
代码:
from bs4 import BeautifulSoup
import requests
import json
import sys
import re
reload(sys)
import urllib2
sys.setdefaultencoding('utf8')
downUrl = r'https://www.youtube.com/playlist?list=PLQqbdnAgoRmag4RdUZAKl8Vz0H70T0wDA'
youtubeUrl = r'https://www.youtube.com'
myText = requests.get(downUrl,verify=False).text
print myText
print "======================="
mySoup = BeautifulSoup(myText,'lxml')
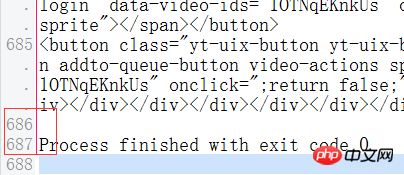
print mySoup为何myText和mySoup打印出来的内容是不同的,相对于myText,mySoup少了好多的。
myText得到
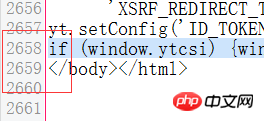
mySoup得到



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 3
3 588
588

















没有少很多吧, 你输出一下,差不多
BeautifulSoup解析后输出的文本是会对原文进行一定的重新排列的。 比如添加或删除一些空白类符号,属性的位置重排,等等。比如你看到行数的差别,是换行被BeautifulSoup解析后优化掉了。 你可以认真对比一下两个的具体内容,应该是是没有差别的。
因为mySoup是经过了解析的,不能简单的和原始数据进行这么简单粗暴的比较~