扫码关注官方订阅号
认证高级PHP讲师
"User-Agent": "Mozilla/5.0 (windows 6.0)"
python3
import urllib.request url = "http://www.qiushibaike.com/8hr/page/1" headers = { #"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)" "User-Agent": "Mozilla/5.0 (windows 6.0)" } request = urllib.request.Request(url, headers=headers) response = urllib.request.urlopen(request) c = response.read() h = c.decode('utf-8') print(h)
python3 不需要转码
微信扫码关注PHP中文网服务号
QQ扫码加入技术交流群
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号
PHP学习
技术支持
返回顶部



 0
0  2
2 557
557



















"User-Agent": "Mozilla/5.0 (windows 6.0)"python3
python3 不需要转码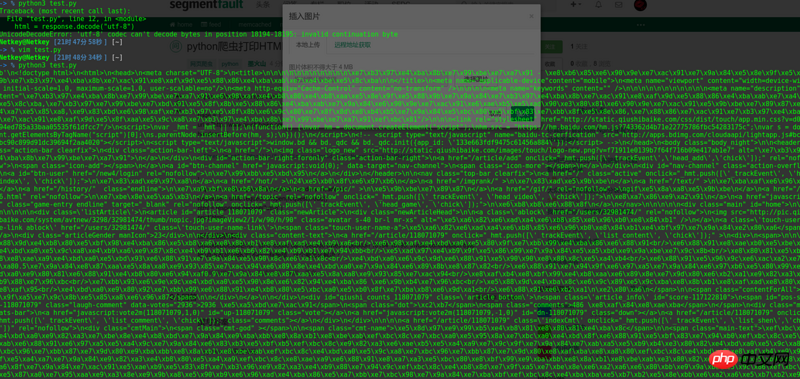
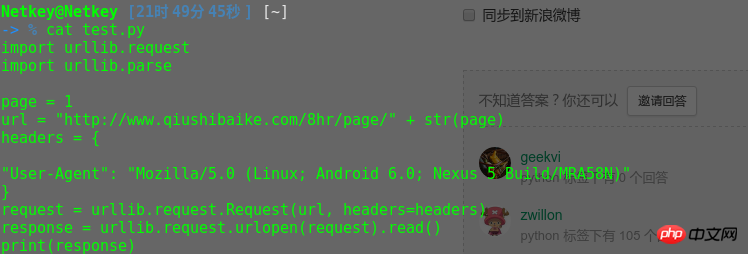
我又尝试了以下。发现response.decode('UTF-8')就可以。是的大写!!!