官方订阅号
小伙看你根骨奇佳,潜力无限,来学PHP伐。
我用python也测试过,也是一轮就聚类完成,也有可能是因为数据集给得不全,数据集就几十条所以只有一轮(更新):这可以和算法中随机选择质心的算法有关,因为不同的质心对最终迭代次数有影响,就像题主说的达到局部最优解下面是可以循环三次
循环六次的:
算法核心部分:
def k_means(data_set, k, distE=distEclud, createCent=rand_cent): """ data_set: 数据集 data_set = [[1.658985, 4.285136], [-3.453687, 3.424321], [4.838138, -1.151539],[-5.379713, -3.362104], [0.972564, 2.924086]] k: 设置聚类簇数K值 distE:函数, 计算数据点的欧式距离 例如:vector1 = [[ 1.658985 4.285136]] vector2 = [[-3.453687 3.424321]] 欧氏距离:distance = distE(vector1, vector2) createCent: 函数, 返回一个随机的质点矩阵 """ m = shape(data_set)[0] # 获取行数 clusterAssment = mat(zeros((m, 2))) # 初始化一个矩阵, 用来记录簇索引和存储误差平方和(指当前点到簇质点的距离) centroids = rand_cent(data_set, k) # 随机生成一个质心矩阵蔟 clusterChanged = True print('开始') while clusterChanged: clusterChanged = False for i in range(m): # 对每个数据点寻找最近的质心 min_dist = inf # 设置最小距离为正无穷大 min_index = -1 for j in range(k): # 遍历质心簇,寻找最近质心 dist_J = distEclud(centroids[j, :], data_set[i, :]) if dist_J < min_dist: min_dist = dist_J min_index = j if clusterAssment[i, 0] != min_index: clusterChanged = True clusterAssment[i, :] = min_index, min_dist ** 2 # 平方的意义在于判断聚类结果的好坏 print(centroids) print('==================') for cent in range(k): # 更新质心,将每个簇中的点的均值作为质心 index_all = clusterAssment[:, 0].A # 取出样本所属簇的索引值 value = nonzero(index_all == cent) # 取出所有属于第cent个簇的索引值 sampleInClust = data_set[value[0]] # 取出属于第I个簇的所有样本点 centroids[cent, :] = mean(sampleInClust, axis=0) return centroids, clusterAssment
因为初始点的选择是随机的,当然可能聚类过程不完全一样了
微信扫码关注PHP中文网服务号
QQ扫码加入技术交流群
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号
PHP学习
技术支持
返回顶部



 0
0  2
2 842
842



















我用python也测试过,也是一轮就聚类完成,也有可能是因为数据集给得不全,数据集就几十条所以只有一轮
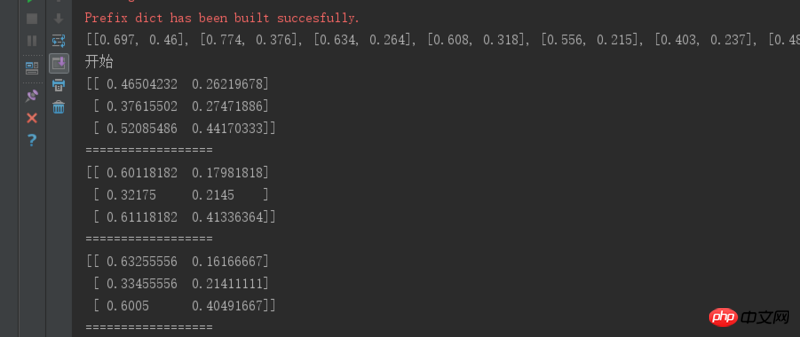
(更新):
这可以和算法中随机选择质心的算法有关,因为不同的质心对最终迭代次数有影响,就像题主说的达到局部最优解
下面是可以循环三次
循环六次的:
算法核心部分:
因为初始点的选择是随机的,当然可能聚类过程不完全一样了