扫码关注官方订阅号
只想提取下一页上的href啊!
业精于勤,荒于嬉;行成于思,毁于随。
这个很明显了吧,下一页是list_1_2.html,最后一页是list_1_117.html中间页数是3到116啊用一个for循环
for page in range(1, 118): url = "..list_1_{}.html".format(page) ....
希望对你有帮助:http://imchenkun.com/archives/6/ (不是广告,只是提供一个思路)
我简单说一下
ul = soup.find('p',attr={'class':'page'}).ul
lis = ul.find_all('li')
next = lis[-2]['href'] 因为下一页在倒数第二个,直接[-2],得到href属性即可爬虫写的不多,函数可能用的不对,但大致思路差不多。
next = lis[-2]['href']
获取下一页的html,然后请求下一页就可以了
微信扫码关注PHP中文网服务号
QQ扫码加入技术交流群
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号
PHP学习
技术支持
返回顶部



 0
0  4
4 514
514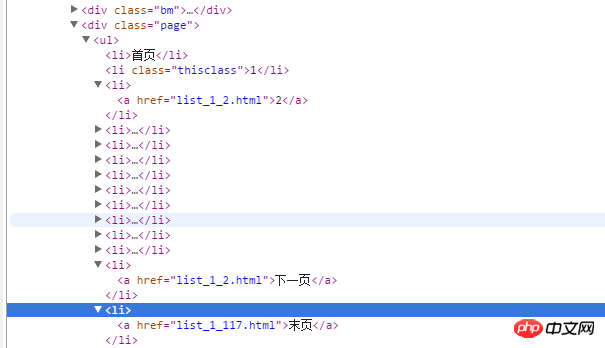




















这个很明显了吧,
下一页是list_1_2.html,最后一页是list_1_117.html
中间页数是3到116啊
用一个for循环
希望对你有帮助:http://imchenkun.com/archives/6/ (不是广告,只是提供一个思路)
我简单说一下
ul = soup.find('p',attr={'class':'page'}).ullis = ul.find_all('li')next = lis[-2]['href']因为下一页在倒数第二个,直接[-2],得到href属性即可爬虫写的不多,函数可能用的不对,但大致思路差不多。
获取下一页的html,然后请求下一页就可以了